一、学前花絮
我们之前学习了python实现数据结构,包括线性数据结构的数组、栈、队列、链表和非线性数据结构的树、图等。顺着这个思路,图数据库可以认为是图这种数据结构的实现。下图描述了图与图数据库的关系:
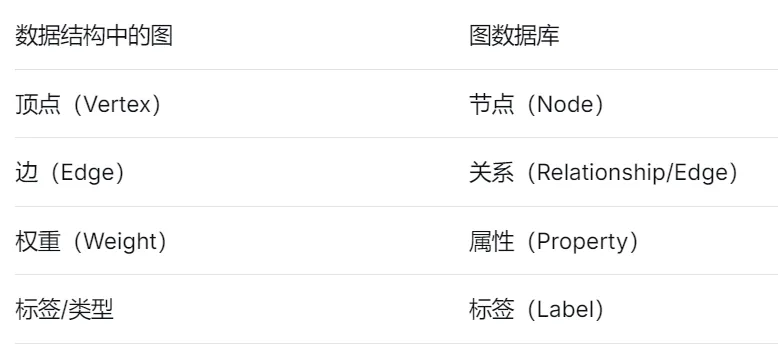
图数据库正在成为处理关联数据的重要工具,特别是在大数据和AI时代,关系的价值越来越重要。选择合适的数据库技术,需要根据具体的业务需求和数据特性来决定。
在我们前面的文章中,针对几款关系型数据库进行了探讨,包括:mysql、sqlite和postgresql等。其实市面上有很多种数据库,比如oracle、sqlserver还有国产数据库等。但是在开源方面,比较适合个人开发应用的还是我之前介绍的那三种,特别是sqlite数据库,安装空间非常小,又具备了关系型数据库的操作特质,比较适合python示例进行数据库操作。
那么图数据库中有没有类似sqlite这种轻型的呢?便于安装、使用,同时又具备图数据库的所有特质。我们今天介绍的kuzu就是这样一款图数据库。
二、python操作图数据库kuzu
