Python复现顶刊CEJ | 拒绝手绘!如何用代码“量产”高颜值多面板吸附等温线图?
- 2026-07-06 23:20:39
01
前言
做科研最痛苦的时刻,不是实验失败,而是实验成功了,图却画得像“马赛克拼盘”。
你是否有过这样的经历:手握这一堆珍贵的实验数据(Experiment)、模拟数据(GCMC),还有自己辛辛苦苦跑出来的模型预测值(Model A, B, C),想把它们放在一张图里“同台竞技”。结果,Excel 画出来的线乱成一团麻,PPT 拼凑的子图总是对不齐,字体忽大忽小,最后被导师一句“缺乏美感”打回重造。
这就是典型的“多维数据展示痛点”。
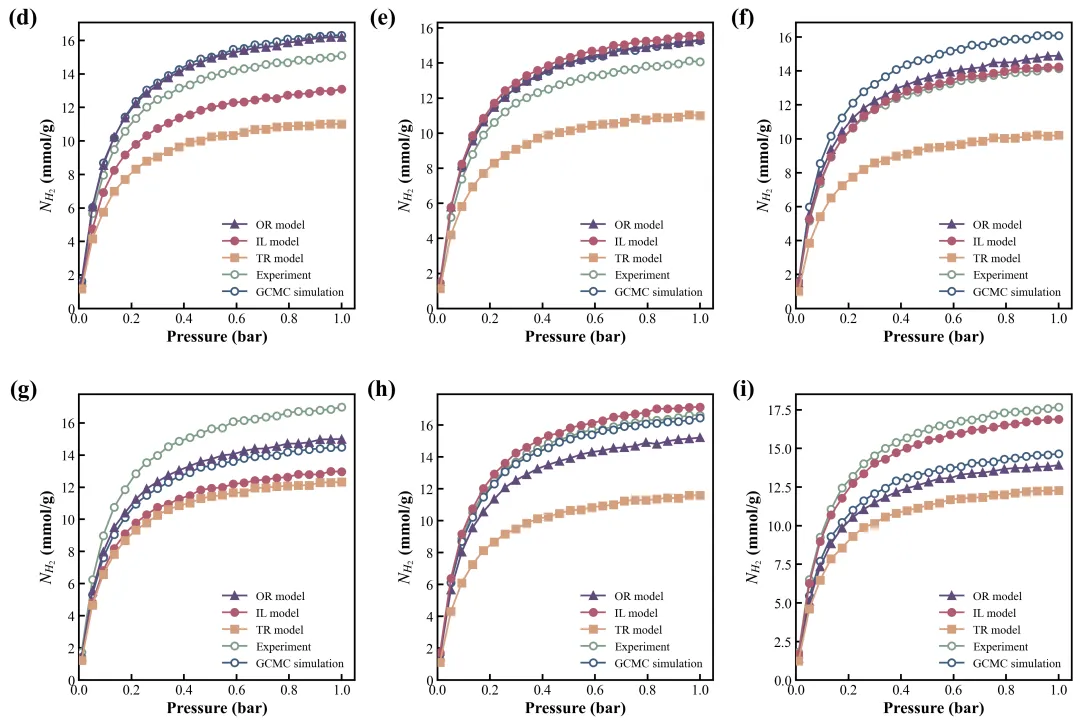
今天我们要复刻的这张图,来自顶刊 《Chemical Engineering Journal》 (CEJ, IF=13.3) 的最新论文 。这张图(Figure 6 d-i)展示了作者提出的 IL model(增量学习模型) 在不同温度和压力下,如何单挑传统模型(TR model)并逼近真实实验数据。它看似简单,实则暗藏玄机:6 个子图、5 种数据源、复杂的图层叠加、精准的对齐逻辑。
今天,我们就用 Python (Matplotlib),像做外科手术一样,把这张图从骨架到灵魂完整复现。不整虚的,直接上干货。

02
原图解析
在写代码之前,我们需要像外科医生一样,先对这张图进行“解剖”。只有看懂了结构,才能写对代码。
3.1 视觉解剖 (The Anatomy)
🦴 骨架 (Structure)
这张图采用的是 2×3 Grid Layout(网格布局)。
很多同学画这种图,喜欢画 6 张单独的图然后去 PPT 里拼。千万别这么做! 这种“物理拼接”会导致字号不统一、轴线不对齐。正确的做法是使用 Matplotlib 的 GridSpec,让它们在同一张画布上“共生”。
🍰 核心技巧:三明治图层法 (The Sandwich Trick)
仔细看原图,你会发现一个惊人的细节:蓝色的空心圆(Experiment)永远浮在所有实心线(Model)之上。
这就是“图层顺序(Z-order)”的艺术。如果你的模型预测线(红线)把实验点(蓝圈)盖住了,审稿人会觉得你在“掩盖真相”。我们必须像做三明治一样:
底层:网格线 (Grid)
夹层:模型预测线 (Solid Lines)
顶层:实验真值 (Hollow Markers)
🎨 配色 (Palette) —— 高级感的来源
作者没有用大红大绿,而是选了一组对比极强但又不刺眼的配色:
青色 (Cyan, #00CED1):代表 OR 模型,冷色调,退居次席。
红色 (Red, #FF0000):代表 IL 模型(主角),暖色调,视觉重心,一眼就能看到。
黑色 (Black, #000000):代表 TR 模型和模拟值,作为基准色,沉稳。
白色填充+蓝色描边:实验值。这种“空心”设计赋予了数据通透感,也是顶刊图表的常见做法。
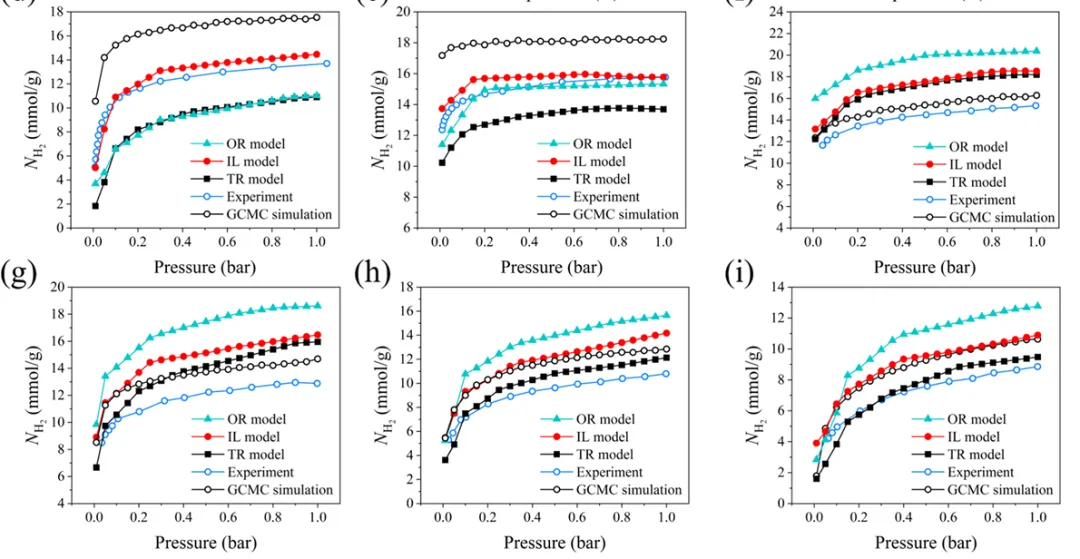
论文原图
3.2 读懂神图 (Scientific Decoding)
别光顾着画,这图到底说了个啥?如果你看不懂图里的科学逻辑,画出来也是没有灵魂的躯壳。
这张图是全篇论文的“证据高地” 。
X轴:压力 (Pressure, bar)。
Y轴:H_2 吸附量 (mmol/g)。
剧情走向:随着温度升高(从 (f) 40K 到 (i) 70K),所有材料的吸附量都在下降(这是物理规律)。
核心冲突:看图 (i),在 70K 高温下,OR 模型(青线) 飞到天上去了(严重高估),TR 模型(黑方块) 掉下去了(严重低估)。
