如何让8B模型完成写代码-洞察数据-出报告
对这篇DeepAnalyze[1]论文感兴趣是作者通过三阶段训练模型,在8B参数小模型就能完成“理解数据需求→写代码分析十个csv、excel、sqlite数据文件→生成洞察报告”的全流程。在如此小的模型上,训练方法是什么?开放性问题可以用RL?多少数据可以收敛?本文尝试回答这些问题并展开了一些思考:
- • 为什么需要三阶段训练方法,冷启动存在的必要性?
- • 工作流 vs Agentic 模型训练,应该怎么选?
- • GRPO的奖励函数,Sreport(o)是怎么算的?
- • 本文也尝试回答,如何使用自己的数据去微调|入户训练数据分布的艺术
论文开源了训练数据,模型,甚至放出了三阶段训练脚本,奖励模型代码,未来我们去做别的Agentic训练时可以快速用上。
数据探索问题举例:
prompt:请对提供的支付数据集及配套文档展开分析,撰写一份全面的数据洞察报告。 报告需明确商户交易成本与欺诈风险的核心驱动因素,探究交易特征(如授权特征码、卡组织类型、交易金额)、商户档案信息(如账户类型、商户类别码、收单机构选择)及交易行为模式(如交易时段、跨境交易属性)三大维度,对支付处理手续费及欺诈拒付事件的影响机制。 本次分析的核心目标是提炼出可落地的实践洞察,助力商户优化支付配置与运营策略,实现成本最小化与风险可控化。 翻译说明 actionable insights 译为可落地的实践洞察,而非字面的 “可操作的洞察”,更贴合商业报告语境,突出 “能直接指导实操” 的属性。 payment configurations 译为支付配置,涵盖商户在卡组织选型、收单机构合作、交易验证方式等方面的设置。 fraudulent disputes 译为欺诈拒付事件,精准对应 “持卡人因交易欺诈发起的拒付申请” 这一业务场景。 句式调整:英文原文为长句结构,翻译时拆分为符合中文报告写作习惯的短句,同时保留 “探究… 影响机制”“实现… 目标” 等正式表述。
文件:几个Excel、sqlite、csv等,大小为几十MB的文件。
下面三个图,你能区分哪个答案对应deep-analyze8b、deepseek-r1、gpt-mini-o3吗?
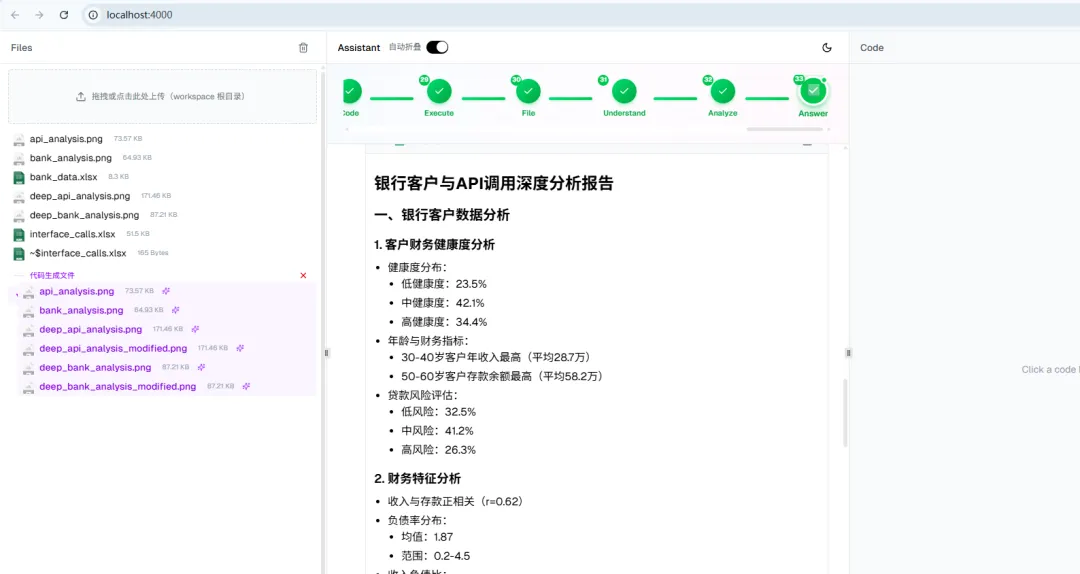
开源代码跑起来后如下图:代码中包含了运行框架,添加正确的模型配置即可运行,拖入一系列待分析的xlsx、csv等。
第一部分:Introduction ~ Related Work
当前主流的数据科学 Agent(如基于 ReAct、LangChain 的应用)本质上严重依赖外部的 Prompt Engineering 和预定义工作流。这种“外挂大脑”的模式在处理简单查询时有效,但在面对复杂的结构化数据全流程分析时,常因上下文窗口限制或指令遵循漂移而失效,同时,缺乏自主编排和适应性优化。
DeepAnalyze 提出了一种训练范式:Agentic Training(智能体训练,这不是作者首创,而是说作者在合成数据、架构设计上做出来了)。与其依赖复杂的外部 Prompt 诱导模型行为,不如将数据清洗、探索、建模的决策能力直接“内化”到模型的参数中。DeepAnalyze-8B 是首个专门为此设计的 Agentic LLM,它不依赖死板的工作流,而是具备真正的自主编排能力,能够在没有明确步骤指引的情况下,独立完成从原始数据到分析师级报告的全过程。
