TM小哥和FH小妹在牛客大学若干年后成立了牛客SQL班,班上每个人的综合成绩用A,B,C,D,E表示,90分以上都是A,80~90分都是B,70~80分为C,60~70为D,E为60分以下。
假设每个名次最多1个人,比如有2个A,那么必定有1个A是第1名,有1个A是第2名(综合成绩同分也会按照某一门的成绩分先后)。
每次SQL考试完之后,老师会将班级成绩表展示给同学看。
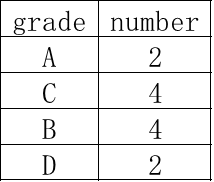
现在有班级成绩表(class_grade)如下:
第1行表示成绩为A的学生有2个
第2行表示成绩为C的学生有4个
依此类推.......
1.2 查询需求
老师想知道学生们综合成绩的中位数是什么档位,请你写SQL帮忙查询一下,如果只有1个中位数,输出1个,如果有2个中位数,按grade升序输出,以上例子查询结果如下:
总体学生成绩排序如下:A, A, B, B, B, B, C, C, C, C, D, D,总共12个数,取中间的2个,取6,7为:B,C。1.4 SQL脚本
WITH cumulative AS ( SELECT grade, SUM(number) OVER (ORDER BY grade) AS running_sum, SUM(number) OVER() AS total FROM class_grade),positions AS ( SELECT grade, COALESCE(LAG(running_sum) OVER (ORDER BY grade), 0) + 1 AS start_pos, running_sum AS end_pos, total FROM cumulative)SELECT DISTINCT p.gradeFROM positions pWHERE (p.total % 2 = 1 AND (p.total + 1) / 2 BETWEEN p.start_pos AND p.end_pos) OR (p.total % 2 = 0 AND (p.total / 2 BETWEEN p.start_pos AND p.end_pos OR p.total / 2 + 1 BETWEEN p.start_pos AND p.end_pos))ORDER BY p.grade;
该 SQL 脚本旨在从班级成绩表(已按成绩等级分组统计学生人数)中查询学生综合成绩等级的中位数档位。
在成绩表中,每个等级对应一个学生人数,而非具体的学生列表,因此中位数的定位需基于人数的累积分布来实现。