主角光环:只有作者的 IL 模型(红线),稳稳地夹在中间,紧紧咬住 实验值(蓝圈) 。
看懂了吗?我们在画图时,必须确保红色曲线在视觉上最突出,因为那是作者想卖的“瓜”。

03
代码复刻
Step 1 全局配置
在 import 之后,不要急着 plt.figure()。真正的玩家会先修改 rcParams。这是给整张图定“基调”。如果不设这个,Matplotlib 默认的图表就像“程序员的调试日志”,毫无美感。
import matplotlib.pyplot as pltimport matplotlib.font_manager as fmimport warnings# 全局关闭非关键警告,保证绘图输出整洁,看着清爽warnings.filterwarnings('ignore')# --- 顶刊风格内核锁定 (Journal Aesthetics) ---# 字体设置:优先使用 Times New Roman,这是 SCI 的标配plt.rcParams['font.family'] = ['Times New Roman', 'Arial', 'SimHei']plt.rcParams['mathtext.fontset'] = 'stix' # 公式字体使用 STIX (类似 LaTeX)# 基础字号与线条定义:线条要粗,字要大,这就是“高级感”的来源plt.rcParams['font.size'] = 16 # 默认字号plt.rcParams['axes.linewidth'] = 1.5 # 坐标轴线宽 (Bold)plt.rcParams['lines.linewidth'] = 2.0 # 数据线宽plt.rcParams['xtick.direction'] = 'in' # 刻度朝内,更紧凑plt.rcParams['ytick.direction'] = 'in'plt.rcParams['savefig.bbox'] = 'tight' # 自动切除白边plt.rcParams['savefig.dpi'] = 600 # 印刷级分辨率
Step 2 样式引擎
很多新手喜欢在绘图循环里写 if model == 'A': color='red'。这种写法一旦模型变多,代码就变成了“面条”。
我们采用“配置与逻辑分离”的思想,建立一个样式字典 (style_map)。以后审稿人让你“把红色换成深红”,你只需要改这里的一行代码,而不用去 6 个子图里到处找。
# --- 样式管理引擎 (Configuration as Code) ---# 定义每个角色的“皮肤”:颜色、形状、空心/实心、线型style_map = {'OR model': {'color': '#00CED1', 'marker': '^', 'ls': '-','mfc': '#00CED1', 'label': 'OR model', 'zorder': 3},'IL model': { # 主角:红色,实心圆'color': '#FF0000', 'marker': 'o', 'ls': '-','mfc': '#FF0000', 'label': 'IL model', 'zorder': 4},'TR model': {'color': '#000000', 'marker': 's', 'ls': '-','mfc': '#000000', 'label': 'TR model', 'zorder': 3},'Experiment': { # 真值:蓝色边框,白色填充(空心),层级最高'color': '#1E90FF', 'marker': 'o', 'ls': '-','mfc': 'white', 'label': 'Experiment', 'zorder': 5},'GCMC simulation': {'color': 'black', 'marker': 'o', 'ls': '-','mfc': 'white', 'label': 'GCMC simulation', 'zorder': 5}}
Step 3 画布构建
