Python/Java/JS语言调用C/C++库的底层原理
- 2026-07-06 11:14:54
前言
如果你是 Python、Java、JS(在本文中特指 Node.js 场景)等语言的深度用户,那么你大概率会接触过多语言混合编程的开发场景,最典型的就是用这些语言去调用 C/C ++ 写的库。
之所以会有这种多语言混合编程的做法,最主要的原因有以下几个:
性能问题:有时候这些语言在性能上满足不了我们的需求,对于一些性能敏感的场景,开发者们往往会考虑用 C/C++ 来写库。 运行时封装的能力有限:假设我要用 Node.js 技术栈开发一个 Docker 这样的软件,这个软件会需要在拉起子进程的时候设置子进程的 namespace,Node.js 就没有提供这样的 API,所以我无法用纯 JS 脚本开发出 Docker。如果一定要实现这样的需求,我就必须要用 C/C++ 编写一部分功能,再用 JS 代码去调用它们。 复用现有 C/C++ 库:以 FFmpeg 这个库为例,假设我要在这些语言中使用 FFmpeg 的能力,跨语言调用 C/C++ 版本的 FFmpeg 库是最省事的方案,也是业界主流的方案。对于 FFmpeg 这样复杂的项目,要是换用这些语言去重写一遍,不仅面临性能问题,技术可行性和工作量也是很大的挑战。
那么,对于这种多语言混合编程的做法,有没有人好奇它们的底层技术实现呢?
在下面的内容中,我将对这块内容做一个科普。并通过“造轮子”的方式,用 100 行代码自己实现一个运行时,带大家体会其中的原理。
开发者的上层视角
假设我是一个 Python/Java/JS 开发者,我想在我的业务代码中调用 C/C++ 库。
在我的视角中,我大概会看到这样的一些方案:
运行时的底层行为
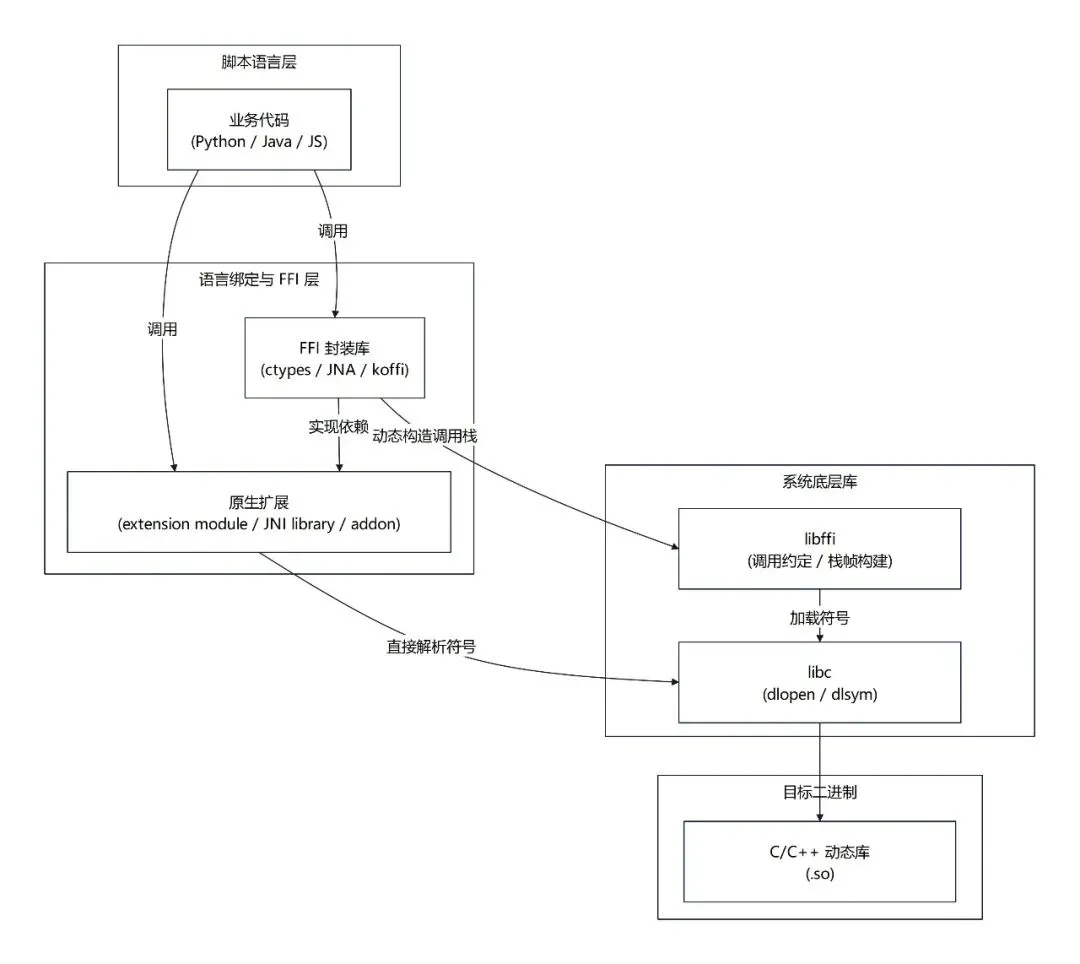
从底层来看,这 3 个语言的情况非常相似,针对调用 C/C++ 库这种需求,它们的运行时实际上只提供了唯一一套原生扩展机制。我们见到的“多种方案”其实都是建立于原生扩展机制之上的封装方案。
以 Node.js 运行时为例, Node.js 实际上只提供了 addon 机制。而 koffi 和 ffi-napi 是基于 addon 机制实现的库。koffi 和 ffi-napi 这两个库,它们本身就是个 addon,只不过这两个 addon 实现的业务比较特别:它们本身是 C/C++ 库,同时它们又可以作为一个桥梁,供 JS 侧用来调用其他的 C/C++ 库。
在这里还需要提一下 libffi 这个库,koffi 与 ffi-napi 的底层均基于 libffi。koffi 和 ffi-napi 需要在运行时动态地按照 ABI(应用程序二进制接口) 规范,将脚本层的参数压入栈或放入特定的寄存器,并处理返回值。这个过程被称为处理 Calling Convention(调用约定)。在这两个库中,这个过程是使用了 libffi 的能力来实现的。
同样,CPython 运行时 和 JDK 运行时也是类似的情况,他们分别提供了 extension module 和 JNI library 作为自己的原生扩展机制,并且在它们的生态中也有一些 FFI 封装库。
我们可以列个表格对比一下
共同的基座
无论是 CPython 的 extension module 方案,还是 JDK 的 JNI library 方案,或者是 Node.js 的 addon 方案,在 Linux 环境下,它们共同的底层实现都是 dlopen()。(在 Windows 环境下是 LoadLibrary(),本文不分析 Windows)
当我们调用原生扩展的时候,CPython、JDK、Node.js 这些运行时会这么做:
调用 libc 里面的 dlopen()函数,把 C/C++ 开发的动态链接库加载进来。调用 libc 里面的 dlsym()函数,把函数名字解析成函数指针。通过运行时自己实现的一系列业务代码,把函数指针包装成脚本层的可调用对象,并“注入”到你的脚本上下文中,让你在脚本里面能调用到那些函数。
这里我贴出各个运行时调用 dlopen() 的代码位置(带行号的 GitHub 链接),有兴趣者可以顺着这个位置看看上下文的实现。
CPython(按调用链,从上到下):
https://github.com/python/cpython/blob/v3.14.2/Lib/importlib/_bootstrap_external.py#L1053 https://github.com/python/cpython/blob/v3.14.2/Python/import.c#L4743 https://github.com/python/cpython/blob/v3.14.2/Python/importdl.c#L391 https://github.com/python/cpython/blob/v3.14.2/Python/dynload_shlib.c#L82
