1. 环境安装和对 Python 认识
Anaconda 环境配置 + PyCharm 安装
Conda 是什么:Conda 是一个环境管理 + 包管理工具,最常见于 Anaconda / Miniconda 这套生态里。
Notebook 使用说明:适合交互式编程和数据分析。
Python 本质:Python 编译器是用 C 语言实现的,并能够调用 C 语言的库文件。
2. 基础语法
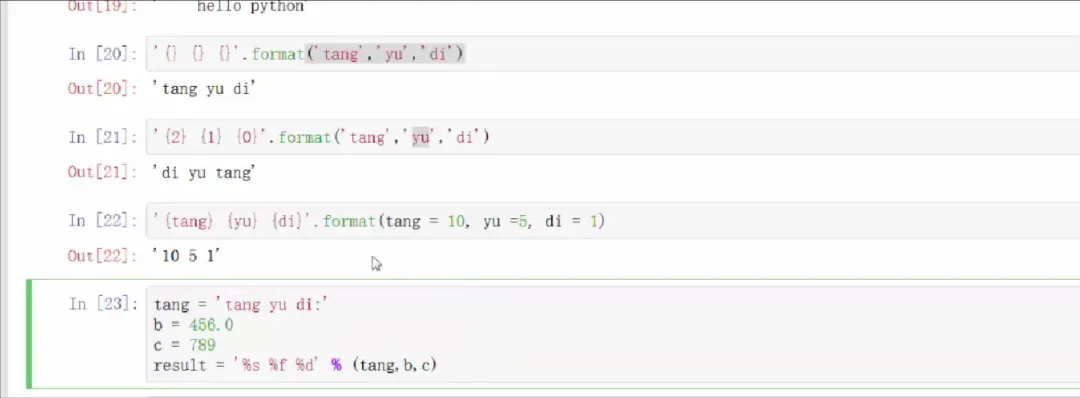
2.1 字符串 (String)
变量名.replace('待替换', '替换为')
变量名.strip():去两端空格 (配合 lstrip / rstrip)
f-string (推荐):f".. {变量名/表达式} .."
2.2 运算符
- 浮点数精度问题:浮点数运算可能会损失精度,因为计算机底层是基于二进制来进行数据的存储和处理的,二进制无法准确表示所有的小数。
2.3 流程控制
模式匹配 match...case (Python 3.10+)
案例:基于 match...case 实现一个简易的计算器。
num1 = float(input("请输入第一个数:"))
num2 = float(input("请输入第二个数:"))
oper = input("请输入运算符(+ - * /):")
match oper:
case "+":
print(f"{num1} + {num2} = {num1 + num2}")
case "-":
print(f"{num1} - {num2} = {num1 - num2}")
case "*":
print(f"{num1} * {num2} = {num1 * num2}")
case "/"if num2 != 0: # if条件成立,才匹配这个case
print(f"{num1} / {num2} = {num1 / num2}")
case _:
print("操作不支持!!!")
循环与随机数
for i in range(start, end):左闭右开区间。random.randint(1, 100):生成 1-100 的随机整数。
2.4 数据存储容器 (序列都能进行切片)
2.4.1 列表 (List)
- 特点:可以存储不同类型的元素、元素可重复、可修改、元素有序。
- 常用统计:
sum(list) 求和,len(list) 求长度,min(list) 最小值,max(list) 最大值。 - 解包合并:
List = [*list1, *list2]
常用方法表:
| | |
|---|
append() | | s.append(10086) |
insert() | | s.insert(0, 92) |
remove() | | s.remove(75) |
pop() | | s.pop(2) |
sort() | | s.sort() |
reverse() | | s.reverse() |
列表案例代码:
# 案例1:合并两个列表并去重
num_list1 = [19, 23, 54, 64, 875, 20, 109, 232, 123, 54]
num_list2 = [55, 80, 72, 35, 60, 123, 54, 29, 91]
# 1. 解包合并
num_list = [*num_list1, *num_list2]
print("合并后的原始列表:", num_list)
# 2. 去重
new_list = []
for num in num_list:
if num notin new_list:
new_list.append(num)
print("去重后的列表:", new_list)
# --------------------------------------------------------
# 案例2:列表推导式生成 1-20 的平方列表
# 语法:[要插入的值 for i in 序列]
num_list2 = [i**2for i in range(1, 21)]
print(num_list2)
# --------------------------------------------------------
# 案例3:提取偶数并计算平方
# 语法:[要插入的值 for i in 序列 if 条件]
num_list = [12, 32, 45, 77, 80, 92, 33, 57, 97, 98, 110, 111, 122]
new_list = [i**2for i in num_list if i % 2 == 0]
print(new_list)
2.4.2 字符串 (Str) 容器特性
常用操作方法:
| | |
|---|
find() | | s.find('Python') |
count() | | s.count('H') |
upper() | | s.upper() |
lower() | | s.lower() |
split() | | s.split(' ') |
strip() | | s.strip() |
replace() | | s.replace('H','C') |
startswith() | | s.startswith('P') |
2.4.3 元组 (Tuple)
- 注意:定义单元素元组需加逗号,如
t = (10,)。 - 常用方法:
count() 统计个数,index() 获取索引。
元组的组包与解包:
# 组包
t1 = 5, 7, 9, 10, 2, 23, 12# 自动封装为元组
# 基础解包 (变量数 = 元素数)
a, b, c, d, e, f, g = t1
print(a, b)
# * 扩展解包 (* 收集剩余元素为列表)
first, second, *other, last = t1
print(other) # 输出:[9, 10, 2, 23]
# 经典案例:变量交换
a = 10
b = 20
a, b = b, a # 极简写法(底层原理是组包+解包)
print(a, b) # 输出:20 10
元组综合案例:学生成绩分析
students = (
("S001", "王林", 85, 92, 78),
("S002", "李蔡婉", 92, 88, 95),
("S003", "十三", 78, 85, 82),
# ... (省略部分数据以节省空间)
("S010", "通天", 66, 59, 72)
)
print("学号\t\t姓名\t\t语文\t\t数学\t\t英语\t\t总分\t\t平均分")
