大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构!
关注、发送C1即可获取JetBrains全家桶激活工具和码!
有些人刷短视频解压,有些人刷八卦上头,而有的人(懂的都懂)会定期翻 OpenJDK 的 commit log——属于那种“看别人修 bug 也能获得快乐”的硬核爱好。最近就有这么一个提交,能让人滑着滑着突然停住:一个几十行的小修,直接把 30x–400x 的性能差距抹平了。
提交信息长这样(链接转纯文本): https://github.com/openjdk/jdk/commit/858d2e434dd
 image
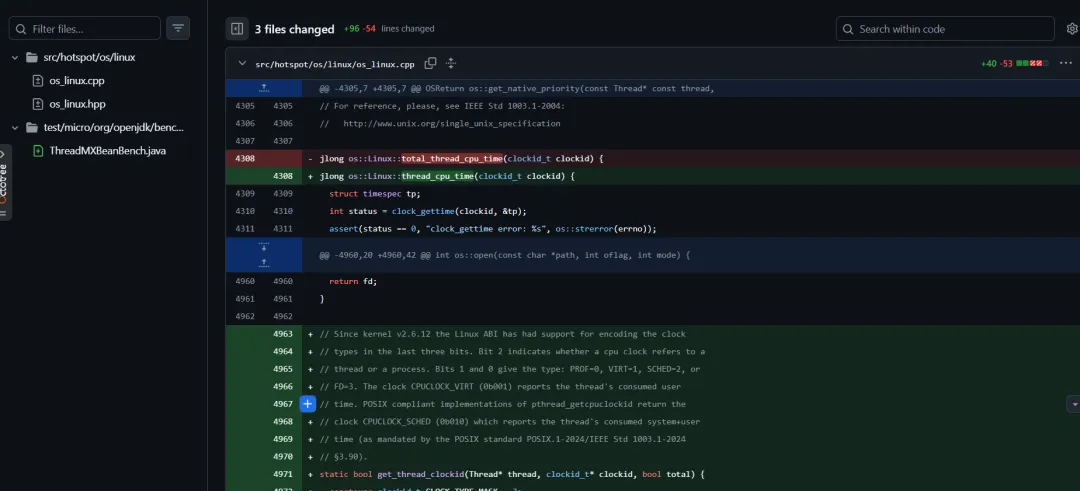
image关键点一句话:Linux 下 ThreadMXBean.getCurrentThreadUserTime() 以前走 /proc 读文件+解析,现在改成 clock_gettime() 一把梭。听着朴实无华,但效果非常“离谱地好”。
这锅到底有多大
同门两兄弟,一个像跑车,一个像拖拉机
先认识两位主角:
ThreadMXBean.getCurrentThreadCpuTime():拿“当前线程总 CPU 时间”(user + system)ThreadMXBean.getCurrentThreadUserTime():只拿“当前线程 user 时间”
你可能会以为:两者应该差不多吧?都是“线程 CPU 时间”嘛。 结果历史实现告诉你:想多了。
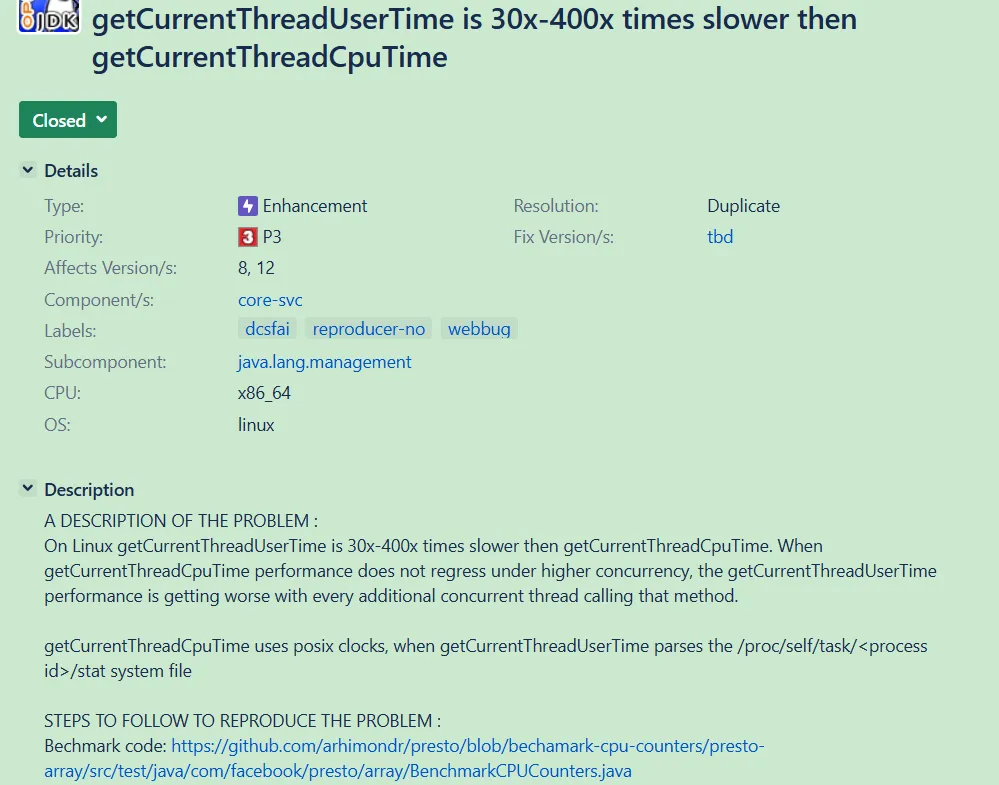
原始 bug 报告直接给出差距: https://bugs.openjdk.org/browse/JDK-8210452
 image
image里面量化得很狠:
❝getCurrentThreadUserTime 比 getCurrentThreadCpuTime 慢 30x–400x
并发一上来,差距还会被放大,属于“越忙越慢,越慢越崩”。
旧实现
为了拿个 user time,JVM 竟然去读 /proc
旧版 Linux 实现藏在 os_linux.cpp 里,本质流程是:
- 拼路径
/proc/self/task/<tid>/stat - 处理一个“恶意格式”:线程名里可能有括号,所以要找最后一个
) sscanf() 抽第 13/14 个字段(user/sys tick)
那段被删掉的代码大概长这样
static jlong user_thread_cpu_time(Thread *thread) {
pid_t tid = thread->osthread()->thread_id();
char *s;
char stat[2048];
