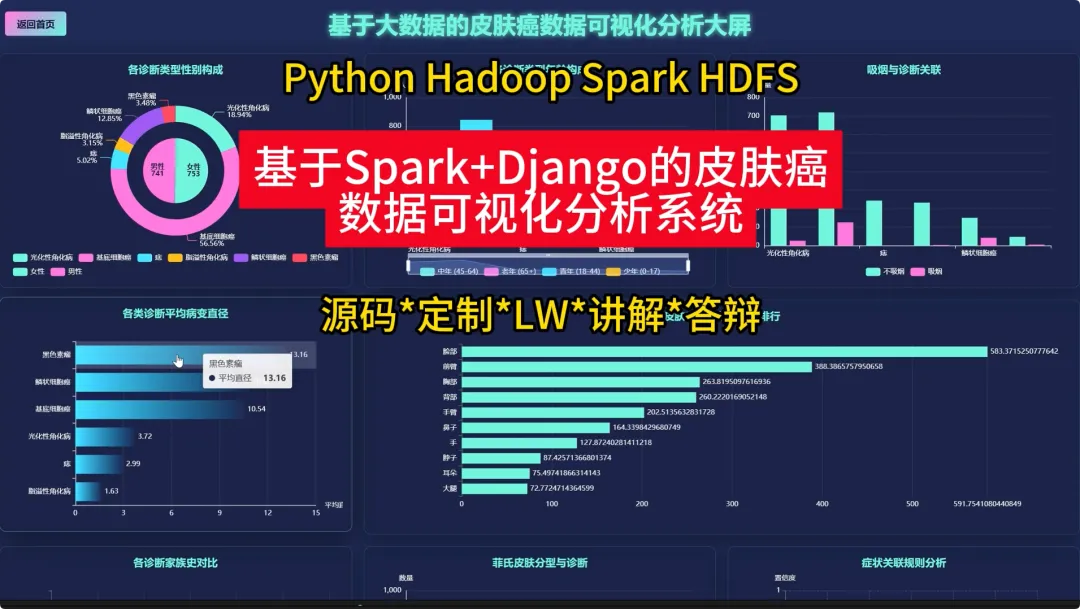
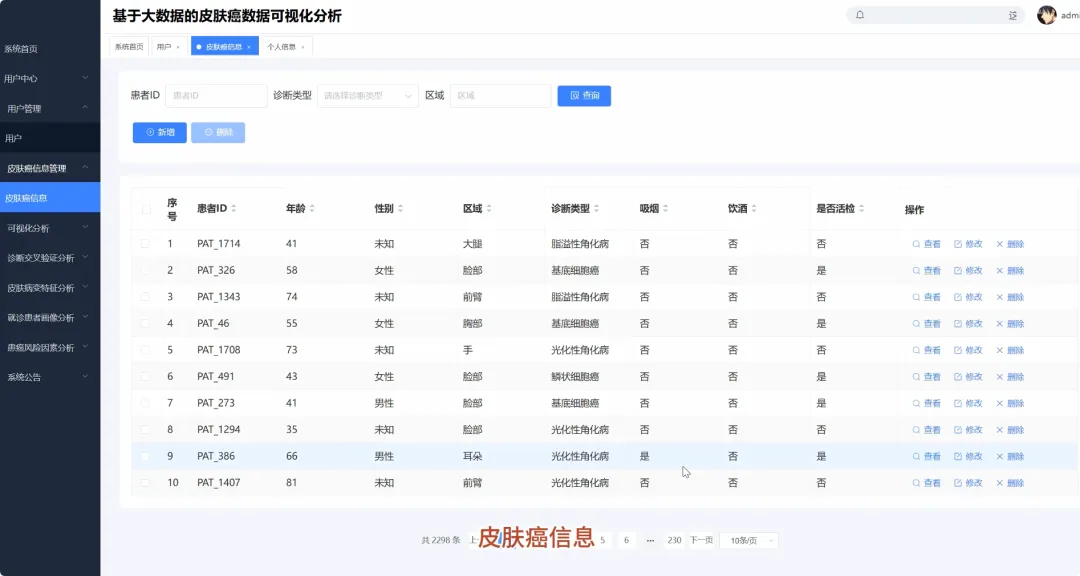
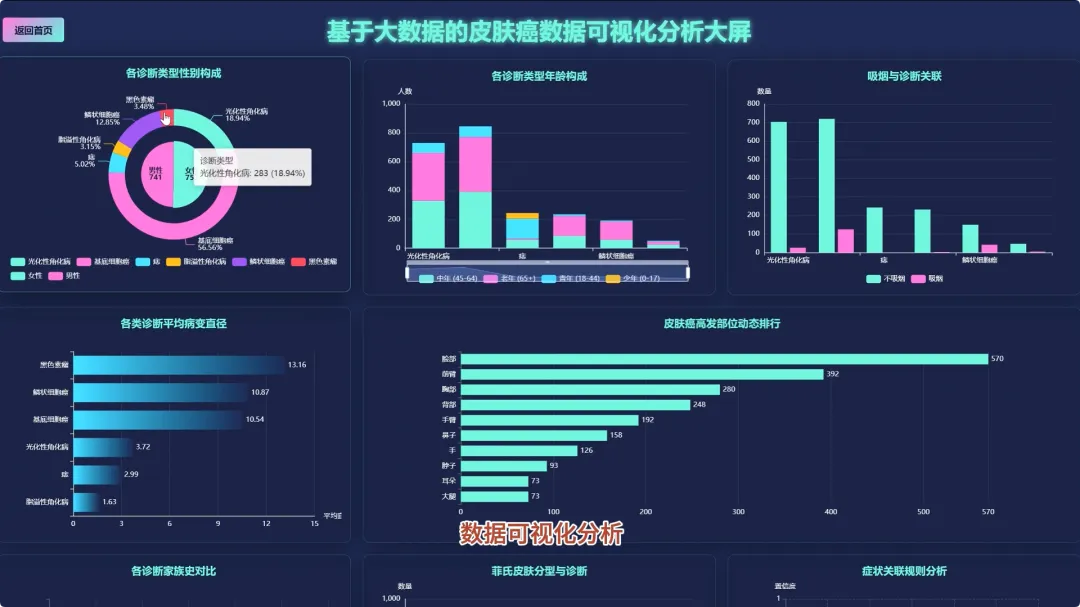
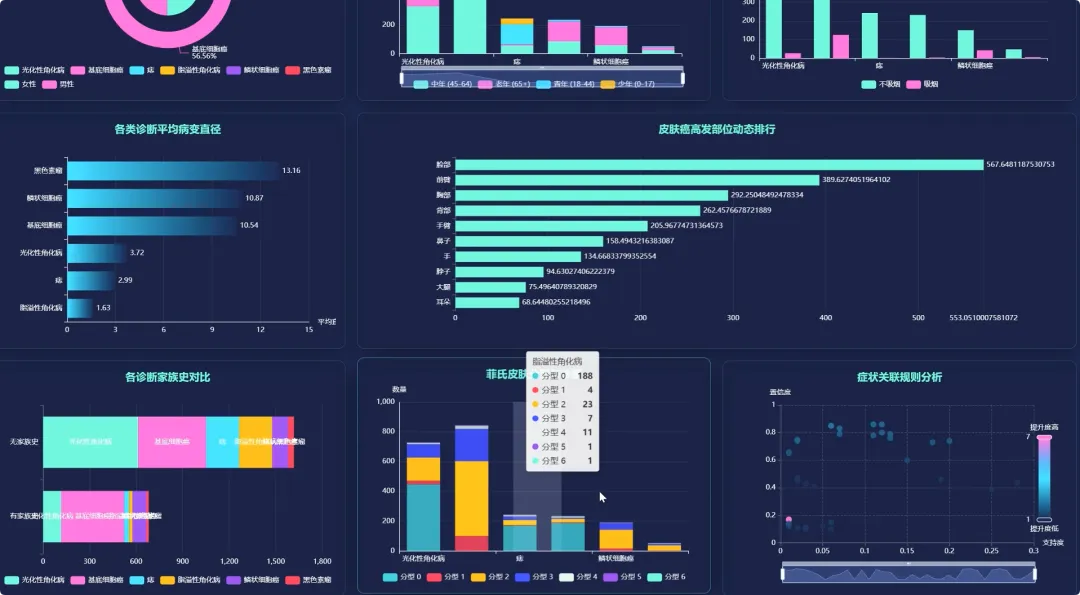
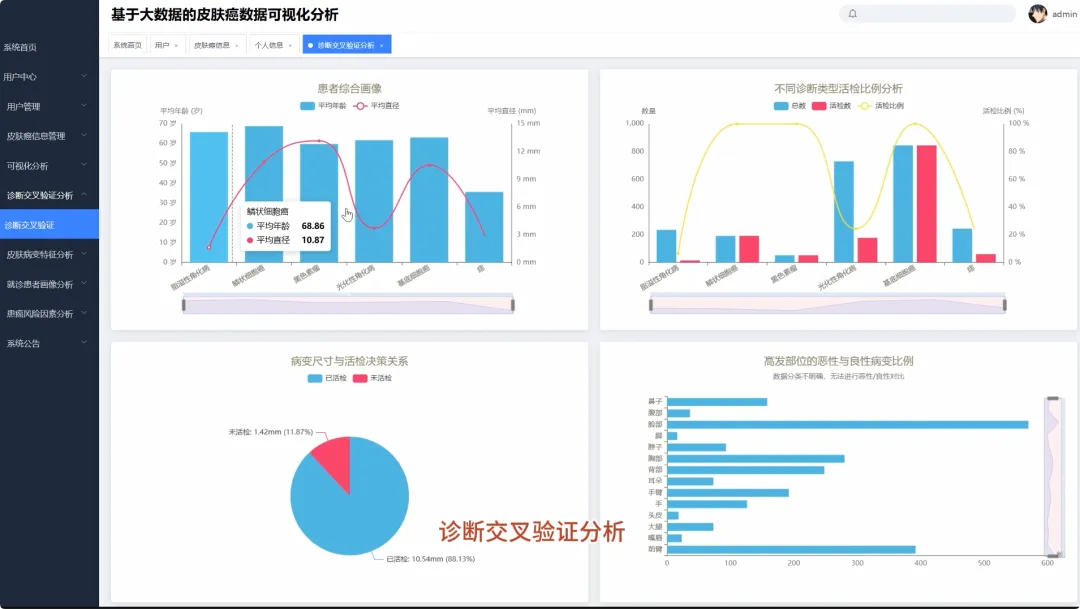
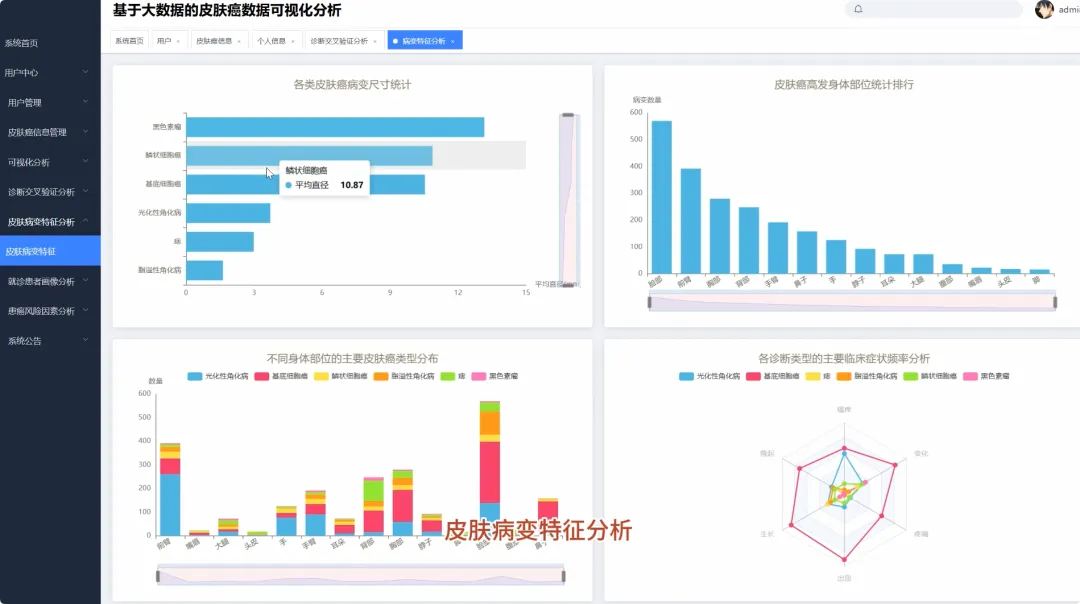
from pyspark.sql import SparkSession, functions as Fspark = SparkSession.builder.appName("SkinCancerAnalysis").getOrCreate()df = spark.read.csv("hdfs://path/to/skin_cancer_data.csv", header=True, inferSchema=True)def analyze_age_structure(df): df_with_age_group = df.withColumn("age_group", F.when((F.col("age") >= 0) & (F.col("age") < 30), "青年") .when((F.col("age") >= 30) & (F.col("age") < 