2.1什么是图数据库
图数据库是一种专门用于存储和处理图结构数据的数据库系统。它使用图论的概念,通过节点(顶点)、边(关系)和属性来表示和存储数据。
核心概念包括:
l节点(Node/Vertex):实体对象,如人、产品、地点
l边(Edge/Relationship):节点之间的连接,表示关系
l属性(Property):节点和边的特征信息
l标签(Label):节点的分类
主要特点:
l原生图存储:数据按图结构存储,不是模拟图的关系表
l索引自由:通过关系直接导航,减少JOIN操作
l灵活模式:支持动态添加节点类型和关系类型
l路径查询:高效处理多跳查询和路径发现
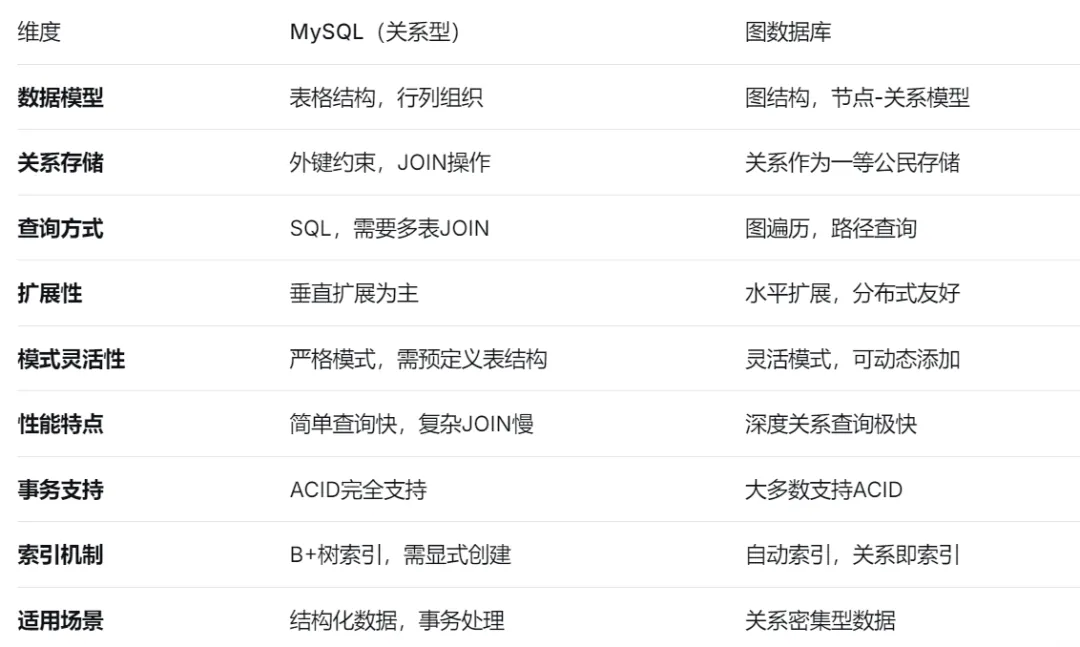
2.2图数据库(kuzu)与关系型数据库(mysql)存储方式对比
MySQL(关系型数据库)

图数据库(如Neo4j、Kùzu)
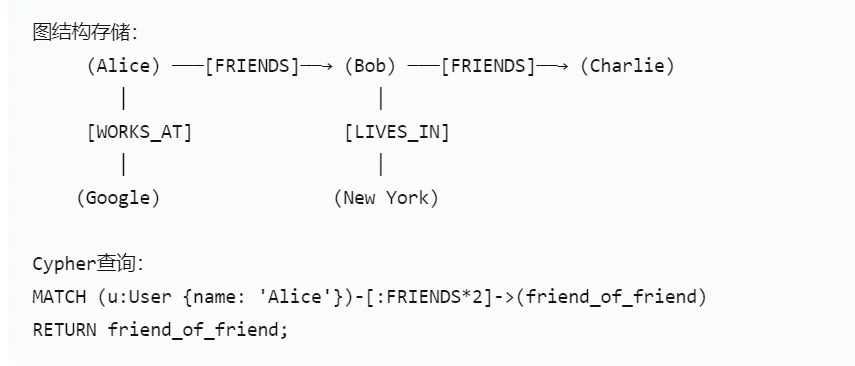
详细对比表格
2.3选择建议
选择图数据库当:
l关系是第一公民:你的应用主要关注实体之间的关系