size_t statlen;
char proc_name[64];
int count;
long sys_time, user_time;
char cdummy;
int idummy;
long ldummy;
FILE *fp;
os::snprintf_checked(proc_name, 64, "/proc/self/task/%d/stat", tid);
fp = os::fopen(proc_name, "r");
if (fp == nullptr) return -1;
statlen = fread(stat, 1, 2047, fp);
stat[statlen] = '0';
fclose(fp);
// Skip pid and the command string. Note that we could be dealing with
// weird command names, e.g. user could decide to rename java launcher
// to "java 1.4.2 :)", then the stat file would look like
// 1234 (java 1.4.2 :)) R ... ...
// We don't really need to know the command string, just find the last
// occurrence of ")" and then start parsing from there. See bug 4726580.
s = strrchr(stat, ')');
if (s == nullptr) return -1;
// Skip blank chars
do { s++; } while (s && isspace((unsigned char) *s));
count = sscanf(s,"%c %d %d %d %d %d %lu %lu %lu %lu %lu %lu %lu",
&cdummy, &idummy, &idummy, &idummy, &idummy, &idummy,
&ldummy, &ldummy, &ldummy, &ldummy, &ldummy,
&user_time, &sys_time);
if (count != 13) return -1;
return (jlong)user_time * (1000000000 / os::Posix::clock_tics_per_second());
}
看到这里你大概已经开始皱眉:为了拿一个时间,居然要走文件系统、内核拼字符串、用户态 sscanf 解析……这不是性能敏感路径里最忌讳的“豪华套餐”吗?
