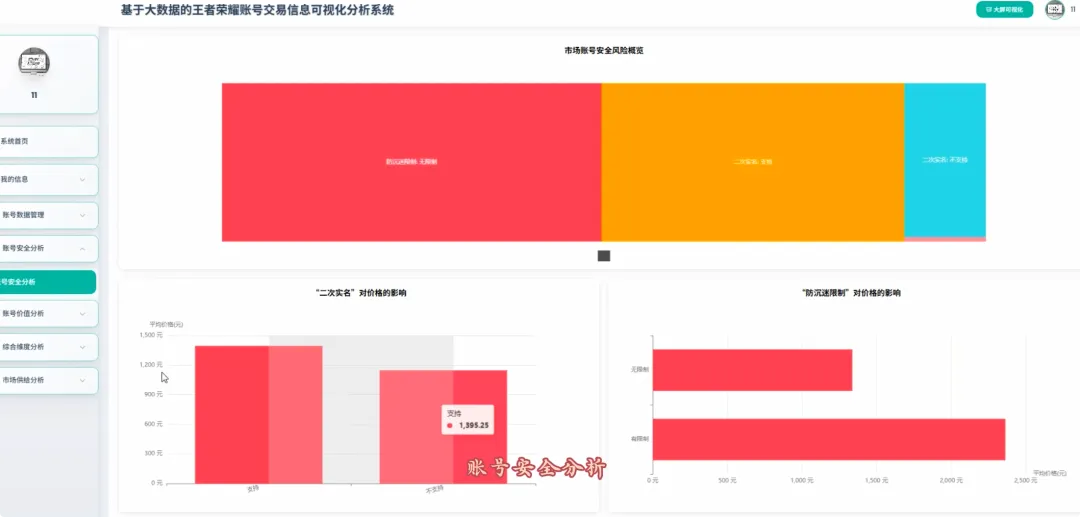
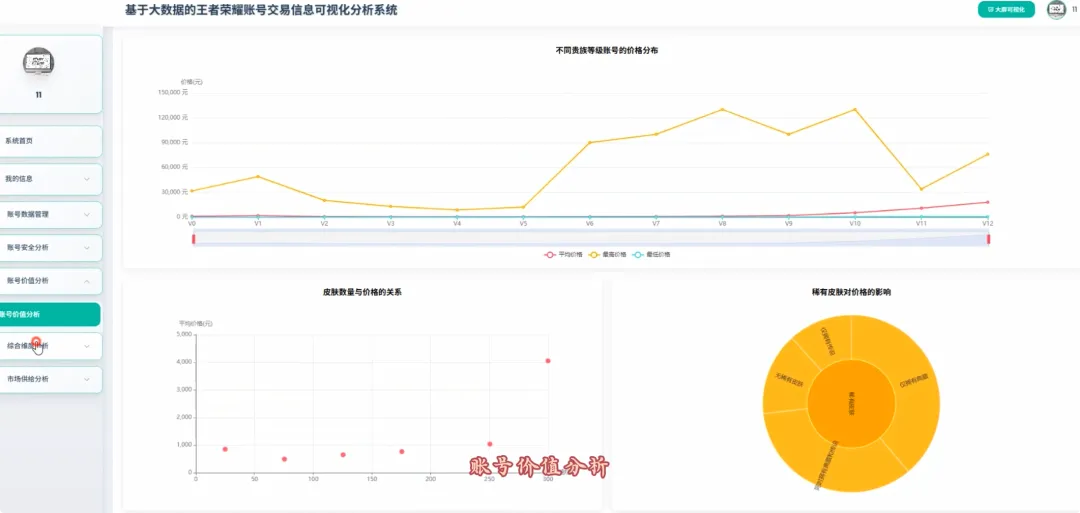
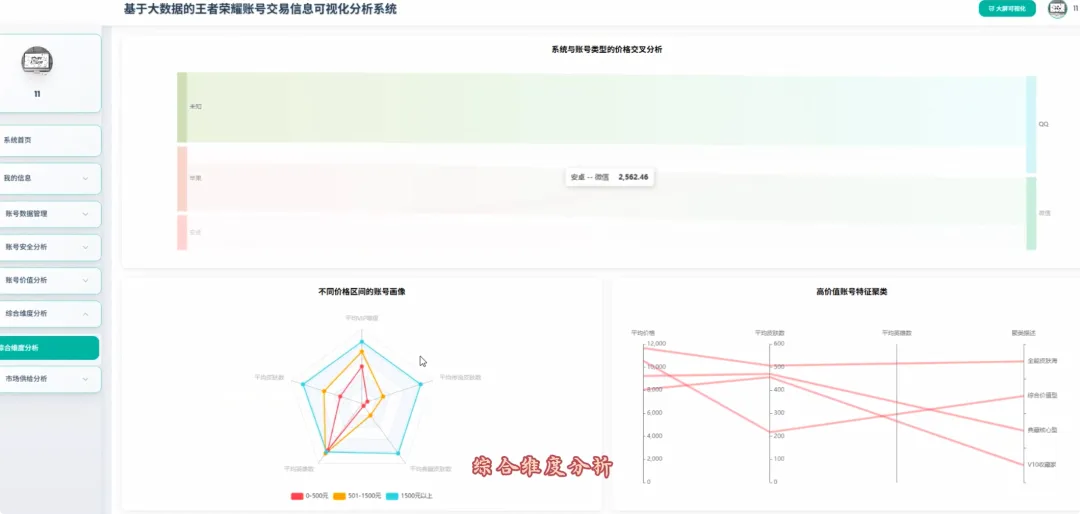
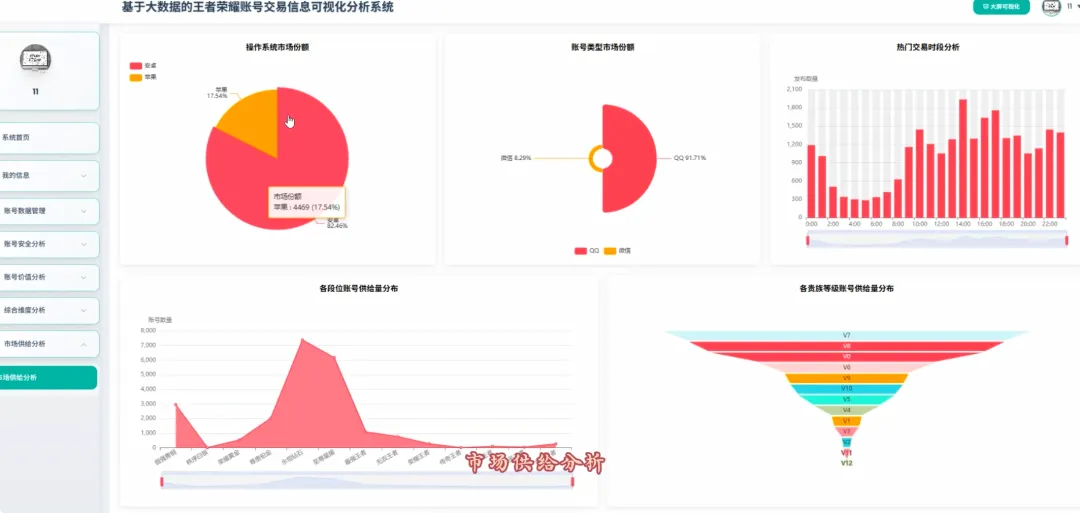
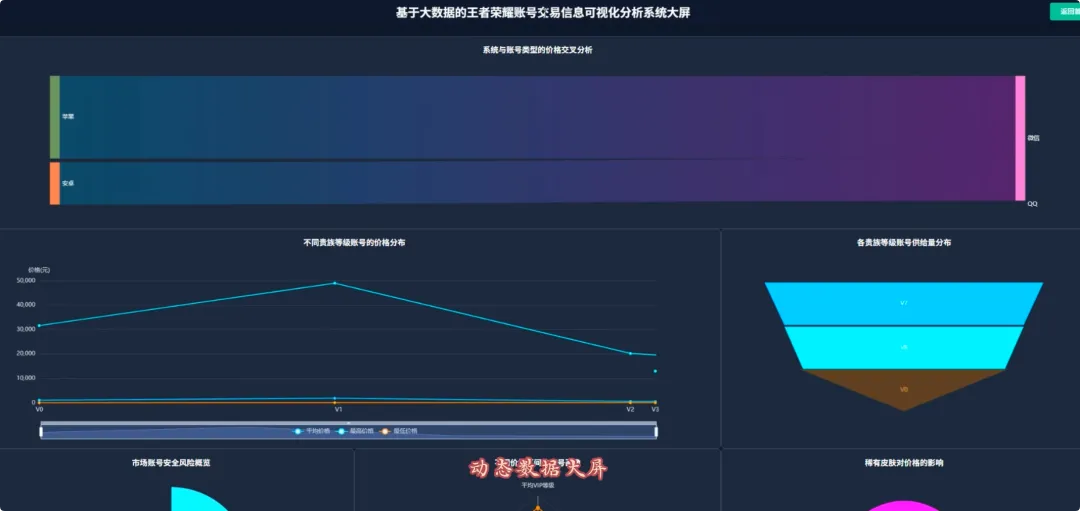
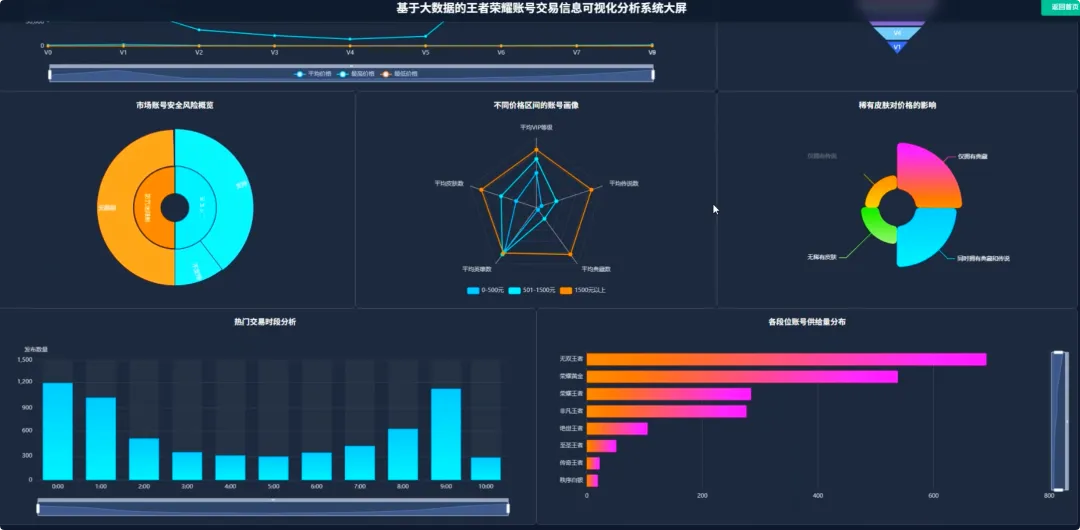
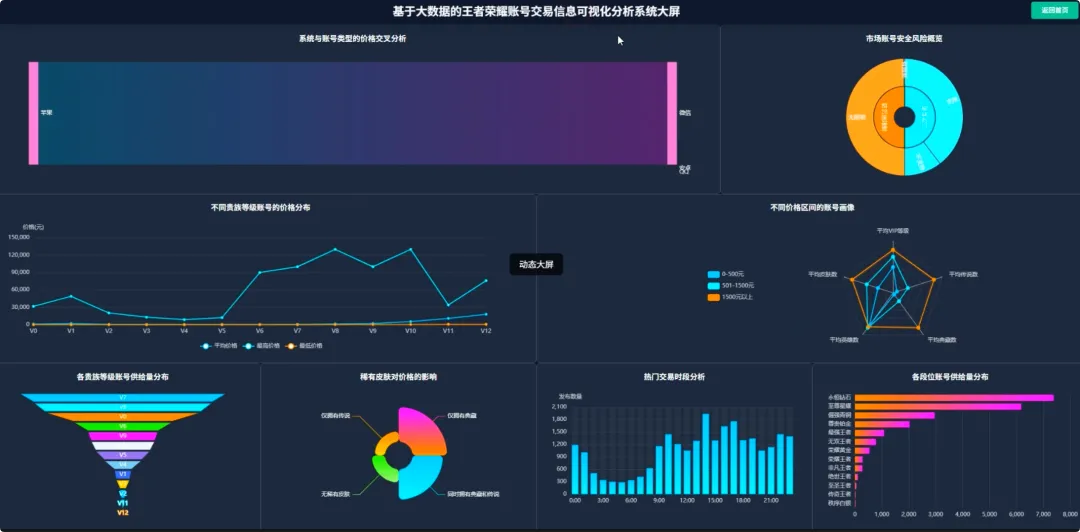
from pyspark.sql import SparkSessionfrom pyspark.ml.feature import VectorAssembler, Bucketizerfrom pyspark.ml.clustering import KMeansspark = SparkSession.builder.appName("HonorOfKingsAnalysis").getOrCreate()df = spark.read.csv("hdfs://.../account_data.csv", header=True, inferSchema=True)# 功能1: 贵族等级与价格分布分析def analyze_vip_price(): valid_df = df.filter(df.price.isNotNull() & df.vip_level.isNotNull()) vip_price_stats = valid_df.groupBy("vip_level").agg( {"price": "avg", "price": "max", "price": "min", "price": "count"} ).withColumnRenamed("avg(price)", "avg_price").withColumnRenamed("max(price)", "max_price").withColumnRenamed("min(price)", "min_price").withColumnRenamed("count(price)", "account_count").orderBy("vip_level") return vip_price_stats.toPandas()# 功能2: 皮肤数量与价格关系(分箱统计)def analyze_skin_price(): valid_df = df.filter(df.price.isNotNull() & df.skin_count.isNotNull()) splits = [0, 50, 100, 200, 300, float("inf")] bucketizer = Bucketizer(splits=splits, inputCol="skin_count", outputCol="skin_bins") binned_df = bucketizer.transform(valid_df) skin_price_relation = binned_df.groupBy("skin_bins").agg({"price": "avg"}).withColumnRenamed("avg(price)", "avg_price").orderBy("skin_bins") return skin_price_relation.toPandas()# 功能3: 高价值账号特征聚类分析def cluster_high_value_accounts(): price_threshold = df.approxQuantile("price", [0.95], 0.0)[0] high_value_df = df.filter(df.price > price_threshold).select("price", "vip_level", "skin_count", "glory_collection_skin_count").na.fill(0) assembler = VectorAssembler(inputCols=["price", "vip_level", "skin_count", "glory_collection_skin_count"], outputCol="features") assembled_data = assembler.transform(high_value_df) kmeans = KMeans(k=3, seed=1, featuresCol="features", predictionCol="cluster") model = kmeans.fit(assembled_data) clustered_df = model.transform(assembled_data).select("price", "vip_level", "skin_count", "glory_collection_skin_count", "cluster") return clustered_df.toPandas()