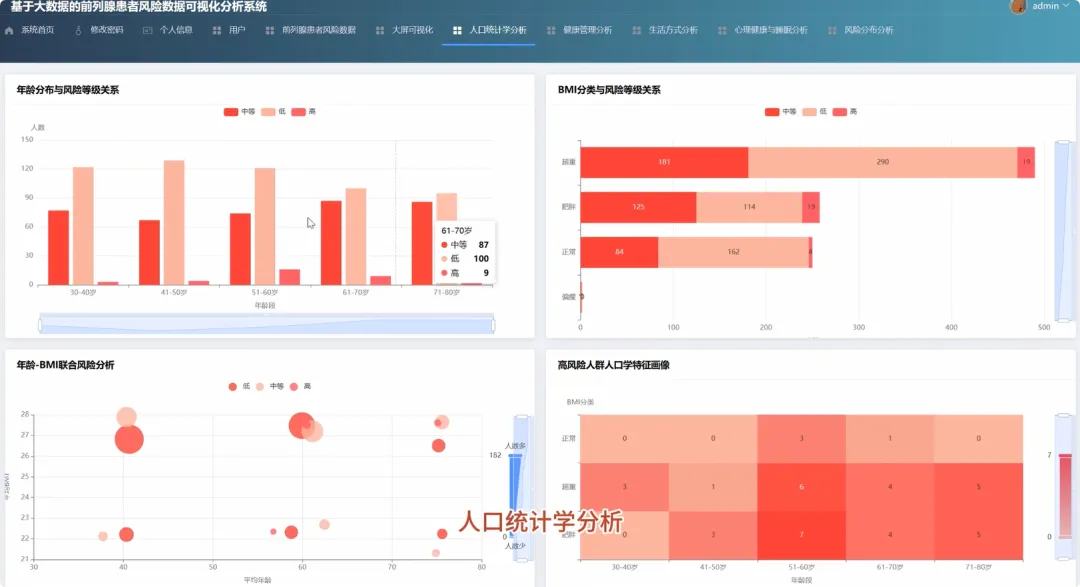
from pyspark.sql import SparkSessionfrom pyspark.sql.functions import when, col, sum as _sumfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.clustering import KMeansspark = SparkSession.builder.appName("ProstateRiskAnalysis").getOrCreate()df = spark.read.csv("hdfs://path/to/data", header=True, inferSchema=True)# 功能1.1: 年龄分布与风险等级关系分析df_age_group = df.withColumn("age_group", when((col("age") >= 30) & (col("age") <= 40), "30-40").when((col("age") >= 41) & (col("age") <= 50), "41-50").when((col("age") >= 51) & (col("age") <= 60), "51-60").when((col("age") >= 61) & (col("age") <= 70), "61-70").when((col("age") >= 71) & (col("age") <= 80), "71-80").otherwise("other"))age_risk_analysis = df_age_group.groupBy("age_group", "risk_level").count().orderBy("age_group", "risk_level")age_risk_analysis.show()# 功能2.5: 生活方式综合评分分析df_lifestyle_score = df.withColumn("smoker_score", when(col("smoker") == "yes", 0).otherwise(1))df_lifestyle_score = df_lifestyle_score.withColumn("alcohol_score", when(col("alcohol_consumption") == "high", 0).when(col("alcohol_consumption") == "medium", 1).otherwise(2))df_lifestyle_score = df_lifestyle_score.withColumn("diet_score", when(col("diet_type") == "high_fat", 0).when(col("diet_type") == "mixed", 1).otherwise(2))df_lifestyle_score = df_lifestyle_score.withColumn("activity_score", when(col("physical_activity_level") == "low", 0).when(col("physical_activity_level") == "medium", 1).otherwise(2))df_lifestyle_score = df_lifestyle_score.withColumn("lifestyle_score", col("smoker_score") + col("alcohol_score") + col("diet_score") + col("activity_score"))lifestyle_avg_score = df_lifestyle_score.groupBy("risk_level").avg("lifestyle_score").orderBy("risk_level")lifestyle_avg_score.show()# 功能5.4: 高风险人群特征聚类分析high_risk_df = df.filter(col("risk_level") == "high").select("age", "bmi", "sleep_hours")assembler = VectorAssembler(inputCols=["age", "bmi", "sleep_hours"], outputCol="features")high_risk_features = assembler.transform(high_risk_df)kmeans = KMeans(k=3, seed=1)model = kmeans.fit(high_risk_features)cluster_centers = model.clusterCenters()print("High-Risk Patient Cluster Centers:")for center in cluster_centers: print(center)






















 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