对比:CPU time 那位“亲兄弟”一直就很优雅
同样是拿时间,getCurrentThreadCpuTime() 从古至今都干净得像刚洗完的盘子:
jlong os::current_thread_cpu_time() {
return os::Linux::thread_cpu_time(CLOCK_THREAD_CPUTIME_ID);
}
jlong os::Linux::thread_cpu_time(clockid_t clockid) {
struct timespec tp;
clock_gettime(clockid, &tp);
return (jlong)(tp.tv_sec * NANOSECS_PER_SEC + tp.tv_nsec);
}
一句 clock_gettime(),没有文件 IO、没有解析、没有一堆 syscalls 组合拳。
为什么差这么多:一次 syscall vs 一串 syscall + VFS + 字符串 + 解析
旧 /proc 路径大概干了这些活:
close() syscall(还可能牵扯锁、futex 等)
而 clock_gettime(CLOCK_THREAD_CPUTIME_ID) 路径基本是:
- 单次 syscall → 直接走内核里一条更短的函数链,读调度实体里的时间信息
所以差距不在“要不要进内核”(两者都要),而在进内核之后做了多少额外工作。
那问题来了:当年为啥不用 clock_gettime 拿 user time?
答案很“标准化”:POSIX 规定 CLOCK_THREAD_CPUTIME_ID 返回的是总 CPU 时间(user + system)。 “只要 user 时间”这件事,在 POSIX 意义上并没有一个通用开关。
但 Linux 有自己的“私房菜”:clockid_t 的位编码。这个编码在 Linux 内核里稳定很多年,但你在 man page 里不一定能看到它的完整说明——要想懂,得看内核源码那种“祖传注释”。
新实现
用 pthread_getcpuclockid 拿到 clockid,再把类型位翻成 VIRT(user-only)
Linux 从 2.6.12(2005 年)开始,就在 clockid_t 里编码了“时钟类型/线程或进程”等信息。pthread_getcpuclockid() 会给你一个 POSIX 合规的 clockid(通常是 SCHED:user+system)。 接着只要把低位类型从 10 翻成 01(VIRT:user-only),再交给 clock_gettime(),就能得到 user time。
新代码核心如下:
static bool get_thread_clockid(Thread* thread, clockid_t* clockid, bool total) {
constexpr clockid_t CLOCK_TYPE_MASK = 3;
constexpr clockid_t CPUCLOCK_VIRT = 1;
int rc = pthread_getcpuclockid(thread->osthread()->pthread_id(), clockid);
if (rc != 0) {
// Thread may have terminated
assert_status(rc == ESRCH, rc, "pthread_getcpuclockid failed");
returnfalse;
}
if (!total) {
// Flip to CPUCLOCK_VIRT for user-time-only
*clockid = (*clockid & ~CLOCK_TYPE_MASK) | CPUCLOCK_VIRT;
}