不要用 plt.subplots(2, 3),那个对间距的控制太弱。我们要用 GridSpec。它能让你像排版报纸一样,精确控制每个子图的大小和间距。
# --- 画布布局 (Layout Strategy) ---fig = plt.figure(figsize=(15, 10)) # 宽15高10,适合双栏排版# wspace/hspace 控制子图之间的“呼吸感”# 0.3 的间距既不会太挤,又能留出放坐标轴标签的空间gs = gridspec.GridSpec(2, 3, figure=fig, wspace=0.3, hspace=0.3)# 建立面板映射关系,方便循环调用# 比如 Panel 'd' 放在第0行第0列panel_grid_map = {'d': (0, 0), 'e': (0, 1), 'f': (0, 2),'g': (1, 0), 'h': (1, 1), 'i': (1, 2)}# 假设 df_plot 是我们要画的数据 (DataFrame结构)# 列包含: Pressure, Uptake, Method, Panelprint("画布准备就绪,准备注入数据...")
Step 4 核心循环
这是最关键的一步。我们遍历所有面板,根据 style_map 自动分配样式。注意看 zorder 的参数,这就是我们在 Cell 3 复盘时提到的“三明治图层法”的代码实现。
# --- 循环绘图引擎 (The Loop) ---panels = ['d', 'e', 'f', 'g', 'h', 'i']# 确保图例顺序一致,不要乱序method_order = ['OR model', 'IL model', 'TR model', 'Experiment', 'GCMC simulation']for panel_id in panels:# 1. 激活子图row, col = panel_grid_map[panel_id]ax = fig.add_subplot(gs[row, col])# 2. 筛选当前面板的数据panel_data = df_plot[df_plot['Panel'] == panel_id]# 3. 遍历每个方法进行绘图for methodinmethod_order:subset = panel_data[panel_data['Method'] == method].sort_values('Pressure')style = style_map.get(method, {})# 核心绘图命令:一行代码调用所有样式配置ax.plot(subset['Pressure'], subset['Uptake'],color=style['color'],linestyle=style['ls'],linewidth=1.5,marker=style['marker'],markersize=6,markerfacecolor=style['mfc'], # 控制实心/空心markeredgecolor=style['color'],markeredgewidth=1.0, # 稍微调细一点边缘,更精致label=style['label'],zorder=style.get('zorder', 3) # 关键:图层顺序!)