模型、代码、数据(DataScience-Instruct-500K)全开源.
论文提出deepanalyze 可以解决开放性任务如:生成一份报告,总结数据中的任何显著趋势、发现或摘要。
- 💡 为什么强化学习在 Coding 和 Math 领域的应用较多? 因为这两个领域奖励函数天然可良好定义,coding好不好,跑一跑就知道(当然还有其他规则),数学题做的对不对,直接知道答案。然而例如数据报告领域、客服问答领域,RL环境较难模拟,答案需要人工标注无标准答案。
- LangChain 放出的 DeepAgents,Dify 上支持的 DeepSearch 工作流,被称之为Workflow-based Agent 或 Long-Context Framework,与本文的Agentic Model Fine-tuning在执行长任务,以及开放性任务是有本质的区别。
工作流智能体 vs DeepAnalyze:
- • Workflow-based Agent:
这让我想起阿里deep research论文,不但使用三段式模型训练方法,还加入了CPT,continue pre-training范式。
- • 在开放性问题中的缺陷:开放性问题(如“从这份数据中挖掘有价值的洞察”)缺乏明确的步骤指引。Workflow-based Agent 必须依赖外部显式地将大目标拆解为子步骤。如果预定义的 Workflow 没有覆盖某种探索路径,或者 Prompt 无法精确指导如何进行无目标的探索,Agent 就会因为缺乏“下一步指令”而失效或陷入死循环。
- • 机制:依赖于预定义的流程图(Predefined Workflows)或启发式提示。即使是 ReAct 框架,其本质也是通过 System Prompt 强制模型遵循 "Thought-Act-Observe" 的固定循环。或是我们在类coze、dify上拖出工作流,或用ReAct框架去跑,System Prompt编写持续膨胀,指令遵循愈发困难。每次发布陷入玄学怀疑。
- • 依赖上下文管理。错误信息或环境反馈被作为纯文本追加到对话历史中,再次输入给模型,这里愈发依赖大尺寸模型的通用能力。
- • DeepAnalyze(自主编排/训进模型):
- • 机制:将决策逻辑转化为概率模型。通过RL,在任意给定的环境状态下,模型不是遵循固定流程,而是计算当前采取哪种 Action(如 Analyze, Code, Understand)能够最大化长期累积回报。
- • 优势:这种决策是端到端(End-to-End)的。模型不需要外部告诉它“先看列名,再画图”,它根据参数中内化的经验,自主决定在未知的数据环境中如何探索,从而实现了真正的自主编排。
下图展示了一个开放性问题不同模型的运行结果。

FAQ:
- 1. 什么是轨迹数据:即先做什么后做什么的一系列流程。如先写python读取数据,再看列名,聚类数据,挖掘平均值、TopN.