returntrue;
}
static jlong user_thread_cpu_time(Thread *thread) {
clockid_t clockid;
bool success = get_thread_clockid(thread, &clockid, false);
return success ? os::Linux::thread_cpu_time(clockid) : -1;
}
对比旧实现:
- syscalls 数量也从“一串”变成“基本一个”
简直是“删代码删出性能”。
真实性能:从 11 微秒降到 279 纳秒,直接 40 倍起飞
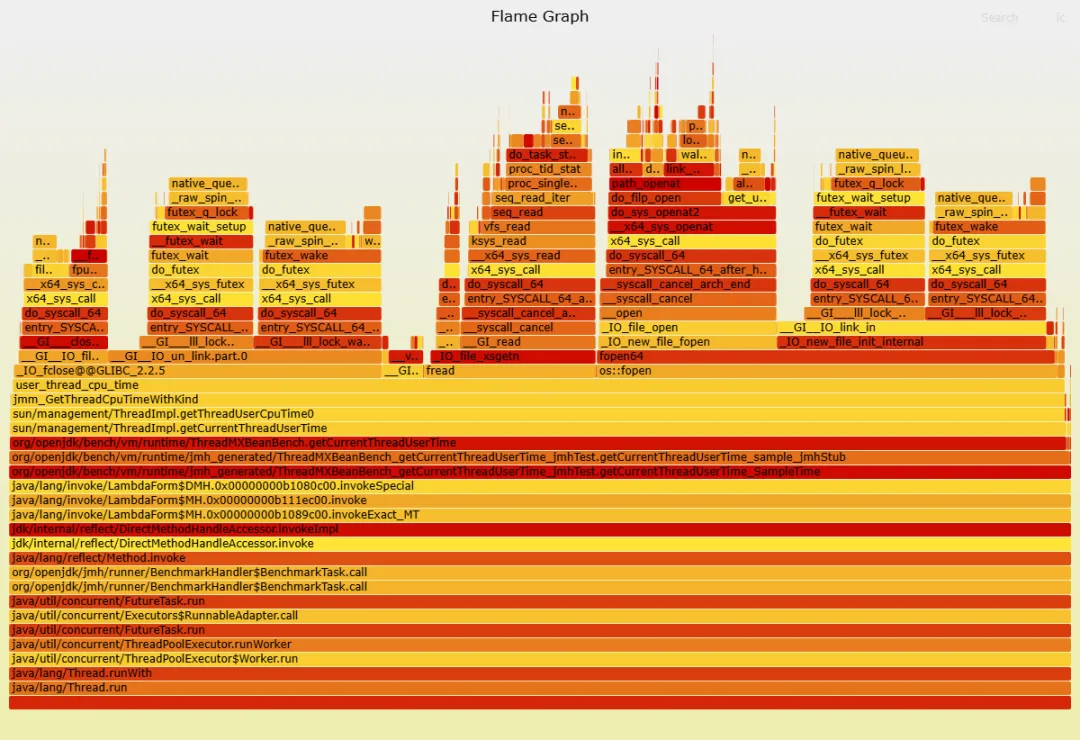
为了量化差距,修复里还顺手带了 JMH benchmark(这点很加分:没有基准的优化,容易变成自我感动)。
原 benchmark 示例:
@State(Scope.Benchmark)
@Warmup(iterations = 2, time = 5)
@Measurement(iterations = 5, time = 5)
@BenchmarkMode(Mode.SampleTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Threads(16)
@Fork(value = 1)
public class ThreadMXBeanBench {
static final ThreadMXBean mxThreadBean = ManagementFactory.getThreadMXBean();
static long user; // To avoid dead-code elimination
@Benchmark
public void getCurrentThreadUserTime() throws Throwable {
user = mxThreadBean.getCurrentThreadUserTime();
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(ThreadMXBeanBench.class.getSimpleName())
.build();
new Runner(opt).run();
}
}
旧版本(/proc 路径)结果大意是:平均 ~11 微秒。 修复后结果:平均 ~0.279 微秒(也就是 279 纳秒)。 算下来差不多 40x 改善(在 30x–400x 区间内,符合历史报告范围)。
配套 profile 也很直观:旧版像“syscall 自助餐”,新版像“只吃一道菜”。
 image
image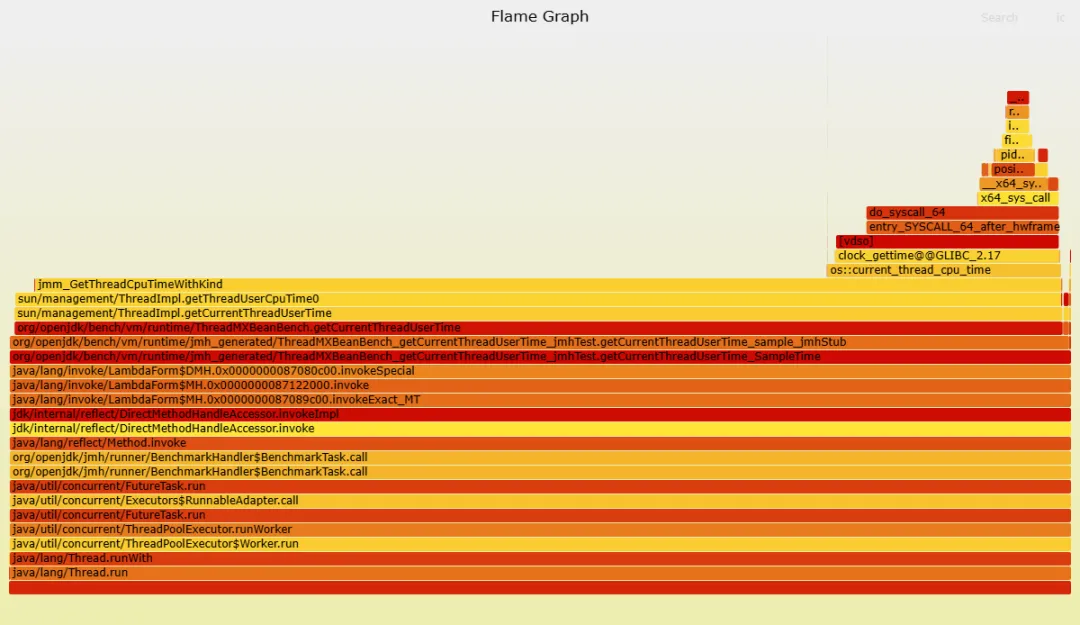 image
image
彩蛋:还能再榨出 13%?内核 fast-path:PID=0 时跳过 radix tree 查找
性能到了纳秒级还继续抠?这就很“工程师”。 在修复后的 profile 里还能看到一个小热点:内核里会做一次 radix tree lookup 去定位目标线程的 pid 结构。原因是:pthread_getcpuclockid() 返回的 clockid 编码了具体 TID,内核拿到后要去查。
但内核有个更快的分支:如果 clockid 里编码的 PID/TID 是 0,内核把它解释成“当前线程”,直接走 current task,跳过查找。
/*
* Functions for validating access to tasks.
*/
static struct pid *pid_for_clock(const clockid_t clock, bool gettime)
{
[...]