Step 5 注入灵魂
图画完了,但现在的图还是“死”的。我们需要加上序号 (d), (e)... 还要调整刻度。
这里有一个巨大的坑:很多同学用数据坐标加序号(比如 x=0.5),结果换个数据,序号就跑到线堆里去了。
解法:使用 transform=ax.transAxes。这是以子图边框为基准的相对坐标系。(-0.15, 1.05) 永远固定在左上角那个最帅的位置。
# --- 细节精修 (Refining) ---# 1. 轴标签:加粗,字号大一点ax.set_xlabel('Pressure (bar)', fontsize=14, fontweight='bold')ax.set_ylabel('$N_{H_2}$ (mmol/g)', fontsize=14, fontweight='bold') # 支持LaTeX公式# 2. 坐标轴范围控制ax.set_xlim(0, 1.05)ax.set_ylim(bottom=0) # 只锁定下限,上限让它自适应,留出呼吸空间# 3. 强制刻度逻辑 (Cell 3 复盘的修正点)# 确保刻度间隔合理,比如每隔 0.2 bar 一个主刻度ax.set_xticks([0.0, 0.2, 0.4, 0.6, 0.8, 1.0])# 4. 黄金角标位 (The Golden Corner)# transform=ax.transAxes 保证了序号永远在图的左上角外面ax.text(-0.15, 1.05, f"({panel_id})", transform=ax.transAxes,fontsize=20, fontweight='bold', va='top', ha='right')# 5. 图例优化# frameon=False 去掉图例边框,显得更现代、不遮挡视线ax.legend(loc='lower right', frameon=False, fontsize=10)# 最后保存plt.savefig('Figure_Replication.png', dpi=600, bbox_inches='tight')plt.show()
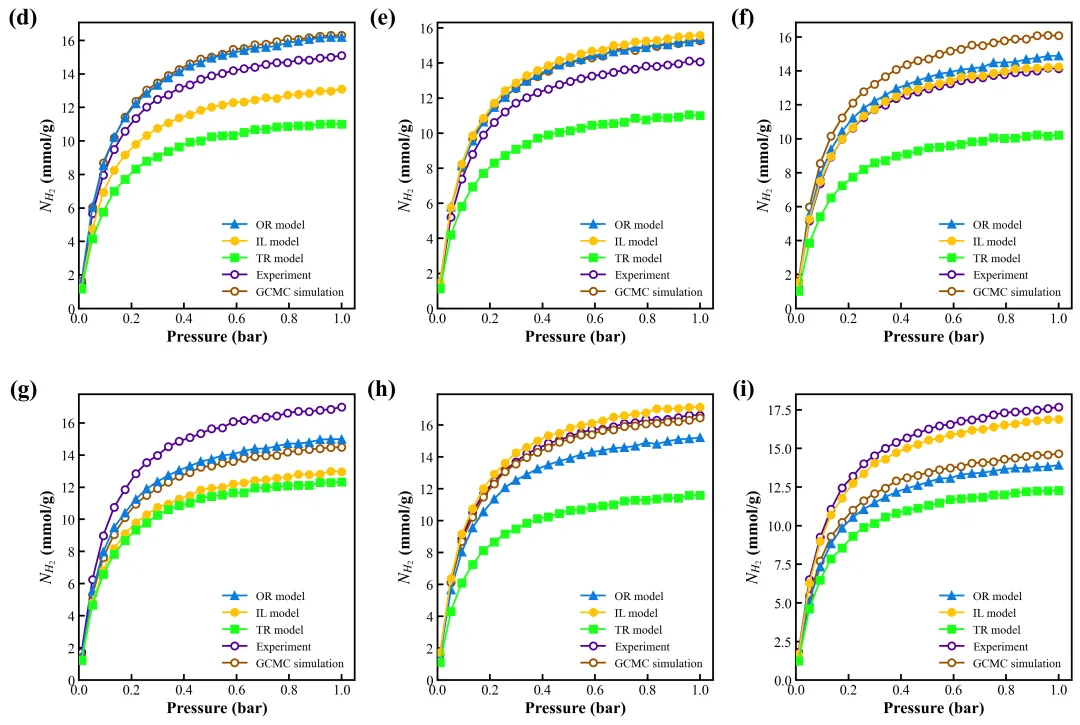