l需要深度遍历:经常查询3度或更深的关系
l动态关系模式:关系类型和结构频繁变化
l路径分析需求:需要找到最短路径、所有路径等
l实时推荐:需要基于实时关系进行推荐
选择MySQL当:
l强事务需求:需要严格的ACID保证
l固定结构数据:数据结构稳定,变化少
l复杂计算:需要复杂的聚合计算和统计分析
l成熟生态:需要丰富的工具和ORM支持
l团队熟悉度:团队对SQL有丰富经验
现在的很多项目采用二者的混合架构:
上层应用层: 各种业务app及操作界面等 |
数据存储层: MySQL: 用户信息、订单、支付等 图数据库: 社交关系、推荐、风控 |
示例:电商平台
lMySQL存储:用户资料、商品信息、订单记录、库存数据
l图数据库存储:用户浏览关系、社交推荐、商品关联、欺诈网络
核心建议:
l如果你的业务核心是实体之间的关系,选择图数据库
l如果你的业务核心是实体本身的属性,选择关系数据库
l对于复杂业务,考虑混合使用,发挥各自优势
2.4Python 装饰器封装 kuzu连接 + CRUD(增删改查) 类示例
程序设计思想:
在使用数据库过程中,增删改查是最常见的操作,而这些操作都与数据库连接相关。也就是说只有通过python连接上kuzu之后,才可以操作。
所以我们使用 @with_connection 装饰器自动管理连接,然后在类中定义增删改查的方法进行封装。
程序的主体结构:
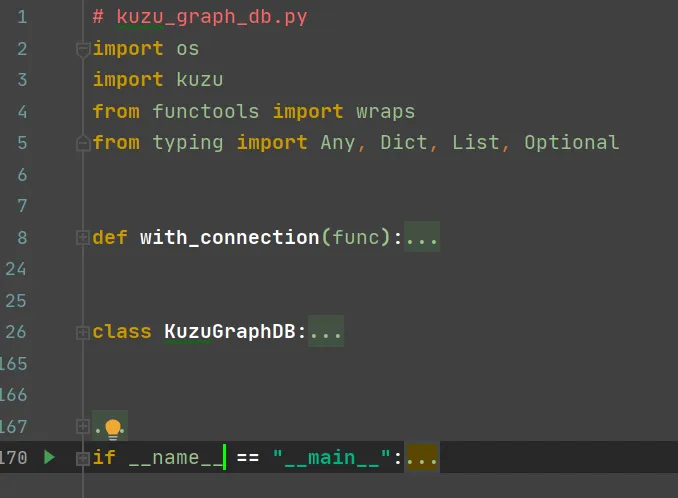
程序中第一部分是模块的引入,包括kuzu模块等。接下来就是自定义数据库连接的装饰器,供后面的数据库操作使用。下面就是自定义数据库操作的类,把所有数据库CRUD操作封装其中。最下面的就是调用上面的类和方法进行输入输出了。
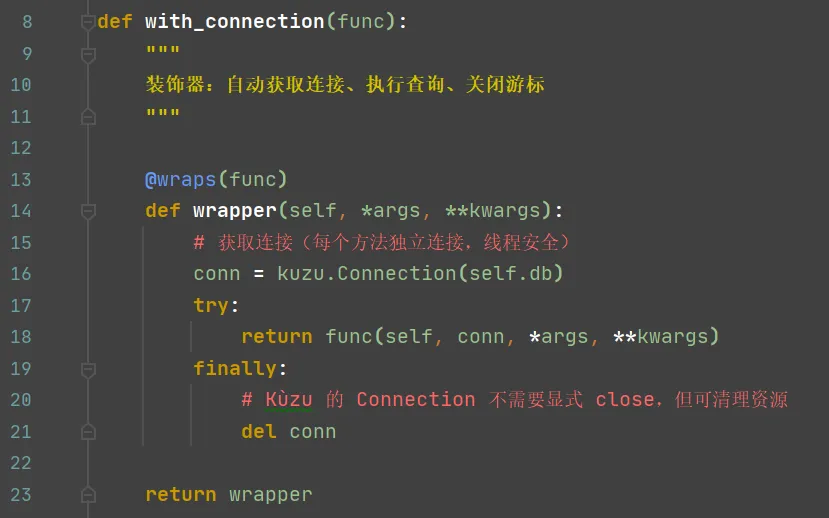
连接数据库的装饰器程序代码:
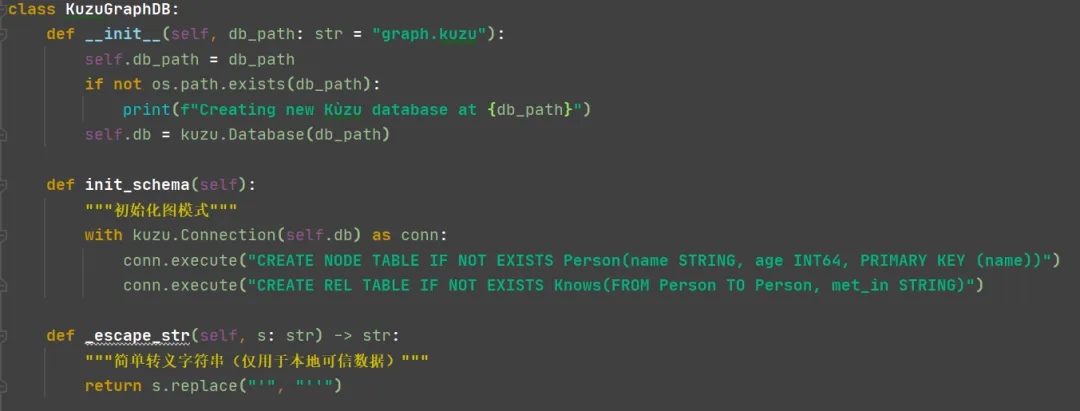
在类中,首先做的事情是初始化(创建库、图结构节点等):
下面是具体的操作方法:
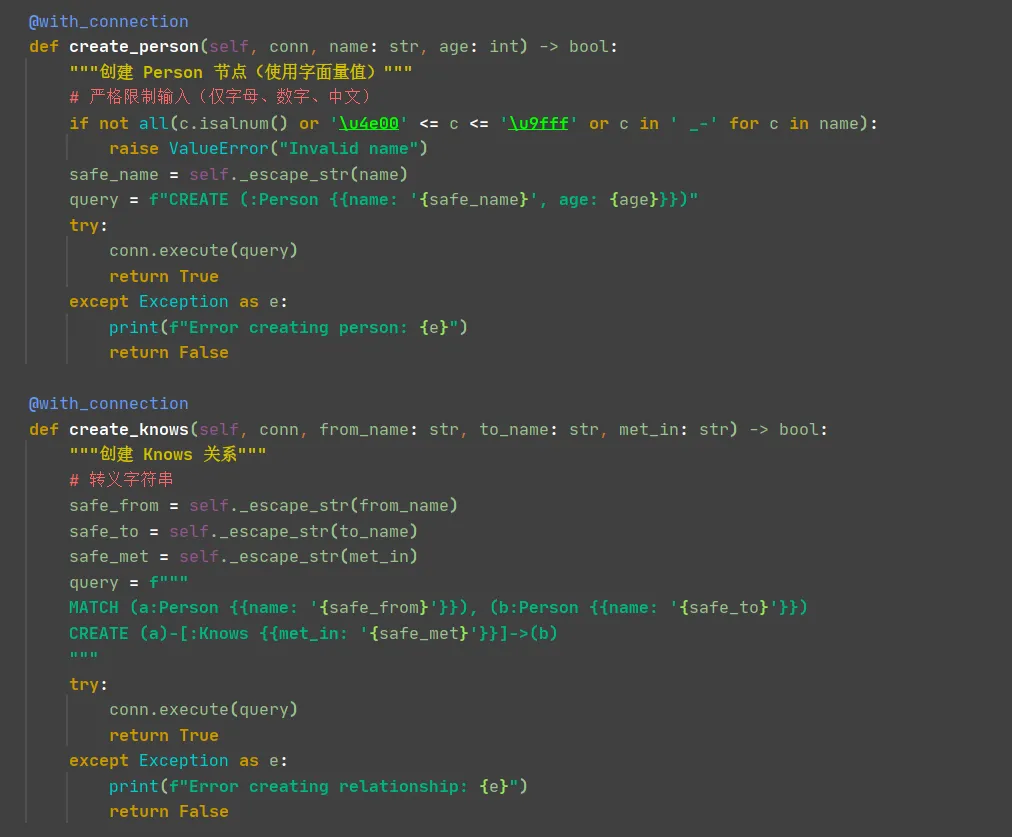
细心的朋友会发现初始化图的时候创建了表节点Person,后面的方法也是创建表。二者是什么关系呢?