# 1. 计算总分与平均分 (元组解包遍历)
for id, name, chinese, math, english in students:
total = chinese + math + english
avg = total / 3
print(f"{id} \t {name} \t {chinese} \t {math} \t {english} \t {total} \t {avg:.1f}")
# 2. 统计各科最值 (列表推导式提取数据)
chinese_scores = [s[2] for s in students]
math_scores = [s[3] for s in students]
print(f"语文---最低:{min(chinese_scores)},最高:{max(chinese_scores)}")
# ... (其他科目同理)
# 3. 查找优秀学生 (avg > 90)
for id, name, chinese, math, english in students:
if (chinese + math + english) / 3 > 90:
print(f"优秀学生:{name}")
2.4.5 集合 (Set)
- 定义:空集合必须用
set(),{} 代表空字典。
常用方法表:
| | |
|---|
add() | | s1.add('t') |
remove() | | s1.remove('t') |
pop() | | e = s1.pop() |
clear() | | s1.clear() |
difference() | | s1.difference(s2) |
union() | | |
intersection() | | s1.intersection(s2) |
集合综合案例:选课系统
football_set = {"王林", "曾牛", "徐立国", "遁天", "紫灵"}
basketball_set = {"张铁", "王林", "曾牛", "韩立", "厉飞雨"}
french_set = {"许木", "王卓", "十三", "韩立", "曾牛"}
art_set = {"遁天", "韩立", "紫灵"}
# 1. 交集:同时选修法语和艺术
print(french_set & art_set)
# 2. 连续交集:选修所有四门课
print(football_set & basketball_set & french_set & art_set)
# 3. 差集:选足球但没选篮球 (集合推导式写法)
print({s for s in football_set if s notin basketball_set})
# 4. 统计每人选课数 (利用并集获取全员名单)
all_set = football_set | basketball_set | french_set | art_set
# 将所有名单拼成一个大列表用于计数
all_list = [*football_set, *basketball_set, *french_set, *art_set]
for s in all_set:
print(f"{s} 选修了 {all_list.count(s)} 门课程")
2.4.6 字典 (Dict)
- 特点:键值对 (key:value),Key 唯一且不可变,Value 可修改。
增删改查 (CRUD) 操作:
| | |
|---|
| 添加/修改 | dict[key] = value | d["涛哥"] = 688 |
| 删除 | dict.pop(key) | d.pop("涛哥") |
| 删除 | del dict[key] | del d["涛哥"] |
| 查询 | dict[key] | d["涛哥"] |
| 查询 | dict.get(key) | d.get("涛哥") |
| 获取所有 | .keys() | |
字典综合案例:购物车管理系统
shopping_cart = {}
menu = """
############# 购物车系统 #############
# 1. 添加 2. 修改 3. 删除 4. 查询 5. 退出 #
#####################################
"""
print("欢迎使用购物管理系统 ~")
whileTrue:
print(menu)
choice = input("请选择操作(1-5):")
match choice:
case "1": # 添加
name = input("商品名称:")
if name in shopping_cart:
print("商品已存在")
else:
price = float(input("价格:"))
num = int(input("数量:"))
shopping_cart[name] = {"price": price, "num": num}
print("添加成功")
case "2": # 修改
name = input("要修改的商品:")
if name notin shopping_cart:
print("商品不存在")
continue
shopping_cart[name]["price"] = float(input("新价格:"))
shopping_cart[name]["num"] = int(input("新数量:"))
print("修改成功")
case "3": # 删除
name = input("要删除的商品:")
if name in shopping_cart:
del shopping_cart[name]
print("删除成功")
else:
print("商品不存在")
case "4": # 查询
for k, v in shopping_cart.items():
print(f"商品:{k},价格:{v['price']},数量:{v['num']}")
case "5":
print("再见!")
break
case _:
print("输入错误")
2.4.7 数据容器总结对比
| | | | | |
|---|
| 有序性 | | | | 无序 | |
| 重复元素 | | | | 不允许 | Key不允许 |
| 可变性 | 不可变 | | 不可变 | | |
| 索引访问 | | | | 不支持 | 不支持 |
| 切片操作 | | | | 不支持 | 不支持 |
| 使用场景 | | | | | |

 一起学 AI 大模型
一起学 AI 大模型