来看一下我们的复刻成果。
原图 vs 复刻图:
布局:完美复现 2×3 网格。
逻辑:实心的 IL 模型(红线)在视觉上被突出了,空心的 Experiment 数据点清晰地悬浮在顶层,没有被线条“吞没”。
细节:字体是正宗的 Times New Roman,刻度朝内,充满了“Money”的味道(指版面费)。
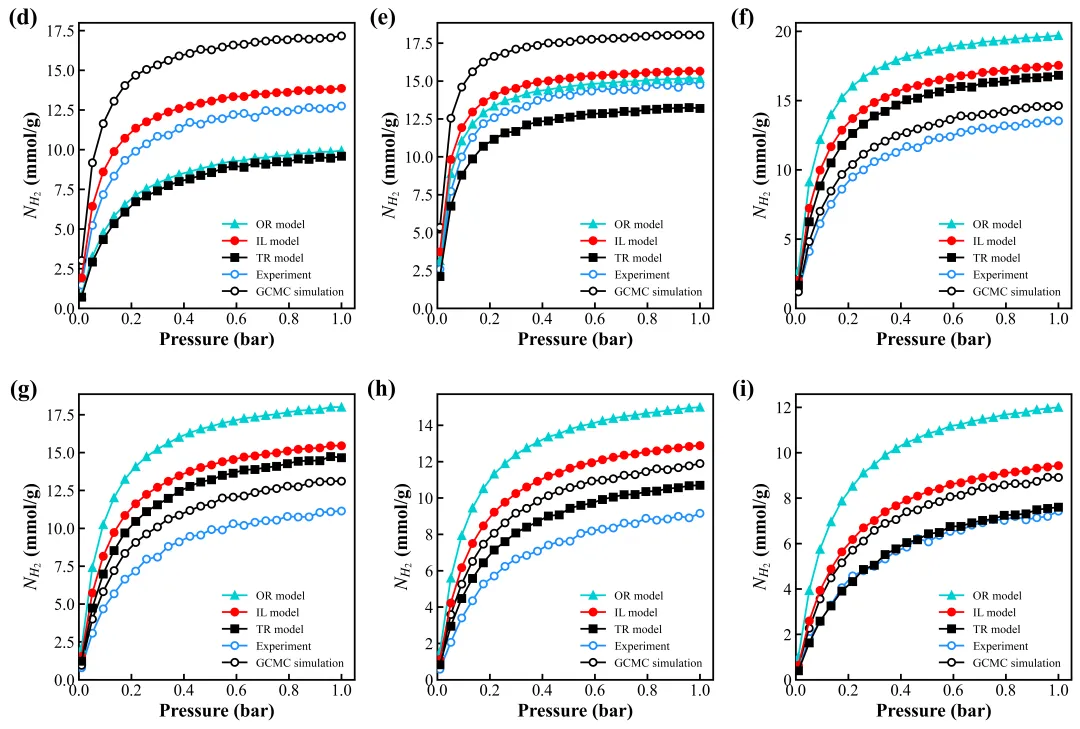
复刻图

04
多配色参考
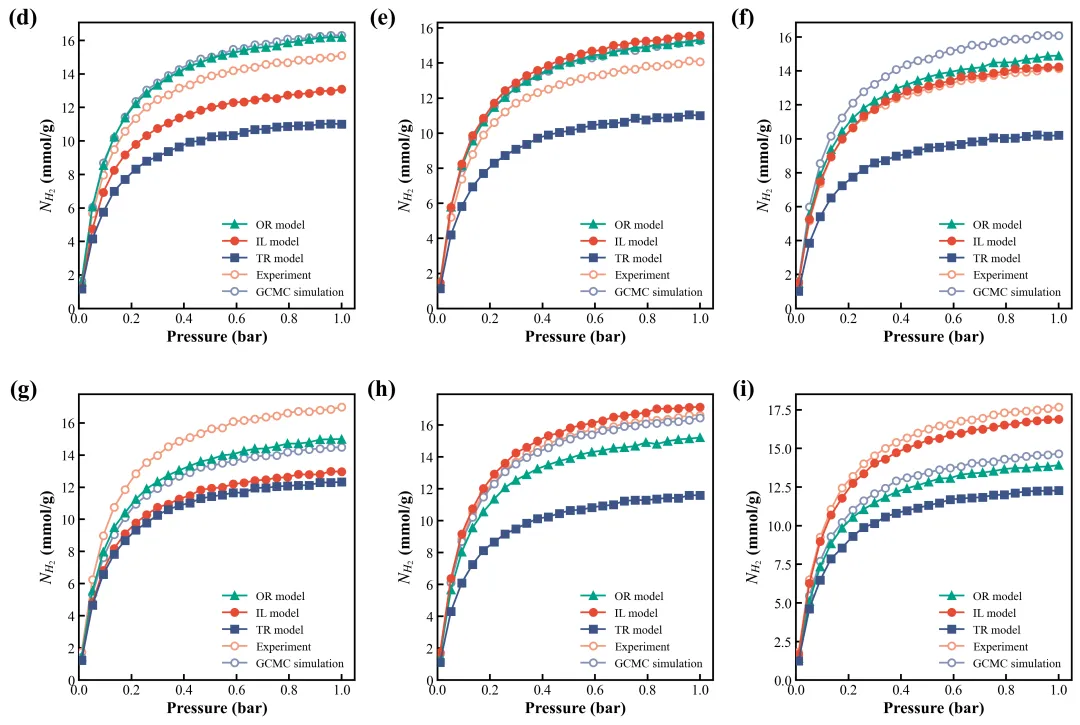
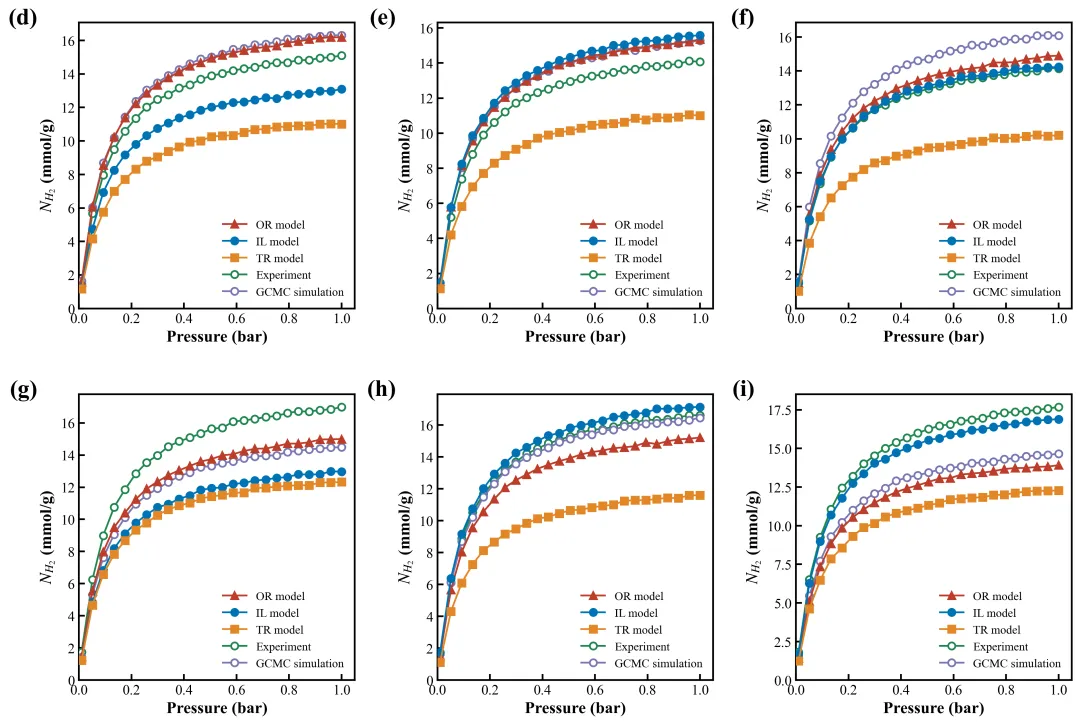
多配色参考

05
代码获取
👇 关注公众号【嗡嗡的Python日常】
🚫 关于源码: 本文核心代码为原创定制,暂不免费公开。
✅ 如果你需要:
购买本项目完整源码 + 数据
定制类似的科研绘图
咨询代码运行报错问题
请直接添加号主微信沟通(有偿分享☕️): Wjtaiztt0406



微信号丨Wjtaiztt0406

