Playwright Agentic 编程技巧(2)
- 2026-07-06 16:07:27


上一篇文章《Playwright Agentic 编程技巧》为大家介绍了人工智能代理与代理架构——它们是什么以及为什么有用。
本文将继续为大家介绍人工智能的计费标准——理解快速请求与基于令牌的成本之间的区别。
计费清晰度:
高级请求vs. 代币计费
使用AI编码助手时,一个实际考虑因素是如何为其AI模型的使用付费。
不同工具采用了不同的定价模式,主要分为两类:基于请求的(通常称为“高级请求”)和基于代币。
这里我们将用GitHub Copilot作为基于请求定价的示例,以Cursor作为基于代币定价的例子来解释区别。
GitHub Copilot – 基于请求的“高级请求”定价
GitHub Copilot 对 AI 辅助定价围绕请求构建。本质上,每次你提示AI做某事,都算作一个请求。
例如,在副驾驶聊天或代理模式下,每个用户提示都会从你的配额中消耗一个请求。
这些请求有时被非正式地被称为“快速请求”或高级请求,尤其是当它们使用了超出默认型号的高级型号时。
Copilot 的计划包含每月一定数量的此类请求:
免费计划:
每月限制50次AI聊天/智能体请求(及2000个代码完成建议)
专业版(付费)套餐:
基础型号提供无限基础完成和聊天,并可为更强型号提供高级请求(例如:Pro版为约300次,Pro+根据套餐倍数约1500次)。使用高级模型(如GPT-5或Sonnet 4)会减少配额,有时由于模型乘数,单次查询甚至会消耗多个配额。
如果你用完了 Copilot 的月度高级申请额度,也不会完全被切断使用——你可以继续使用附带的基础型号(GPT-4.1/GPT-5 mini),无需额外费用,尽管可能会有较慢或受限速率的响应。
不过,超出计划包含量使用任何更高端的模型都需要启用付费超额。Copilot 在你超出计划包含量后,每额外请求收费约 $0.04。许多用户默认预算为 $0,这意味着除非你选择支付更多费用,否则 Copilot 将拒绝进一步的高级请求。
实际上,每次你在 Copilot 聊天中点击“继续”以获取更多输出或重试解决方案时,都会触发一个新请求——消耗你配额中的另一个单位。
这意味着迭代方案可能会消耗多个请求。例如,用户指出,反复请求Copilot修改代码可能需要花费10+次请求才能最终得出正确答案。
每个提示或后续(“高级”)请求在你的配额(或购买更多时的钱包)中都有固定费用。
优缺点:
请求模型简单明了:你按尝试付费,而不是按回复长度付费。这对非常大的输出很有利——无论你的AI写的是10行还是100行代码,它都会计入你的配额。
不过,如果你需要多次尝试,可能会感到沮丧。即使是失败或重复尝试,每次都算作独立请求,这会迅速消耗你的使用额度,同时不影响你继续使用该服务。
简而言之,Copilot的“高级请求”定价更偏向一次性完成的大任务。不幸的是,存在工具调用限制,通常需要点击“继续”以获取更多输出或重试解决方案,这会触发新的请求——消耗你配额中的另一个单位。
Cursor——基于代币的定价(基于使用量)
Cursor 最初采用类似的基于请求的配额系统(例如 Pro 用户每月有 500 次“快速请求”,额外调用每次$0.04)。
然而,在 2025 年中期,他们改为基于代币的使用定价模式,以实现更清晰和公平(官方说法)或为了赚取更多收入(非官方说法)。