/*
* If the encoded PID is 0, then the timer is targeted at current
* or the process to which current belongs.
*/
if (upid == 0)
// the fast path: current task lookup, cheap
return thread ? task_pid(current) : task_tgid(current);
// the generalized path: radix tree lookup, more expensive
pid = find_vpid(upid);
[...]
于是有人提出一个“更野但更快”的想法:既然 OpenJDK 已经在改 clockid 的低位类型了,那干脆自己构造一个 PID=0 的 clockid 走 fast-path。
clockid 编码示意:
clockid (原理示意):
// Linux Kernel internal bit encoding for dynamic CPU clocks:
// [31:3] : Bitwise NOT of the PID or TID (~0 for current thread)
// [2] : 1 = Per-thread clock, 0 = Per-process clock
// [1:0] : Clock type (0 = PROF, 1 = VIRT/User-only, 2 = SCHED)
static_assert(sizeof(clockid_t) == 4, "Linux clockid_t must be 32-bit");
constexpr clockid_t CLOCK_CURRENT_THREAD_USERTIME = static_cast<clockid_t>(~0u << 3 | 4 | 1);
然后把 getCurrentThreadUserTime() 直接改为用这个 CLOCK_CURRENT_THREAD_USERTIME 调 clock_gettime()。
结果呢?benchmark 从 81.7ns 降到 70.8ns,约 13% 提升。 绝对值不大,但属于“白给的快”。
当然,这也带来一个工程上的灵魂拷问:为了这点收益,值不值得在 JVM 里依赖更多 Linux 内核 ABI 细节?这类优化就很像把车轮胎气压从 2.3 调到 2.35:能快,但你得接受“更挑环境”的风险感。
三条硬核经验:写性能代码时,别只信标准,别只信直觉
这次修复能这么漂亮,背后有三条特别“值钱”的经验:
1)别只读 POSIX,要敢读内核源码标准告诉你“可移植的下限”,内核源码告诉你“可用的上限”。两者之间有时差着 400 倍。
2)别迷信老实现里的假设当年的 /proc 解析可能是合理折中,但假设会“固化”成代码,一固化就是十几年。隔段时间回头看,往往能捡到大便宜。
3)优化要带基准,要留证据这次提交很关键的一点:带了 JMH benchmark。否则这种改动很容易被质疑为“玄学改法”。
结尾:JDK 26 可能给你“免费加速包”
这个改动在 2025-12-03 落地,距离 JDK 26 冻结只差一天。文章里也给了时间点:JDK 26 预计 2026 年 3 月发布。 如果你的系统里确实用到了 ThreadMXBean.getCurrentThreadUserTime()(比如 profiling、监控、诊断工具链),那这波升级基本等于:白捡一个数量级的延迟下降。
喜欢就奖励一个“👍”和“在看”呗~
 image
image专属付费版全家桶
如果你只是激活JetBrains全家桶IDE,那这个应该是目前最经济、最实惠的方法了!