50), "中年") .otherwise("老年")) age_diagnostic_count = df_with_age_group.groupBy("age_group", "diagnostic").count() total_in_age_group = age_diagnostic_count.groupBy("age_group").agg(F.sum("count").alias("total")) result = age_diagnostic_count.join(total_in_age_group, "age_group") result = result.withColumn("percentage", F.round((F.col("count") / F.col("total")) * 100, 2)) result = result.orderBy("age_group", "diagnostic") return result.collect()def analyze_top_body_regions(df): region_count = df.filter(F.col("region").isNotNull()).groupBy("region").count() top_regions = region_count.orderBy(F.col("count").desc()) return top_regions.collect()def mine_symptom_associations_for_mel(df): mel_df = df.filter(F.col("diagnostic") == "MEL") symptom_cols = ["itch", "grew", "hurt", "changed", "bleed", "elevation"] mel_symptoms = mel_df.select(*symptom_cols).na.fill(0) frequent_itemsets = [] for i in range(len(symptom_cols)): for j in range(i + 1, len(symptom_cols)): symptom_pair = mel_symptoms.filter((F.col(symptom_cols[i]) == 1) & (F.col(symptom_cols[j]) == 1)) count = symptom_pair.count() if count > 0: frequent_itemsets.append({"symptom_pair": f"{symptom_cols[i]} & {symptom_cols[j]}", "count": count}) return sorted(frequent_itemsets, key=lambda x: x['count'], reverse=True)