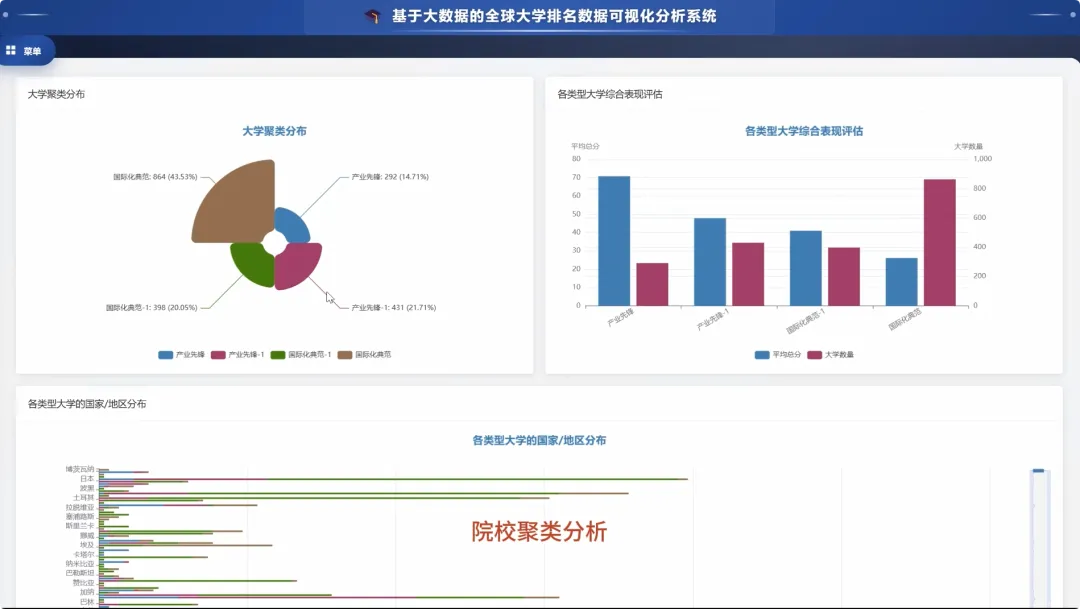
from pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, countDistinct, descfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.clustering import KMeansimport pandas as pdspark = SparkSession.builder.appName("UniversityRankingAnalysis").getOrCreate()def analyze_country_distribution(df): country_counts_df = df.groupBy("Location").agg(countDistinct("University").alias("university_count")) sorted_counts_df = country_counts_df.orderBy(desc("university_count")) pandas_df = sorted_counts_df.toPandas() pandas_df.to_csv("/output/country_distribution.csv", index=False) print("各国上榜大学数量分析完成,结果已保存") return pandas_dfdef analyze_core_metrics_correlation(df): metrics_cols = ["Overall Teaching Score", "Research Score", "Research Quality", "Industry Income Score", "International Outlook Score", "Overall Score"] metrics_df = df.select(metrics_cols).na.fill(0) pandas_metrics_df = metrics_df.toPandas() correlation_matrix = pandas_metrics_df.corr() correlation_matrix.to_csv("/output/metrics_correlation.csv") print("核心指标相关性分析完成,矩阵已保存") return correlation_matrixdef perform_university_clustering(df): feature_cols = ["Overall Teaching Score", "Research Score", "Research Quality", "Industry Income Score", "International Outlook Score"] assembler = VectorAssembler(inputCols=feature_cols, outputCol="features") assembled_data = assembler.transform(df.na.fill(0, subset=feature_cols)) kmeans = KMeans(k=4, seed=1, featuresCol="features", predictionCol="cluster") model = kmeans.fit(assembled_data) clustered_df = model.transform(assembled_data) result_df = clustered_df.select("University", "Location", "cluster") result_pandas_df = result_df.toPandas() result_pandas_df.to_csv("/output/university_clusters.csv", index=False) print("大学聚类分析完成,结果已保存") return result_pandas_df





















 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