- 2. 奖励稀疏是什么意思?
不同于数学或编程题有标准答案,数据分析报告的“质量”难以量化,模型在长链路探索初期很难获得有效的正向反馈。我的理解这是冷启动要解决的问题
第二部分. DeepAnalyze 架构与训练方法
DeepAnalyze 摒弃了外部 ReAct 循环,直接通过扩展 LLM 词表,引入 , , , , 五个原生动作 Token。这种设计将“思考-执行-观察”转化为模型内部的自回归概率选择,其中 动作强制模型在写代码前主动读取数据结构,显著降低了幻觉。
训练好的模型按如下方式运行:
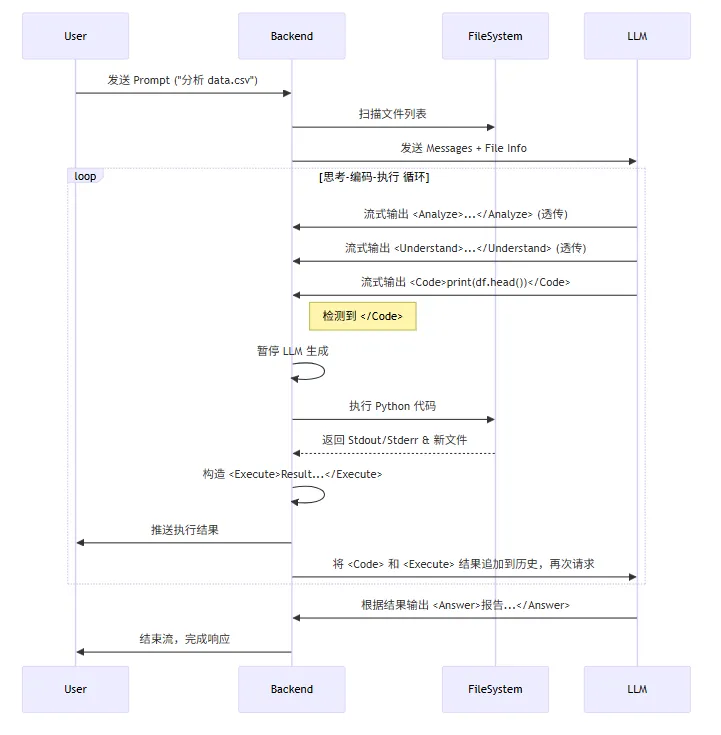
💡这非常有意思,我们可以模仿他的架构设计自己的动作,用来训练自己垂直领域的模型。- 如客服领域,把改写、搜索、召回、润色寻到一个Agentic 模型中。
2.1 三阶段训练
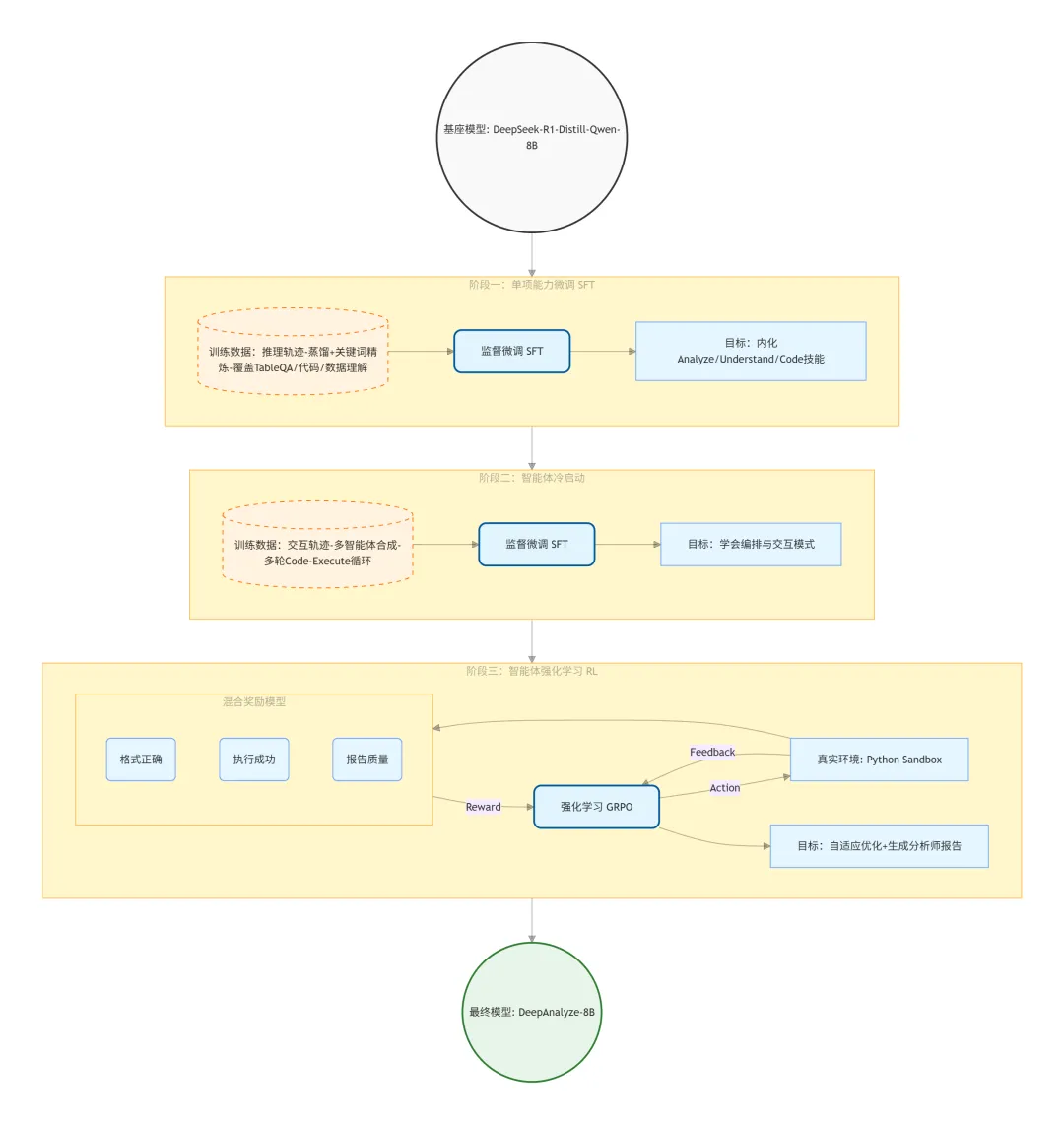
阶段一 SFT:470k 数据
数据来源:通过“蒸馏+精炼”生成的推理数据。让模型先学会怎么读表(Understand)、怎么写代码(Code)、怎么推理(Analyze),防止在后期复杂交互中连基本代码都写不对。
通用推理基座 - 约 10 万条
论文 3.4 节明确提到:"we employ... 100K general reasoning samples from AM-DeepSeek-R1-0528-Distilled"。这部分数据用于防止模型在垂直领域微调时遗忘通用的逻辑推理能力。目标是建立模型的基础 CoT(思维链)能力,确保模型“会思考”。
- • reasoning/math_20000.json (数学)
- • reasoning/code_20000.json (通用代码)
- • reasoning/science_20000.json (科学常识)
- • reasoning/instruction_following_20000.json (指令遵循)
- • reasoning/other_19998.json (其他)
结构化知识增强 (Structured Knowledge Grounding) - 约 20 万条
训练模型理解结构化数据(表格、知识图谱)到文本的映射,强化 动作的能力,让模型学会“读表”
表格问答与推理合成 - 8万条
作者不仅使用了传统的蒸馏数据,还通过“关键词引导(Keyword-guided Refinement)”生成了高质量的精炼数据。作者比较用心给了一个蒸馏过程:

- • Question: 原始题目,来自 WikiTQ, FinQA ,是公开的数据集,如财报table+补充说明+问题,数据集还给出了答案。
如 "Dry Bulk 和 Logistics 业务的收入差额是多少?"
