事件循环是每个 asyncio 应用的核心。事件循环是许多系统中相当常见的设计模式,已经存在很长时间了。如果你曾经在浏览器中使用 JavaScript 发出异步 Web 请求,你已经在事件循环上创建了一个任务。Windows GUI 应用程序使用所谓的消息循环作为处理键盘输入等事件的主要机制,同时仍然允许 UI 绘制。
最基本的事件循环非常简单。我们创建一个保存事件或消息列表的队列。然后我们永远循环,逐个处理进入队列的消息。在 Python 中,一个基本的事件循环可能看起来像这样:
from collections import dequemessages = deque()while True: if messages: message = messages.pop() process_message(message)
在 asyncio 中,事件循环保存一个任务队列而不是消息队列。任务是协程的包装器。当协程遇到 I/O 密集型操作时可以暂停执行,并让事件循环运行其他不等待 I/O 操作完成的任务。
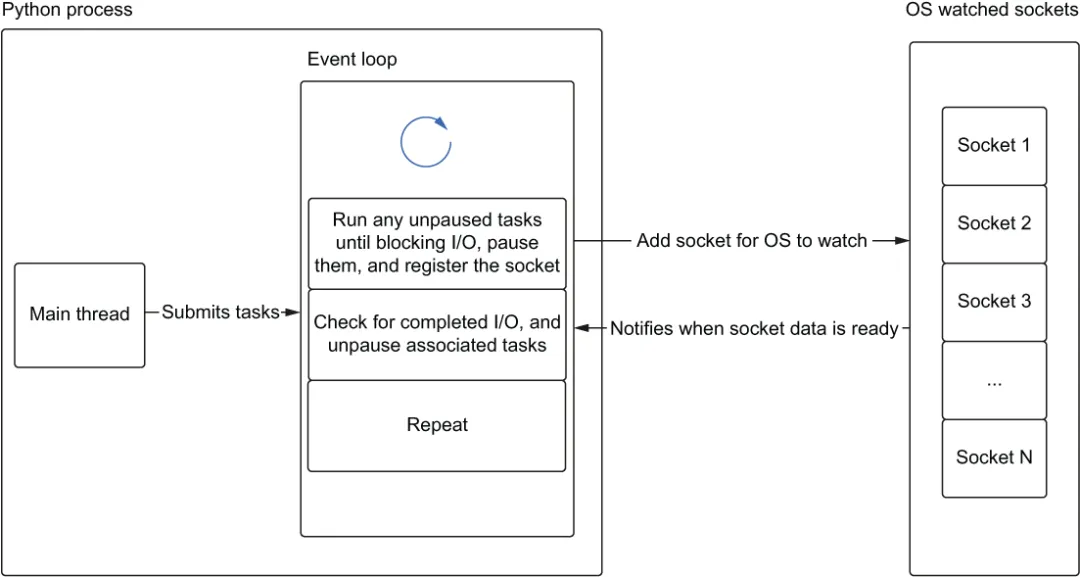
当我们创建一个事件循环时,我们创建一个空的任务队列。然后我们可以将任务添加到队列中运行。事件循环的每次迭代都会检查需要运行的任务,并逐个运行它们,直到一个任务遇到 I/O 操作。那时任务将被“暂停”,我们指示我们的操作系统监视任何套接字的 I/O 完成情况。然后我们寻找下一个要运行的任务。在事件循环的每次迭代中,我们将检查是否有任何 I/O 完成;如果完成,我们将“唤醒”任何暂停的任务并让它们完成运行。我们可以在图 1.9 中这样可视化:主线程将任务提交给事件循环,然后可以运行它们。
为了说明这一点,让我们想象我们有三个任务,每个任务都发出一个异步 Web 请求。想象这些任务有一些设置代码要做,这是 CPU 密集型的,然后它们发出一个 Web 请求,接着是一些 CPU 密集型的后处理代码。现在,让我们将这些任务同时提交给事件循环。在伪代码中,我们会写类似这样的东西:
def make_request(): cpu_bound_setup() io_bound_web_request() cpu_bound_postprocess()task_one = make_request()task_two = make_request()task_three = make_request()