init_schema() 中的 CREATE NODE TABLE Person(...) 是定义“节点类型”(相当于建表结构),
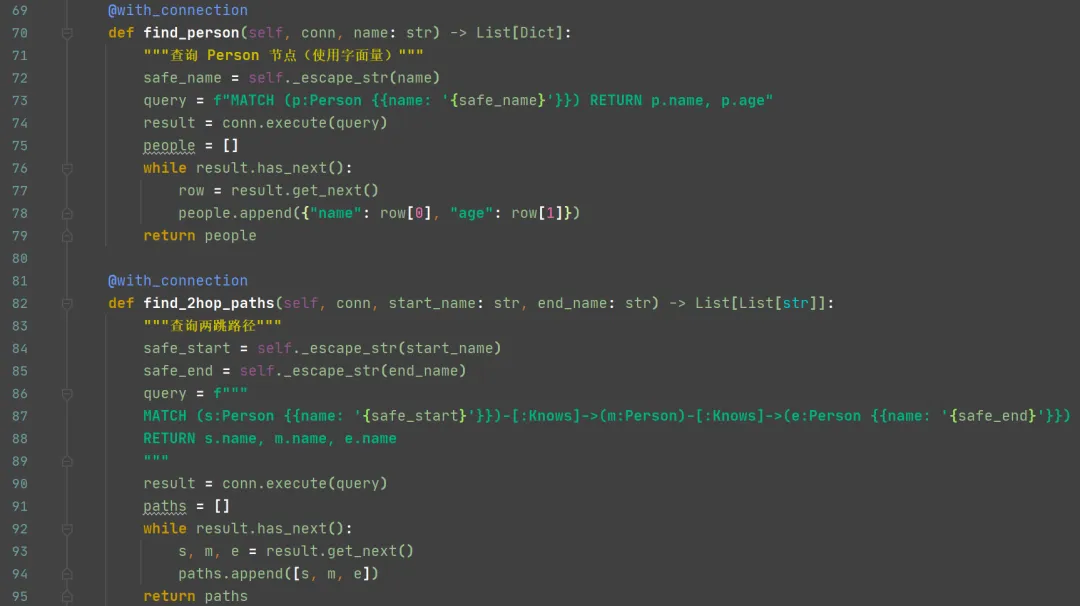
而 create_person() 中的 CREATE (:Person {...}) 是插入一个具体的“节点实例”(相当于插入一行数据)。下面是查询方法:
下面是调用示例:
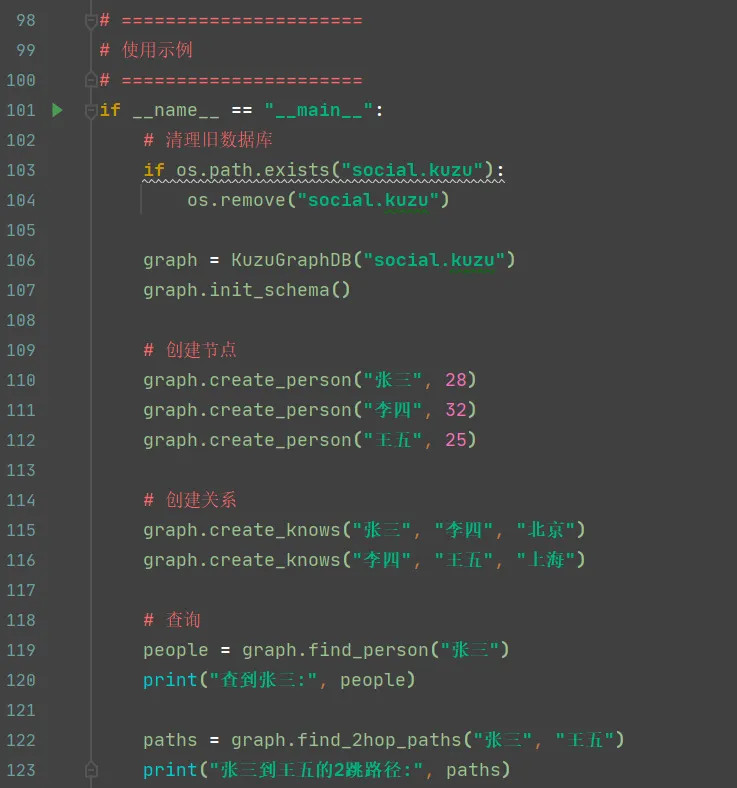
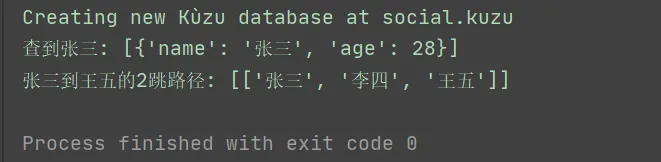
输出结果如下:
三、小结
通过对图数据库的了解,并用python程序实现与kuzu的连接及操作使用。我们对于图数据库的特点和使用场景有了初步认识,图数据库非关系型,与传统的关系型数据库有很大的区别。我们之前说过,任何新事物的出现都是为了满足现实中的需求,图数据库在构建知识图谱等方面有传统关系型不具备的优势。
让我们保持学习热情,多做练习。我们下期再见!