专属付费版全家桶除了支持IDE的正常激活外,还支持常用的付费插件和付费主题!
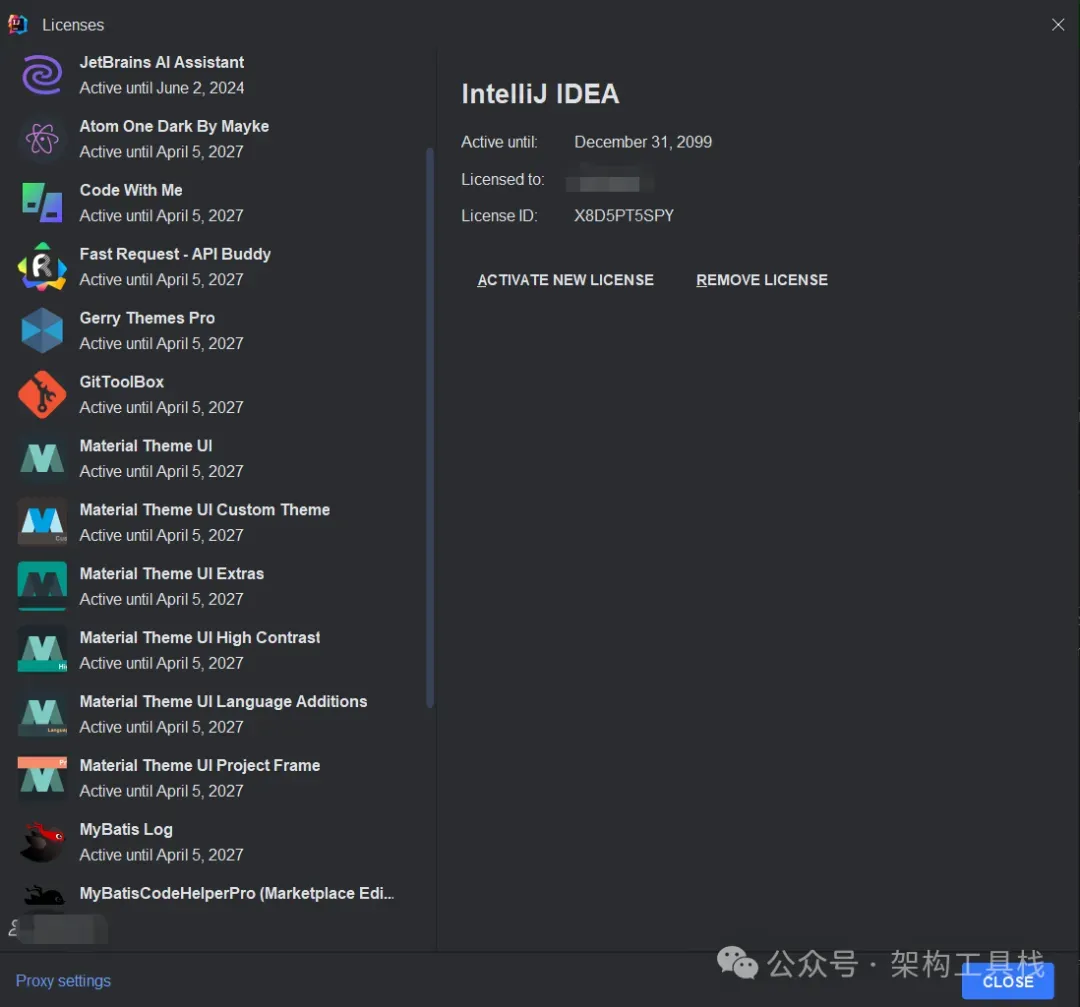 全家桶+付费插件授权
全家桶+付费插件授权100%保障激活,100%稳定使用,100%售后兜底!