JDK(按调用链,从上到下):
https://github.com/openjdk/jdk/blob/jdk-17-ga/src/hotspot/share/prims/jvm.cpp#L3366 https://github.com/openjdk/jdk/blob/jdk-17-ga/src/hotspot/os/linux/os_linux.cpp#L1607 https://github.com/openjdk/jdk/blob/jdk-17-ga/src/hotspot/os/linux/os_linux.cpp#L1799
Node.js(按调用链,从上到下):
https://github.com/nodejs/node/blob/v24.12.0/lib/internal/modules/cjs/loader.js#L1920 https://github.com/nodejs/node/blob/v24.12.0/src/node_binding.cc#L477 https://github.com/nodejs/node/blob/v24.12.0/src/node_binding.cc#L346
造个轮子体会一下
为了帮助大家更好地理解这一过程,我用 AI 生成了 100 行代码,实现了一个迷你的运行时,它实现了一门自创的脚本语言。在本文中,我们将这门语言称为 MyScript 语言,简称 MS 语言,并使用 .ms 作为脚本文件的后缀名。
MyScript 语言的代码长这样
var a = 1 # 用 var 语句定义变量,仅支持整数变量var b = 2 * 3 # 给变量赋值的时候,支持加减乘除表达式var c = b + 1 # 赋值表达式中支持引用其他变量print c # 有个 print 语句可以用于输出计算结果在这个运行时中,我专门实现了调用 C/C++ 库的功能,用法是这样的
import ./my-lib.so # 导入动态链接库var a = call add 5 7 # 调用动态链接库库里面 的 add 函数,计算 5 + 7print a # 输出结果运行时的 100 行完整代码如下
#include<stdio.h>#include<string.h>#include<stdlib.h>#include<dlfcn.h>#include<ctype.h>#define MAXVAR 64char line[256];char *position;void *handle = NULL;char name[MAXVAR][32];int value[MAXVAR];int var_count = 0;staticintlookup(constchar *s){for (int i = 0; i < var_count; ++i) if (!strcmp(name[i], s)) return i;return-1;}staticchar *next(){while (*position && isspace(*position)) ++position;if (!*position) returnNULL;char *start = position;while (*position && !isspace(*position)) ++position; *position++ = '\0';return start;}intexpr(){char *token = next();if (!token) return0;int x;if (strcmp(token, "call") == 0) {char *sym = next();int a = expr();int b = expr();int (*f)(int, int) = dlsym(handle, sym); x = f ? f(a, b) : 0; } else {int i = lookup(token); x = (i >= 0) ? value[i] : atoi(token); }while ((token = next())) {if (strcmp(token, "+") == 0) { x += expr(); }elseif (strcmp(token, "-") == 0) { x -= expr(); }elseif (strcmp(token, "*") == 0) { x *= expr(); }elseif (strcmp(token, "/") == 0) { x /= expr(); }else { position -= strlen(token) + 1; break; } }return x;}voidrun(FILE *fp){while (fgets(line, sizeof(line), fp)) { position = line;char *token = next();if (!token || *token == '#') continue;if (strcmp(token, "import") == 0) {char *so = next(); handle = dlopen(so, RTLD_LAZY);if (!handle) { puts(dlerror()); exit(1); } }elseif (strcmp(token, "print") == 0) {char *var = next();int i = lookup(var);if (i < 0) { printf("undefined: %s\n", var); exit(1); }printf("%d\n", value[i]); }elseif (strcmp(token, "var") == 0) {char *var = next(); next();if (var_count == MAXVAR) { puts("too many vars"); exit(1); }strcpy(name[var_count], var); value[var_count++] = expr(); }else {char *var = token;if (next() && strcmp(next(), "=") == 0) {int i = lookup(var);if (i < 0) { printf("undefined: %s\n", var); exit(1); } value[i] = expr(); } } }}intmain(int argc,char **argv){ run(fopen(argv[1], "r"));return0;}接下来我们在 Linux 系统上把这个运行时跑起来,体验一下在脚本里面调用 C/C++ 库的效果。
首先把运行时给编译出来
gcc ms.c -ldl -o ms编写一个 my-lib.c,并将其编译成 so
echo"int add(int a,int b){return a+b;}" > my-lib.cgcc -shared -fPIC my-lib.c -o my-lib.so编写一段 MyScript 脚本,将其保存成文件 test.ms
import ./my-lib.sovar a = call add 5 7print a用运行时执行这个脚本,能得到结果 12
./ms test.ms# 12受限于代码篇幅,这个运行时并没有做得很完善,是有很多 bug 的。大家不必纠结于代码里面的具体细节,大致看个思路就行。
这个运行时之所以能支持脚本调用 C/C++ 库,关键就在于 dlopen() 函数的使用。只要理解了这一思路,自然也就能理解 CPython、JDK、Node.js 等运行时的实现原理了。
当然,这里呈现的只是一个最基本的原理。在实际的工程落地场景中,CPython、JDK、Node.js 的业务逻辑是非常复杂的。
扩展知识
1. 这些运行时也能调用其他编译型语言写的库
上文只提到了 C/C++,并未介绍其他编译型语言的情况。事实上 rust 和 go 等语言情况也是类似的,它们也支持生成动态链接库。他们编出来的动态链接库也是能被 CPython、JDK、Node.js 这些运行时加载的。
rust、go 编出来的动态链接库,只要对外的接口符合相应的规范(Python/C API、JNI、N-API),他们也能被这几个运行时的原生扩展机制(extension module、JNI library、addon)直接识别。
即使不符合相应的规范,那也没关系,还有一些封装出来的 FFI 方案(ctypes、JNA、ffi-napi 等)可以让你调用这些不符合规范的接口。
现在这几个语言的生态也在逐渐有人尝试用 C/C++ 以外的编译型语言来写原生扩展了,比如 Node.js 生态里面的 rollup、rolldown 等库就是用 rust 来实现的。
2. 调用动态链接库也是有性能开销的
虽然把热点逻辑用 C/C++ 实现能提速,但每一次跨语言调用本身都会带来额外成本。如果频繁在两种语言之间来回切换(例如在循环里反复调用一个轻量级函数),反而可能比纯脚本实现更慢。
3. 注意符号修饰的问题
如果你的动态链接库不是纯 C 写的,而是 C++ 或其他语言写的,那需要注意符号修饰的问题。比如在 C++ 代码里加 extern "C",避免符号被修饰而产生“找不到符号”之类的错误。