Cursor Pro 不再统计请求数量,而是包含每月积分(例如价值 20 美元的 AI 使用),以实际代币消耗为单位,并根据每次查询的实际计算成本收费。
实际上,其运作方式如下:
专业版计划每月包含一定金额的“Frontier型号使用量”(例如20美元)。这个积分大致相当于典型使用下约225 次 Sonnet 4 请求、550 次 Gemini 请求或 约500 个 GPT 5 请求分配,但现在是以 API 成本(代币)计算,而非固定调用数。
你在Cursor中执行的每一次AI作,都会根据处理的代币数量(字符/单词)从积分中扣除一定金额。
使用更多代币的重任务(更长的代码生成、庞大的上下文、复杂的分析)会消耗更多额度;较轻松任务消耗很少。
本质上,你按AI的工作量按比例付费,而不仅仅是按操作次数计费。
只要你保持在每月额度内使用,就不会额外支付订阅费用。如果用完,你可以选择按成本价支付额外使用费用(与AI提供商收费相同)。Cursor 允许你设置支出上限,除非你启用超额,否则不会被超额费用吓到。
在基于代币的定价下,单次请求的成本不再固定——可能只需几美分一个零头,或者如果请求大量输出,可能比以前的0.04美元更高。
例如,一个简单的问题可能花费约为0.003美元,而非常复杂的代码生成可能花费更多(甚至高达几美元)。
代币计费试图使使用过程透明化。然而,提前估算单个请求的成本很难,这也引发了关于其透明度的诸多争议。优缺点:
基于代币的方法通常更细致且公平,适用于多种用例。
你本质上是按AI服务的使用量付费。这意味着不再有任意的“500个请求”上限——你的计划可能覆盖相当于5万个AI代币的产出。如果你只使用小提示,就不会每次都提示浪费额度。
相反,如果你释放AI执行一个需要大量上下文窗口的复杂任务,你会相应消耗更多包含的额度(而在固定每次请求费用的情况下,这可能反而是划算的)。
简而言之,基于代币的定价使成本与实际计算努力相匹配,为服务提供商提供更多可预测性,也为用户提供更多灵活性。
总结
下表总结了两种定价模型的主要区别:
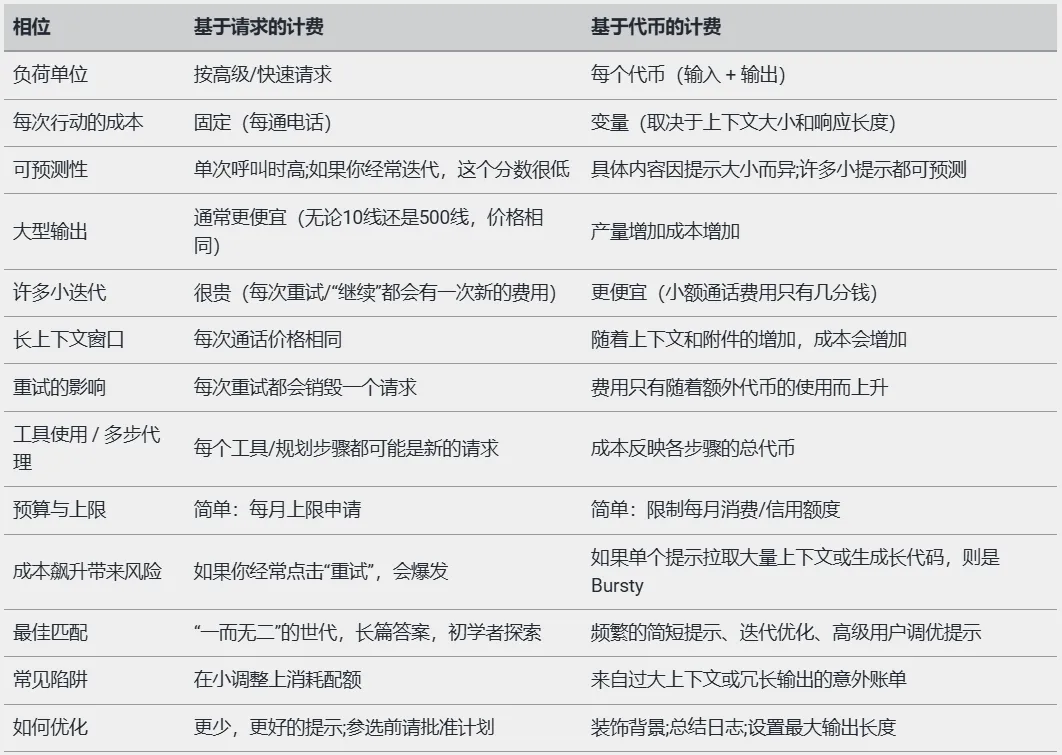
我认为基于请求的定价模式更适合初学者,而基于代币的定价模式更适合希望控制成本的高级用户。
如果你想“氛围编程”,选择基于请求的定价。
如果你有Gemini/ChatGPT订阅,选择基于代币的定价。用Gemini/ChatGPT生成计划,然后用 Cursor 实现。

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 编程专业,该改名叫“提示词工程”了
- 国内AI编程助手怎么选?CodeBuddy以高效编程赋能开发者,实现终端开发智能化
- 国家送的 编程神器!编程小白不用就是浪费
- 我差点信了!直播间卖的编程课,“升学饼”画得有多大?
- 看不懂代码,不知道哪家公司,财险公司代码速查,适合车主更适合车险同行,一键收藏
- 2026寒假Ai伴学营+英语机器人编程特色课
- AI 编程终于有了 “npm”!Vercel Agent Skills 让 AI 秒变前端专家,1 行命令搞定 10 年经验
- 学校开了编程课,我们还需要课外集训吗?
- 体验课招募丨新艺培训机器人编程、舞蹈体验课来袭,快来报名体验吧!
- 深圳学CNC数控编程认准鼎才!实战教学+名企内推,高薪就业有保障