脚本通过构建中间结果,逐步计算每个等级在整体排序中的位置区间,最终根据中位数的数学定义确定其所属等级。这种方法避免了展开每个学生记录的繁琐过程,直接利用聚合数据高效完成查询。
首先,脚本通过一层处理计算每个成绩等级的累计人数和总人数。累计人数按等级顺序从高到低逐级累加,反映了每个等级在整体排序中的结束位置;总人数则是所有等级人数的总和。
这一步为后续判断中位数位置奠定了基础,因为它将离散的等级人数转换为连续的排序序列,使得中位数的位置可以映射到具体的等级区间。
接下来,脚本通过另一层处理确定每个成绩等级在排序中的起始和结束位置。
起始位置由上一等级的累计人数加一得到,表示该等级的第一个学生在整体中的序号;结束位置即为该等级的累计人数,表示该等级的最后一个学生的序号。
这样,每个等级都对应一个连续的位置区间,方便后续判断中位数是否落在此区间内。
然后,脚本根据总人数的奇偶性判断中位数的具体位置。如果总人数为奇数,中位数位置是中间一个;如果为偶数,中位数位置是中间两个。
脚本通过检查这些位置是否落在某个等级的位置区间内,来识别中位数所属的等级。如果中位数位置跨越多个等级,则所有相关等级都会被选出,并按要求升序输出。
以上文数据为例,总人数为偶数,中位数位置是第六和第七。通过位置区间分析,第六位属于B等级,第七位属于C等级,因此查询结果输出B和C。这个例子验证了脚本逻辑的正确性,它能够灵活处理不同数据分布,确保结果符合数学定义。
总之,该脚本通过巧妙的累积计算和位置映射,高效解决了基于分组统计的中位数查询问题。其结构清晰,逻辑严谨,适用于类似“等级-人数”形式的统计场景,展现了SQL窗口函数在数据分析中的实用价值。
2.1 考核办法
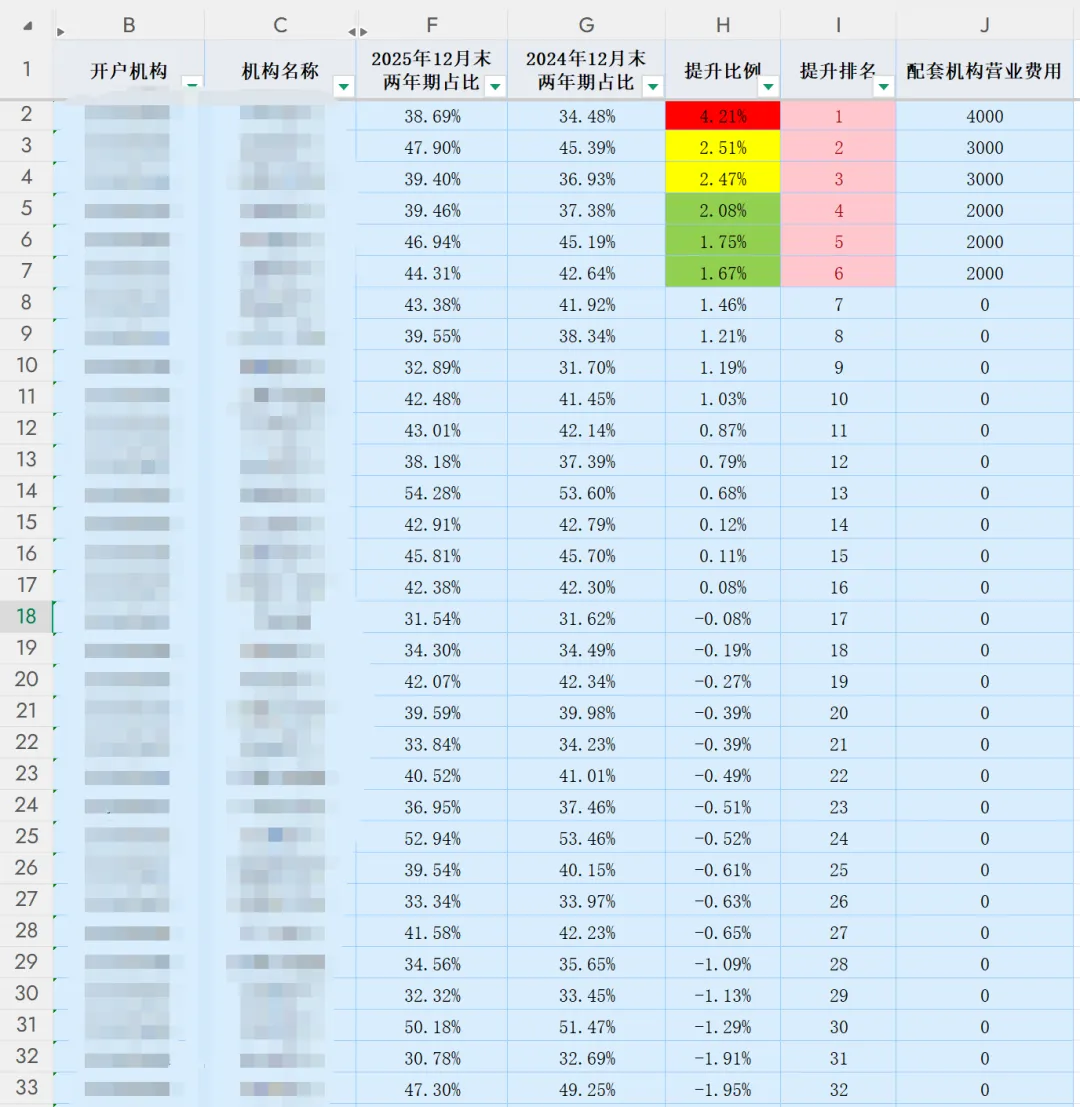
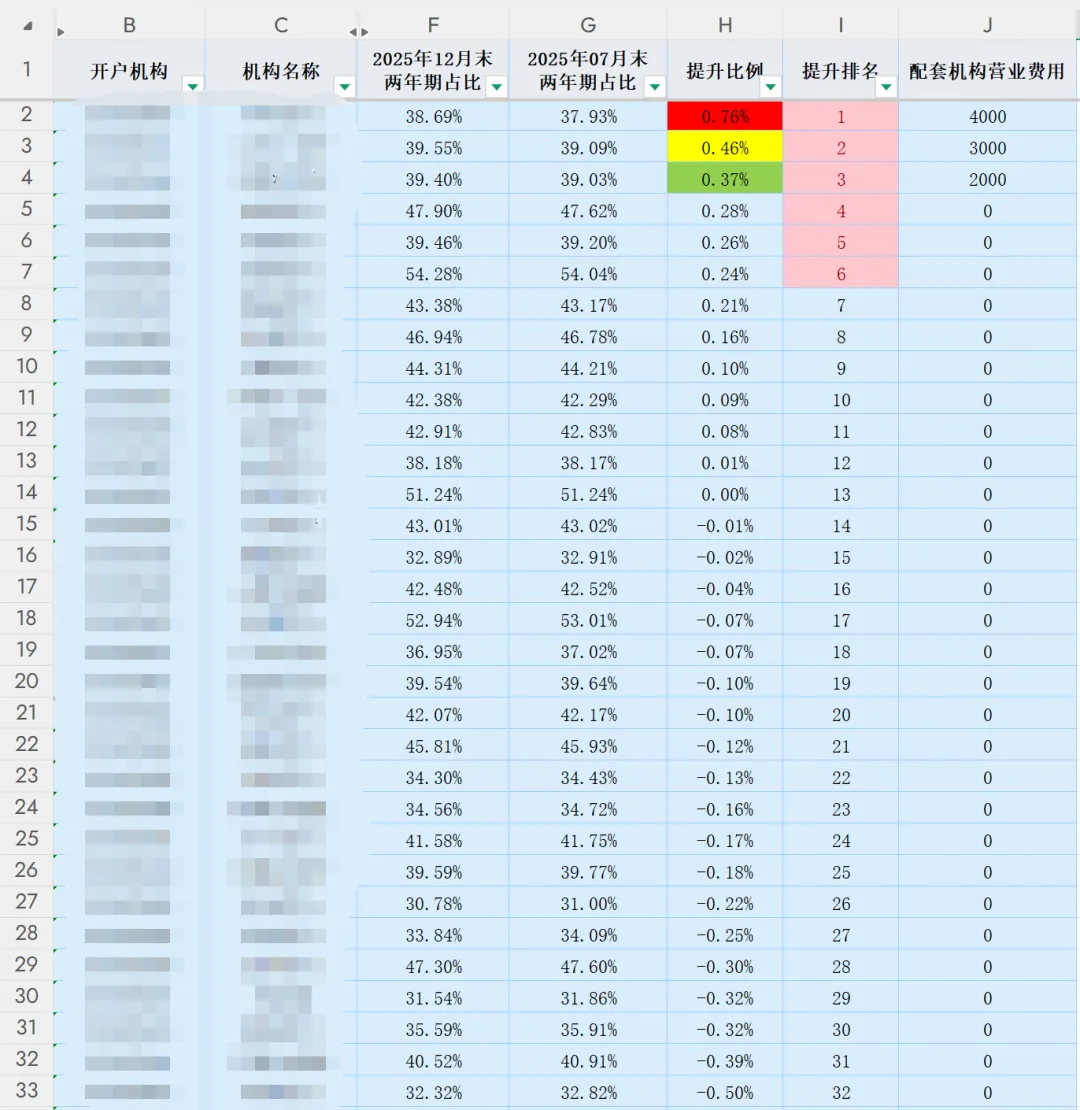
机构低成本存款占比提升目标奖励:分别设置一、二、三等奖,按两年期及以下日均存款占比提升比例排名前六名,设置一等奖1名(提升比例不低于0.5%),二等奖2名(提升比例不低于0.4%),三等奖3名(提升比例不低于0.3%),分别配套机构营销费用4000元、3000元、2000元。2.3 Python脚本