为什么说专属付费版全家桶最经济、最实惠?
因为专属付费版全家桶支持常用付费插件和付费主题。而任意一款或两款付费插件或付费主题,其激活费用就远高于我提供的专属付费版全家桶。
比如,最方便的彩虹括号符Rainbow Brackets,124/年。
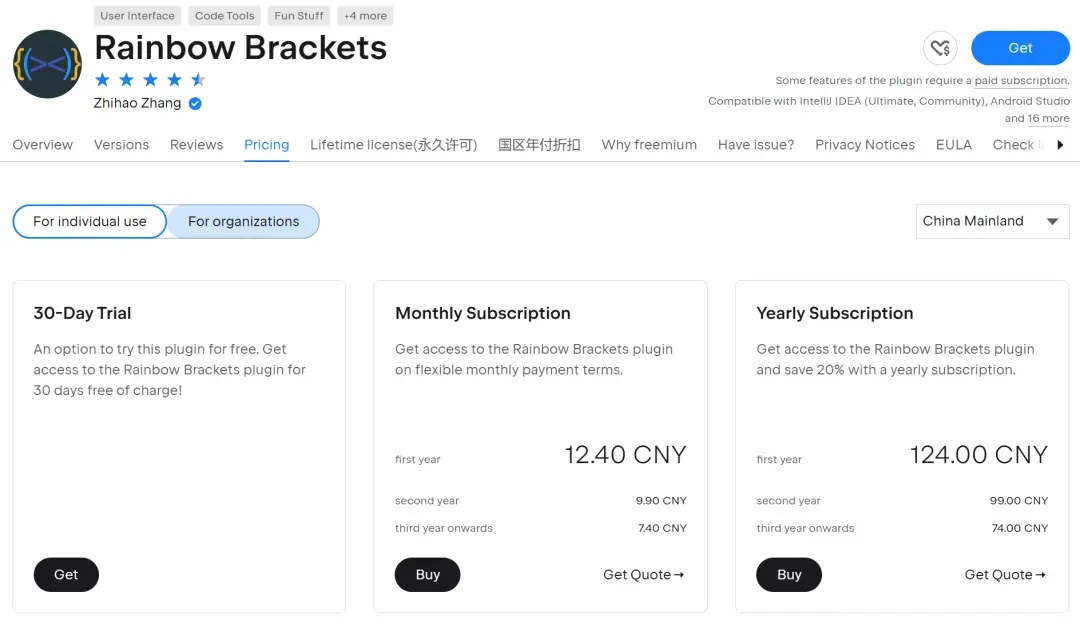 Rainbow Brackets
Rainbow Brackets再如,MyBatis最佳辅助框架MyBatisCodeHelperPro的官方版本MyBatisCodeHelperPro (Marketplace Edition),157/年。
