关键词:手部关键点,手语识别、LSTM、实时检测
一、引言
自大流行爆发以来,电子学习(e-learning)的使用呈现急剧增长态势。据预测,到 2026 年,电子学习行业规模将至少达到 4000 亿美元。随着这一新兴教育模式的蓬勃发展,确保所有儿童都能跟上教育步伐,不被落下,成为至关重要的议题。然而,对于患有听力损失残疾的儿童而言,其在获取屏幕上的讲座内容时面临着显著障碍,处于相对不利地位。此外,那些无法说话的听力障碍儿童,由于难以依据讲师的回应进行交流,其学习过程也受到极大限制。
为了使这些特殊儿童能够顺利接受教育,美国手语(ASL)应运而生,其意义不仅局限于助力他们获取教育知识,更在于为他们的日常生活提供便利。鉴于此,本研究提出了一种基于深度学习的实时手语检测模型,旨在帮助学生通过摄像头做出 ASL 手势,并借助摄像头识别手势,进而为学生提供关于所识别语言的反馈。在技术实现方面,本研究采用 OpenCV 和 Mediapipe Holistic 来精准识别姿势的关键标记以及收集相关数据,随后依据长短期记忆(LSTM)架构进行模型训练。
本研究的实时手语检测项目,以 LSTM 神经网络架构为核心,致力于从视频源中高效学习并精准分类手语手势,从而实现实时识别与解释手语手势的功能。该系统通过用户友好的界面设计,使用户能够在摄像头前执行手语手势,系统随即快速检测并解释这些手势,可作为听力障碍人士实现有效沟通的有力辅助技术。该系统的主要功能涵盖实时手势检测、高识别准确性以及添加和训练新手语手势的能力。系统构建基于 Python、TensorFlow、OpenCV 和 Numpy 等技术,具备良好的可访问性和可定制性。通过本研究的实时手语检测项目,我们期望能够有效弥合沟通鸿沟,为听力障碍者赋能,助力其更好地融入社会与教育环境。
2.1 程序的初始步骤及关键点识别
在本项目中,程序的首要步骤是精准识别用户身体的关键点。为此,本研究采用了由 Mediapipe 提供的 MP Holistic API。该 API 是一种先进的工具,能够通过识别整体关键点来准确定位人体的各个部位。

上述代码片段中,第一行代码调用了 Holistic API,用于实现关键点的识别功能;第二行代码则调用了 drawing_utils 工具,用于在图像上绘制识别出的关键点。draw_landmarks(image, results):此函数用于在用户图像上绘制识别出的关键点,以便直观展示关键点的位置。draw_styled_landmarks(image, results):通过添加几行额外代码,该函数能够对关键点进行颜色编码。这种颜色编码方式有助于观众更清晰地识别和区分人体的不同部位,从而增强视觉效果


图1 关键点进行颜色编码,以便查看者识别人体的不同部分
2.2 关键点数据的收集与存储
在定义 Mediapipe 模型后,为了后续的模型训练,必须对识别出的关键点进行收集并妥善存储。为此,本研究设计了以下函数:

该函数的作用是从视频流中提取关键点数据,并将这些关键点的坐标值整合为一个 NumPy 数组。通过这种方式,能够高效地组织和存储关键点数据,便于后续的处理与分析。
在数据收集过程中,本研究选取了三个基础手语词汇:“Hello”(你好)、“Thanks”(感谢)和“I Love You”(我爱你)。为了确保数据的多样性和丰富性,用户针对每个词汇分别摆出姿势,每个词汇采集 30 个序列,每个序列包含 30 帧图像,从而总共收集到 90 个序列的数据。
这些识别出的关键点数据被存储在名为 MP_Data 的文件夹中,每个序列的数据均以 .npy 格式保存在其对应的子文件夹内。这种存储方式不仅便于数据的管理和检索,也有利于后续模型训练过程中的数据加载与处理。通过这种方式,能够确保数据的完整性和可用性,为构建高效准确的手语识别模型奠定坚实的数据基础。
图2 关键点数据收集
2.3 训练长短期记忆网络LSTM
为了实现高效且准确的手语手势识别,本研究选择了一个基于长短期记忆(LSTM)的深度学习模型架构。具体而言,所选用的模型为 Sequential 模型,其结构包括 3 个 LSTM 层和 2 个密集层。这种架构设计旨在充分利用 LSTM 的时间序列建模能力,同时通过密集层进行高效的特征提取和分类。
由于手语手势识别属于多分类问题,因此模型的编译配置如下:

