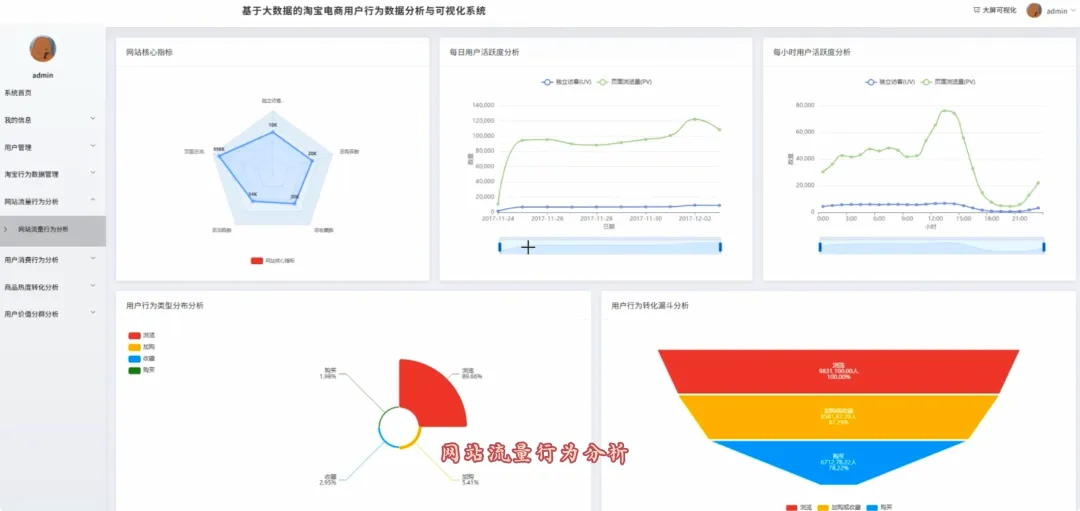
from pyspark.sql import SparkSession, Windowfrom pyspark.sql.functions import col, count, datediff, max, sum as _sum, row_number, descspark = SparkSession.builder.appName("TaobaoAnalysis").getOrCreate()df = spark.read.csv("hdfs://path/to/user_behavior.csv", header=True, inferSchema=True)def funnel_analysis(df): pv_df = df.filter(col('behavior_type') == 'pv').agg(count('user_id').alias('pv_count')) cart_df = df.filter(col('behavior_type') == 'cart').agg(count('user_id').alias('cart_count')) fav_df = df.filter(col('behavior_type') == 'fav').agg(count('user_id').alias('fav_count')) buy_df = df.filter(col('behavior_type') == 'buy').agg(count('user_id').alias('buy_count')) return pv_df.union(cart_df).union(fav_df).union(buy_df)def rfm_analysis(df): buy_df = df.filter(col('behavior_type') == 'buy') max_date = buy_df.agg(max('date')).collect()[0][0] rfm = buy_df.groupBy('user_id').agg( (datediff(lit(max_date), max('date'))).alias('R'), count('user_id').alias('F'), count('user_id').alias('M') ) return rfmdef hot_items_analysis(df): item_behavior_df = df.filter(col('behavior_type').isin(['pv', 'buy'])).groupBy('item_id').agg( count(when(col('behavior_type') == 'pv', True)).alias('pv_count'), count(when(col('behavior_type') == 'buy', True)).alias('buy_count') ) hot_items = item_behavior_df.withColumn('conversion_rate', col('buy_count') / col('pv_count')).orderBy(desc('pv_count')).limit(10) category_behavior_df = df.filter(col('behavior_type').isin(['pv', 'buy'])).groupBy('item_category').agg( count(when(col('behavior_type') == 'pv', True)).alias('pv_count'), count(when(col('behavior_type') == 'buy', True)).alias('buy_count') ) hot_categories = category_behavior_df.orderBy(desc('pv_count')).limit(10) return hot_items, hot_categories