import pandas as pdper = pd.read_excel("./机构低成本占比.xlsx", dtype={"开户机构":"str"})per["两年期占比"] = round(per["两年期占比"]*100,2)sjfq = per["数据日期"].unique().tolist()sjfq.sort()date_end = sjfq[-1]per_end = per.query("数据日期 == @date_end").reset_index(drop=True)per_end.rename(columns={"两年期占比":f"两年期占比{date_end}"},inplace=True)for date_start in sjfq[:-1]: fir = 1 sec = 2 thi = 3 per_start = per.query("数据日期 == @date_start").reset_index(drop=True) per_start.rename(columns={"两年期占比":f"两年期占比{date_start}"},inplace=True) res = per_end[["开户机构","机构名称","两年期以下日均",f"两年期占比{date_end}"]].merge(per_start[["开户机构","机构名称",f"两年期占比{date_start}"]], on=["开户机构","机构名称"]) res["提升比例"] = round(res[f"两年期占比{date_end}"] - res[f"两年期占比{date_start}"],2) res = res.sort_values(by=["提升比例",f"两年期占比{date_end}","两年期以下日均"],ascending=False).reset_index(drop=True) res.drop(columns=["两年期以下日均"],inplace=True) for i in res.index: if res.loc[i,"提升比例"] >= 0.5 and fir > 0: res.loc[i,"营销费用"] = 4000 fir -= 1 elif res.loc[i,"提升比例"] >= 0.4 and sec > 0: res.loc[i,"营销费用"] = 3000 sec -= 1 elif res.loc[i,"提升比例"] >= 0.3 and thi > 0: res.loc[i,"营销费用"] = 2000 thi -= 1 else: res.loc[i,"营销费用"] = 0 res = res.sort_values(by=["开户机构"]).reset_index(drop=True) res.to_excel(f"./机构低成本占比提升考核表(较{date_start}).xlsx", index=False)