优化器:选用 Adam 优化器,其自适应学习率的特性能够有效加速模型的收敛过程。
损失函数:采用 categorical_crossentropy,适用于多分类问题,能够衡量模型输出与真实标签之间的差异。
评估指标:使用 categorical_accuracy,以直观反映模型在分类任务中的准确率。
为了确保模型能够充分学习数据中的特征并达到良好的泛化能力,模型在 2000 个训练周期(epoch)上进行训练。这一训练过程旨在通过大量的迭代优化,使模型能够精准地识别和分类各种手语手势,从而为实时手语检测系统提供强大的技术支持。

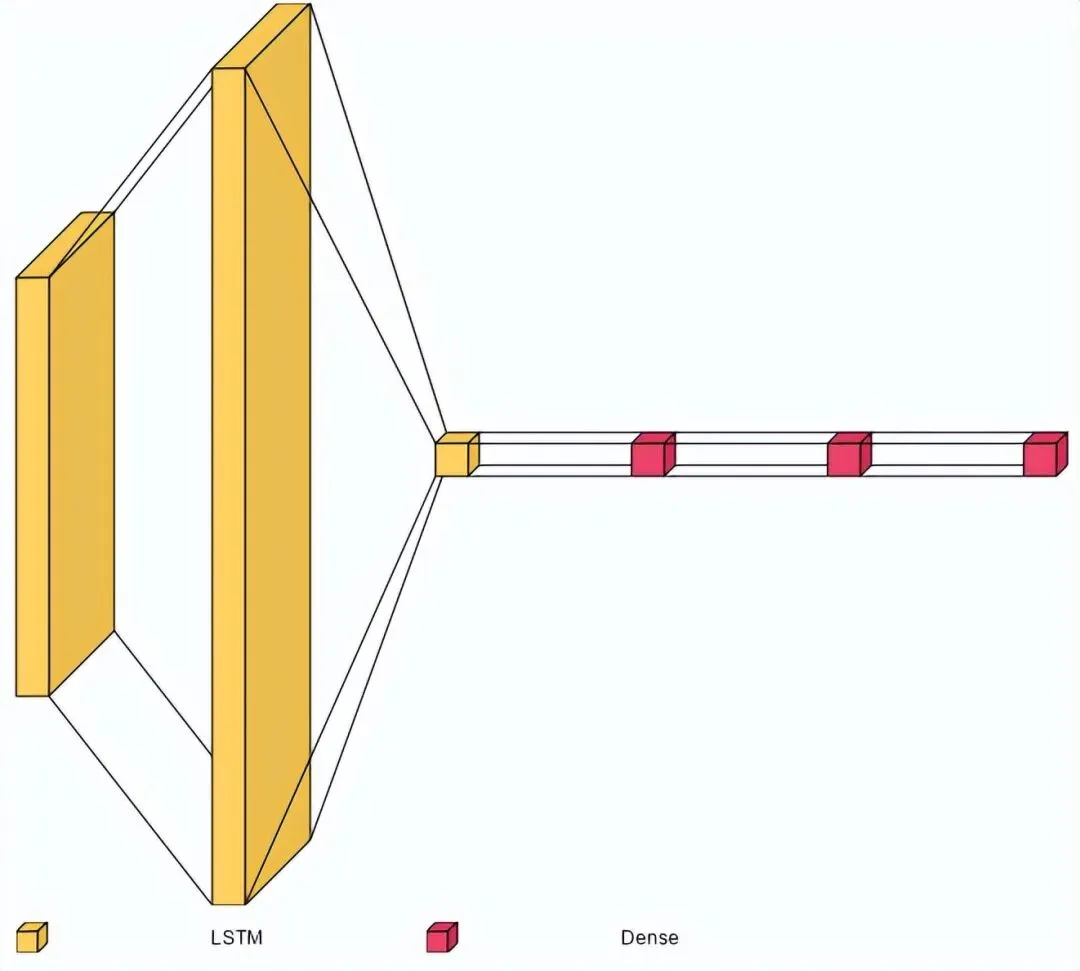
图3 LSTM网络
2.4 系统功能与优势
本研究开发的实时手语检测系统具备以下核心功能与显著优势:
实时性:系统能够实时检测和解释手语手势,为用户提供即时结果,确保沟通的流畅性与高效性。
高准确率:基于长短期记忆(LSTM)神经网络架构的模型,能够精准识别各种复杂的手语手势,显著提升了识别的准确率。
多手势支持:系统支持多种手语手势的识别与解释,涵盖了丰富的手语词汇,从而实现有效的沟通。
易于集成:项目提供了详细的代码片段和示例,便于开发者将该系统无缝集成到其他应用程序或项目中,具有良好的扩展性。
辅助功能改进:通过“使用 LSTM 模型进行实时手语检测”项目,能够显著增强聋人和听力障碍社区的通信辅助功能,为他们提供更便捷的交流工具。
自定义选项:系统支持用户根据自身特定需求添加和训练新手语手势,提供了高度的自定义灵活性。
语言灵活性:该模型具备跨语言的适应性,可以被训练为识别来自不同语言的手语手势,适用于多种语言环境下的沟通需求。
用户友好的界面:项目配备了一个直观且易于操作的用户界面,简化了用户与系统的交互过程,确保了流畅的用户体验。
开源性:作为开源项目,使用 LSTM 模型进行实时手语检测旨在鼓励全球开发者社区的广泛参与和贡献,促进技术的持续改进与创新。
这些是使用 MP Holistic 在 LSTM 架构上训练数据后,项目实时的测试结果。此外,设计颜色编码概率查看器,这是一个概率条,显示测试中识别最多的手势。条形会随着它最能识别的手势而上升。每个条形的颜色如下所示:蓝色/Hello;绿色/感谢;橙子/我爱你。