- • Original: 原始数据集里的标准答案(Ground Truth),通常只有一个答案,这里没有过程,没有推理。
- • Distillation (蒸馏):由 Teacher LLM(如 GPT-4) 补全的“解题过程”(思维链)
问 GPT-4:“已知答案是 25,907,请你一步步推导(Chain-of-Thought),向我解释这个数是怎么算出来的。附录 B 所说,GPT-4 这种通用模型太聪明、太快了,它往往跳过了对数据结构的仔细检查(比如忽略了表头单位、忽略了特殊行),直接进行计算。这种数据拿去训练小模型,容易让小模型养成“眼高手低”的坏毛病。至此,第一版Distillation结果不够好。
- • Refinement (精炼):由 Teacher LLM 在被强行插入关键词后,重写的“更严谨的解题过程”。
- 1. 从词表中随机采样了三个词(图左侧红字):
要求GPT-4:请重写上面的 Distillation 推理过程,必须把这三句话融进去,并根据这些话进行深一步的思考。
- • "What happens at the boundaries?" (边界情况?)
- • "Let's review the prior reasoning" (回顾一下?)
- • "Let's take a closer look at the table" (仔细看表?)
由此得到了reasoning/TableQA_distillation_39301.json (蒸馏版)、reasoning/TableQA_refinement_39301.json (精炼版)、reasoning/TableGPT_29448.json。
文件格式与环境交互 (File & Environment) - 约 1.3 万条
这部分数据对应论文中提到的 Inputs Format,训练模型识别和处理不同类型的外部文件。
- • reasoning/file_database_3833.json (数据库/SQL)
- • reasoning/file_csv_3007.json (CSV/Pandas)
- • reasoning/file_xlsx_3663.json (Excel)
- • reasoning/file_any_2520.json (其他格式)
训练模型根据文件后缀名选择正确的处理工具(例如看到 .db 用 sqlite3,看到 .csv 用 pandas),这是进入真实环境交互前的必要准备。
有人问到想让模型有读mysql 、hive、ck的能力,增加这部分数据接口。
综上:一阶段数据配比如下:
- 1. 20% 通用推理 (General):保底,维持智商。
- 2. 40% 结构化认知 (SKG):识字,学会看结构化数据。
- 3. 35% 数据科学推理 (TableQA/TableGPT):核心,通过合成的 Refinement 数据,学会像数据科学家一样思考(结合数据写代码)。
- 4. 5% 文件交互 (Files):工具,学会处理特定的文件格式。
2.2 阶段二 冷启动:
通过多智能体模拟合成的完整交互日志的数据,2.6万条。让模型知道“要先understand理解问题,然后分析,然后写代码,写完代码要等执行结果、”,将单项能力串联成工作流。如果没有这一步直接上 RL,模型会因为完全不懂交互规则而拿不到任何奖励(Reward Sparsity)。第一阶段SFT 后的模型只懂单个技能(如写代码、读表格),不懂多步流程(如先加载数据→再清洗→再分析)。直接丢进真实数据环境,模型会 “瞎操作”(比如没加载数据就写分析代码),几乎拿不到正向奖励,训练根本推进不下去。
请注意,冷启动实际上也是SFT,但这里的数据已经包含了完整的5个步骤。有老师在提了个问题:在cold start阶段,也会作为assistant的训练目标做训练吗?execute是环境执行的结果,SFT之后,模型除了code执行,还自己模拟了execute的执行结果,这样做不会对RL有影响吗?