该Python脚本实现了一个机构低成本存款占比提升的考核系统,旨在根据机构在特定时间段内的表现提升比例来分配营销费用奖项。其核心逻辑与先前抽象的数学规则紧密对应,通过程序化方式模拟了奖项评定的全过程。
脚本首先从数据源中提取关键的时间点信息,并以最新的数据日期作为评估的终点,依次与历史各起点日期进行对比,从而计算出每个机构在对应时间段内的提升比例。
这一提升比例的计算本质上是将终点日期的两年期占比减去起点日期的占比,并以百分比形式呈现,这与数学定义中的提升比例变量直接关联,为后续的奖项评定提供了量化基础。
在奖项分配环节,脚本严格遵循了数学规则中设定的约束条件。通过按提升比例降序排序,脚本确保了排名优先的原则,即提升比例更高的机构在奖项分配中具有优先权。
随后,脚本使用动态名额计数器来模拟奖项名额的限制,其中一等奖、二等奖和三等奖的名额上限分别对应数学定义中的固定值。
对于每个机构,脚本从一等奖开始依次检查其提升比例是否达到该奖项的最低阈值,并在名额可用时分配相应的营销费用;若不符合当前奖项条件,则逐级向下检查,直至可能获得符合条件的奖项或一无所获。
这一过程完美实现了数学规则中的降级发放机制,即当机构不满足高奖项条件时,仍有机会获得较低奖项,从而确保了奖项分配的灵活性和合理性。
此外,脚本通过名额计数器的递减操作,自然保证了获奖机构总数不超过六个,这与数学约束中的总数限制完全一致。虽然脚本未显式验证获奖机构总数,但由于名额上限之和为六,且每个机构至多获得一个奖项,因此总数限制得以自动满足。
最终,脚本为每个起点日期生成独立的考核表,其中包含了各机构的提升比例和分配的营销费用,从而完成了从数据筛选、计算提升、排名评定到费用增加的全流程。
整体而言,这段脚本是数学规则的高效程序化实现,通过清晰的逻辑步骤确保了奖项分配的公平性和合规性。
2.5 结果展示
需要说明的是,以上截图首先是手工制作的表格,然后才萌发了开发自动化脚本的想法,实际运行结果与上图完全一致。Q:在金融科技工作中,很多自动化脚本的核心逻辑并不复杂,人工仅凭肉眼观察和业务经验就能快速理解,甚至手动完成对应的操作流程。但这类脚本的开发过程,往往需要攻克环境适配、异常处理、合规校验等诸多难题。既然人工操作也能实现目标,我们为何还要耗费大量心力去研发这些自动化脚本呢?A:上述Python或SQL脚本虽然处理的是在有限数据量下人工可完成的逻辑判断,但其开发意义远不止于替代人工操作。这背后体现了金融机构在数字化转型过程中必须完成的几个关键思想转变:
首先,自动化脚本的核心价值在于可重复性与规模化。