所有三个任务都以 CPU 密集型工作开始,而我们是单线程的,所以只有第一个任务开始执行代码,其他两个等待运行。一旦任务 1 中的 CPU 密集型设置工作完成,它就会遇到一个 I/O 密集型操作,并将暂停自己,说:“我在等待 I/O;任何其他等待运行的任务可以运行。”
一旦发生这种情况,任务 2 就可以开始执行。任务 2 开始其 CPU 密集型代码,然后暂停,等待 I/O。此时,任务 1 和任务 2 都在并发等待它们的网络请求完成。由于任务 1 和任务 2 都暂停等待 I/O,我们开始运行任务 3。
现在想象一下,一旦任务 3 暂停等待其 I/O 完成,任务 1 的 Web 请求已经完成。我们现在被操作系统的事件通知系统提醒这个 I/O 已经完成。我们现在可以在任务 2 和任务 3 都在等待其 I/O 完成时恢复执行任务 1。
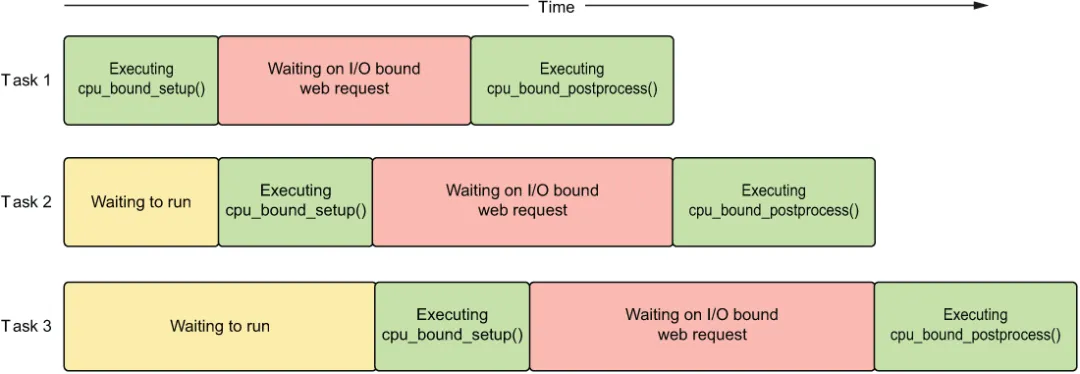
在图 1.10 中,我们展示了刚才描述的伪代码的执行流程。如果我们查看此图的任何垂直切片,我们可以看到在任何给定时间只有一个 CPU 密集型工作正在运行;然而,我们同时有多达两个 I/O 密集型操作正在发生。每个任务等待 I/O 的这种重叠是 asyncio 真正节省时间的地方。
图 1.10 并发执行具有 I/O 操作的多个任务
- CPU 密集型工作主要是利用我们计算机处理器的,而 I/O 密集型工作主要是利用我们网络或其他输入/输出设备的。asyncio 主要帮助我们使 I/O 密集型工作并发,但它也提供了使 CPU 密集型工作并发的 API。
- 进程和线程是操作系统层面最基本的并发单元。在 Python 中,由于 GIL 阻止代码并行执行,进程可以用于 I/O 和 CPU 密集型工作负载,而线程通常只能有效地用于管理 I/O 密集型工作。
- 我们已经看到,通过非阻塞套接字,我们可以在等待数据传入时指示操作系统在数据到达时告诉我们,而不是停止我们的应用程序。利用这一点是 asyncio 仅用单线程实现并发性的部分原因。
- 我们介绍了事件循环,它是 asyncio 应用的核心。事件循环永远循环,寻找具有 CPU 密集型工作要运行的任务,同时也暂停那些正在等待 I/O 的任务。