作者回复:cold start阶段,中的内容是不计算loss的。这部分代码在:deepanalyze/ms-swift/swift/llm/template/base.py
if loss_scale_list[i] > 0.0: # Handle masking for <Execute> and </Execute> tags token_list_mask_exe = [] # 1. 检查当前文本块是否包含 <Execute> 和 </Execute> 标签 if ( isinstance(context, str) and "<Execute>" in context and "</Execute>" in context ): current_masked_tokens = [] in_execute_block = False # 2. 获取标签对应的 Token ID execute_start = self._tokenize("<Execute>")[0] # Get token ID for <Execute> execute_end = self._tokenize("</Execute>")[0] # Get token ID for </Execute> # 3. 遍历当前文本的所有 Token for token in token_list: # 遇到开始标签,进入屏蔽模式,并将当前 token 设为 -100 if token == execute_start: in_execute_block = True current_masked_tokens.append(-100) # 遇到结束标签,退出屏蔽模式,并将当前 token 设为 -100 elif token == execute_end: in_execute_block = False current_masked_tokens.append(-100) # 处于 <Execute> 块内部,全部设为 -100 elif in_execute_block: current_masked_tokens.append(-100) # 处于块外部(如 <Code> 或 <Analyze>),保留原始 Token ID else: current_masked_tokens.append(token) token_list_mask_exe += current_masked_tokens else: # 如果没有 Execute 标签,则保留所有 Token token_list_mask_exe += token_list # token_list_mask_exe = token_list # 4. 将处理后的 Token 列表添加到 labels 中 labels += token_list_mask_exe
在 PyTorch 的 CrossEntropyLoss 等损失函数中,-100 是默认的 ignore_index。这意味着:
- • 模型在训练时会看到 中的内容,这符合冷启动目标。
- • 但模型不需要预测 中的内容,也不会因为预测错误产生 Loss(因为 labels 对应位置是 -100)。
2.3 阶段三 (Agentic RL)
真实的 Python 执行环境,使用GRPO通过混合奖励(代码能不能跑通 + 报告写得好不好),让模型在真实环境中试错,学会根据报错修改代码,学会自我反思,最终实现“自主编排”。
论文指出,RL 阶段的数据15K 样本也是通过 3.3 节介绍的多智能体系统Multi-agent System合成的。这阶段的问题是有答案ground truth的。论文提到了使用混合奖励模型:
- • 数据集RL/qa.parquet,有标准答案的问答(例如:“计算 A 表的平均销售额”)
- 1. 结果对不对 :模型输出的数字/答案是否匹配 Ground Truth。

- • 数据集RL/reseach.parquet,对应开放式探索问题,例如:分析这份数据并写个报告。
- 1. Format Check:先过硬规则,XML 标签是否闭合?格式对不对?(格式不对直接R=-1)
- 2. Report Quality: 引入一个强模型(如 GPT-4o 或 DeepSeek-V3)作为裁判,根据五个维度打分:有用性、丰富性、合理性、可解释性、可读性。
- 3. 成功率:交互过程中有多少步是报错的?报错越少分越高。
奖励函数见github[2]
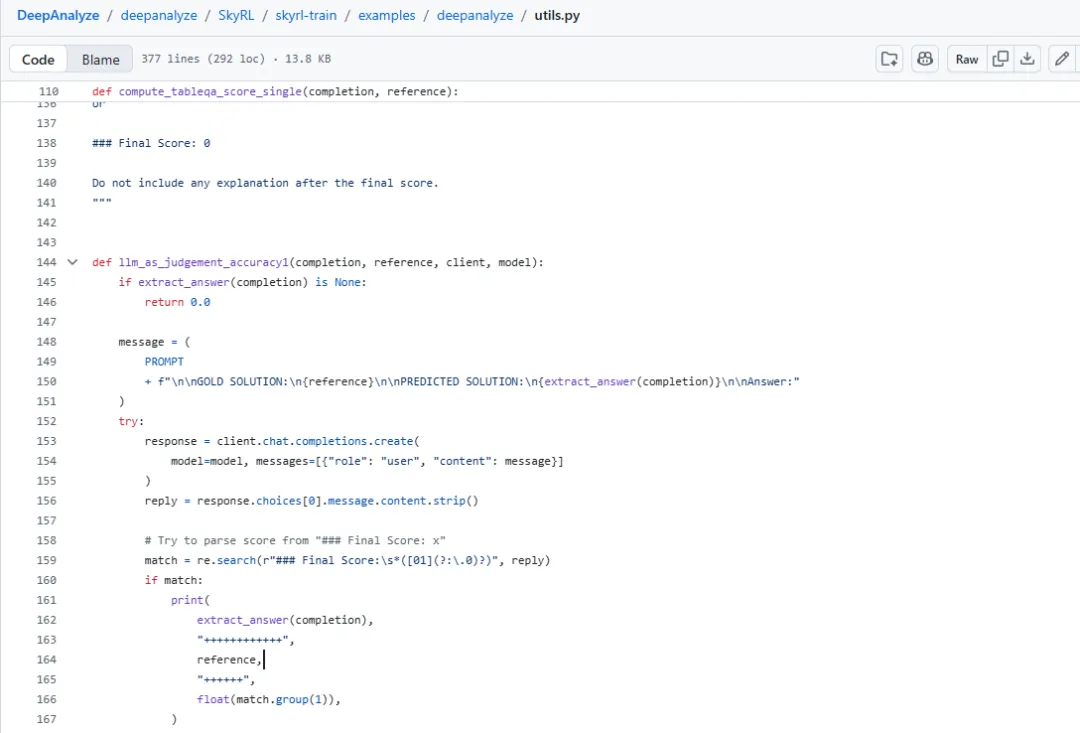
很难相信在RL中使用llm as judge,豆包坚决认为这里不会使用大模型判分,而genmini坚持一定是llm as judge,直到我和军哥找到代码证据。。。
第三部分 Experiments (实验)
- • 4.1 Benchmarks:使用 DataSciBench(全流程)、DSBench(分析建模)、DABStep(开放研究)、DS-1000(代码)、TableQA 系列等 12 个基准。
- • 4.2 Setup:基座模型 DeepSeek-R1-Distill-Qwen-8B,对比对象包括 GPT-4o、Claude-3.5、Llama-3 等及基于它们的 ReAct/AutoGen Agent。
- • 端到端全流程:DeepAnalyze-8B 优于大多数闭源模型构建的 Agent,仅次于 GPT-4o。
- • 开放式研究(Open-ended Data Research):在 DABStep-Research 上,生成的报告在内容深度和格式上优于基线,能够进行真正的探索性研究。
- • 代码与表格理解:在 DS-1000 和 TableQA 上刷新了 SOTA。
5. Analysis (分析)
- • 5.1 Ablation on Actions:去掉 动作会导致性能下降,证明了专门的数据理解动作的价值。
- • 5.2 Superiority of Curriculum-based Training:对比“仅SFT”、“仅RL”和“一步到位”,证明分阶段课程学习效果最好。
- • 5.3 Advantage of Reasoning Trajectory Synthesis:证明蒸馏+精炼(Refinement)生成的训练数据能有效提升模型推理能力。
6. Conclusion and Future Work (结论与未来工作)
- • 总结:DeepAnalyze 标志着从基于工作流的 Agent 向可训练 Agentic Model 的范式转变。
- • 未来:扩展到数据发现、治理等更广泛的数据生态系统。
Appendices (附录)
- • 提供了具体的 Prompt、基准测试构建细节(DABStep-Research)、案例展示(数据清洗、分析、报告生成的完整轨迹)等。
引用链接
[1] DeepAnalyze: https://arxiv.org/pdf/2510.16872[2] github: https://github.com/ruc-datalab/DeepAnalyze/blob/main/deepanalyze/SkyRL/skyrl-train/examples/deepanalyze/utils.py