人工处理虽能应对一时一地的数据,但当考核周期缩短、机构数量增加、计算规则需要频繁调整时,人工操作的效率与准确性会急剧下降。
脚本能够确保每次执行过程一致、规则透明,且可随时复用或调整,这是人工难以持续保证的。
其次,这类脚本体现了过程标准化与规则显性化的重要性。
金融机构内部往往存在大量依赖个人经验的判断与手工操作,容易形成“黑箱”,不利于审计、复核与传承。
将逻辑转化为代码,实际上是将业务规则明确化、结构化,便于团队协同、规则优化与合规管理,也为后续系统化建设打下基础。
再者,数字化转型并非一蹴而就,而是从“人脑判断+手工操作”逐步转向“系统判断+自动化执行”的渐进过程。
即使是一个看似简单的脚本,也是将业务知识沉淀为数字资产的重要一步。它帮助机构积累数据处理经验、训练团队的数据思维,并为未来更复杂的分析模型与决策系统铺路。
最后,这也反映出金融机构在思想层面需从“解决单次问题”转向“构建可持续的解决方案”。
开发脚本虽在初期投入较多精力,但其长期收益体现在效率提升、错误减少、响应加速等方面。这种投入本质上是对组织能力的投资,推动企业从依赖个人能力转变为依靠系统能力,从而实现真正意义上的数字化运营。
数字化转型在操作层面的核心价值正体现在,从依赖个人能力的“管道工”模式,转向依靠系统能力的“调度员”模式。
以EAST5.0直报辅助系统及统计分析报送平台为例,它们本质上构建了一条标准化、自动化的“数据流水线”。
过去,我们的精力大量耗费在“接水、导流、运输”等一系列手动操作环节上,整个过程琐碎、易错且高度依赖个人经验与责任心。而现在,系统确保了“管道”本身的坚固与流程的畅通。
我们的工作重心得以前移和后置:在“打开阀门”前,聚焦于审视源头数据的质量与业务规则的正确性;在“水流抵达”后,则专注于分析输出结果的业务含义,并进行反馈与优化。
这一转变的深刻之处在于,它将员工从重复性、程序性的复杂处理中解放出来,转而投入到更高价值的“正确性研判、反馈与修正”中。
我们不再仅仅是数据的搬运工和计算者,而成为了数据质量与规则有效性的监督者、分析者和优化者。
这正是数字化转型在思想层面带来的关键升华:从关注“如何完成一个任务”,到关注“如何设计并维护一个能持续产出正确结果的系统能力”。
因此,这类自动化脚本的开发与使用,标志着金融机构正在从经验驱动、手工主导的传统模式,转向数据驱动、流程自动化的数字管理模式。这一转变不仅是技术升级,更是组织思维与工作文化的深刻变革。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