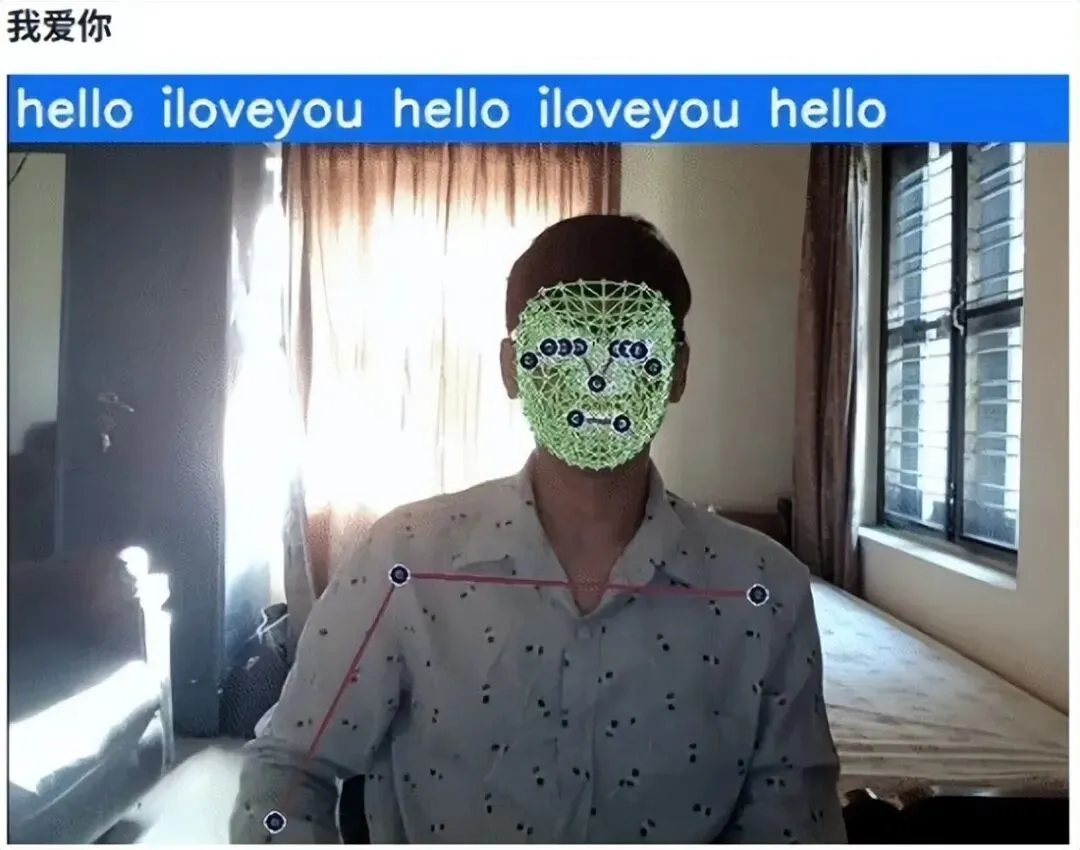
图3 实时检测结果
最后,欢迎大家与我们联络。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