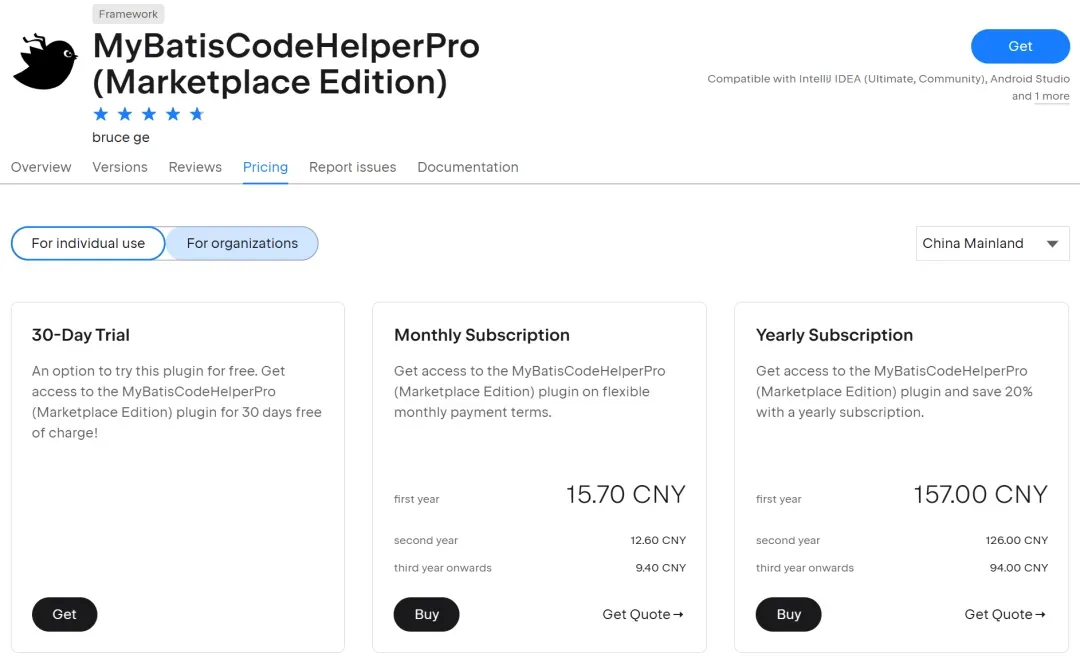 MyBatisCodeHelperPro
MyBatisCodeHelperPro还有最牛的Fast Request,集API调试工具 + API管理工具 + API搜索工具一体!157/年。
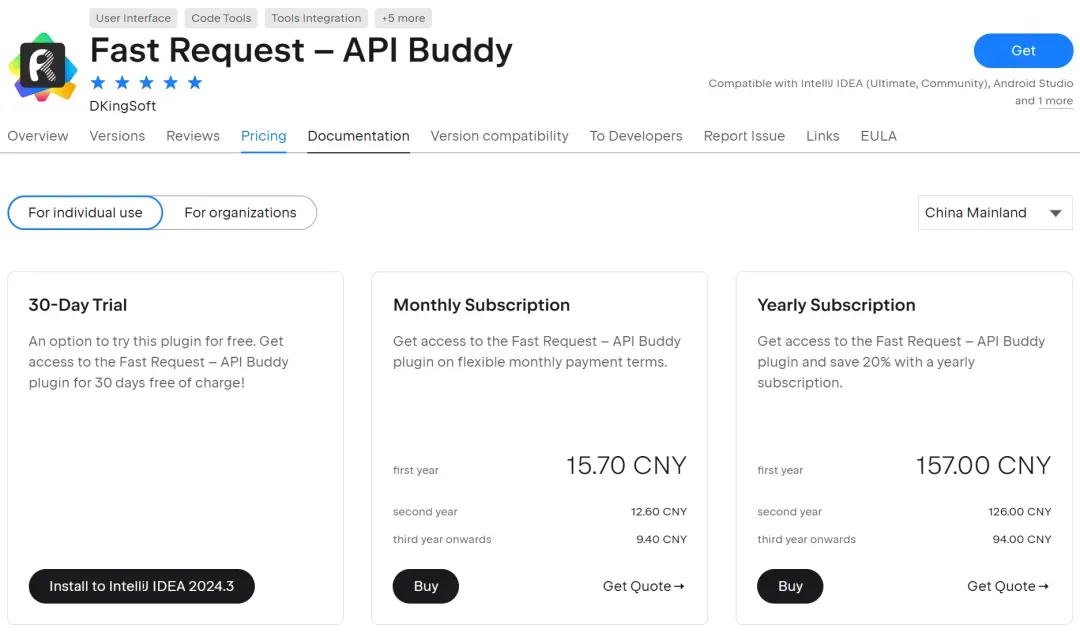 Fast Request
Fast Request`专属付费版全家桶`包含上述这些付费插件,但不限于上述这些付费插件!
需要的小伙伴,可以扫码二维码,回复付费,了解优惠详情~
 付费获取方式
付费获取方式 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
