揭开Python中迭代器和生成器的神秘面纱!!!
- 2026-06-25 13:46:30
大家好,欢迎来到壹创客空间!今天我们探索的课题是迭代器、可迭代对象和生成器在Python中的用法,比较难懂、更容易混淆,建议初学者先建立直观的理解,从最简的地方开始使用,然后逐步理解其中的原理。
现在,我们就来扒拉扒拉它们,希望对您有所帮助!
1. 简单理解一下迭代器概念及核心功能
1.1 什么是迭代器?
迭代器是Python语言的一种设计模式,是遍历可迭代对象元素的“一次性读取”工具。
记住三个点: 一种设计模式;一种工具;数据源为可迭代对象。
1.2 迭代器三个关键核心功能:
处理大数据文件、创建无限序列。
高效使用内存空间。
保持程序执行状态。
学习路线:简单直观理解—>动手实践—>开始迷糊—>懵圈—>渐渐明白—>在动手实践—>"迭代器高手",这是我学习Python的经历和体验。
2. 什么是可迭代对象?
先复习一下与迭代相关的一个概念——可迭代对象。可迭代对象就是
可以被 for 循环遍历的任何对象。常见的字符串(str)、列表(list)、元组(tuple)、字典(dict)、集合(set)等都可以被for循环遍历,都是可迭代对象。
示例代码如下:
# 定义一个列表my_list=[1,2,3,4,5,6] # 可迭代对象for item in my_list: # for循环进行遍历print(item,end=' ') # 输出:1 2 3 4 5 6
3. 内置迭代器函数:iter()和next()的用法
3.1 iter() 函数
作用:获取一个可迭代对象的迭代器
语法:
iter(object[, sentinel])返回值:对象的迭代器
示例代码:
# 定义一个列表my_list=[1,2,3,4,5,6]my_iterator=iter(my_list) # 将可迭代对象转化为迭代器for item in my_iterator:print(item,end=' ') # 输出: 1 2 3 4 5 6
3.2 next() 函数
作用:从迭代器中获取下一个元素
语法:
next(iterator[, default])返回值:下一个元素,如果没有元素且提供了默认值则返回默认值
示例代码:
# 定义一个列表my_list=[1,2,3,4]my_iterator=iter(my_list)print(next(my_iterator)) # 输出:1print(next(my_iterator)) # 输出:2print(next(my_iterator)) # 输出:3print(next(my_iterator)) # 输出:4# print(next(my_iterator))# 没有元素时,抛出StopIteration异常,如果设置了默认值,则显示默认值!print(next(my_iterator,'提示没元素了!'))# 输出:提示没元素了
4. for循环的底层执行逻辑
可迭代对象和迭代器,都可以被for循环进行遍历。实际上,它们的for循环底层执行逻辑是完全相同的。也就是说Python的for循环只有一种底层逻辑。
底层逻辑如下:
# 所有 for 循环的实际执行逻辑_iterable = 对象 # 可能是可迭代对象,也可能是迭代器iterator = iter(_iterable) # 关键步骤!while True:try:item = next(iterator)# 执行循环体except StopIteration:break
示例代码:
# 定义可迭代对象my_list=[1,2,3,4]for item in my_list:print(item) # 输出:1 2 3 4
等价于下面的示例代码:
my_list=[1,2,3,4]iterator = iter(my_list) # 关键步骤,将可迭对象转化为迭代器!while True:try:item = next(iterator)print(item) # 输出:1 2 3 4# 执行循环体except StopIteration:break
可以看出,可迭代对象是通过内置迭代器函数iter()获取可迭代对象的迭代器,然后通过内置迭代器函数next()执行while循环,逐个获取可迭代对象元素的值。
迭代器只是一个工具,真正的数据源来源于可迭代对象。
5. 可迭代对象与迭代器for循环的区别
既然Python中的for循环只有一种底层执行逻辑,可迭代对象和迭代器又有什么区别呢?我们先来自定义一个可迭代对象。
5.1 创建自定义可迭代对象

for循环遍历的对象是可迭代对象,底层代码在调用iter()函数时,自动调用可迭代对象类方法__iter__(),返回一个新的迭代器,然后通过while循环执行迭代器next()函数,自动调用__next__()方法,逐个获取迭代器元素的值。
5.2 创建自定义迭代器
class MyIterator:"""自定义迭代器"""def __init__(self, data):self.data = dataself.index = 0def __iter__(self):print("MyIterator.__iter__() 被调用,返回自身")return self # 关键区别:返回自身!def __next__(self):if self.index >= len(self.data):raise StopIterationvalue = self.data[self.index]self.index += 1return valueprint("=== 迭代器 ===")my_iterator = MyIterator([1, 2,3,4]) #print(next(my_iterator)) # 输出:1for item in my_iterator:print(item) # 输出:2 3 4
运行示意图:
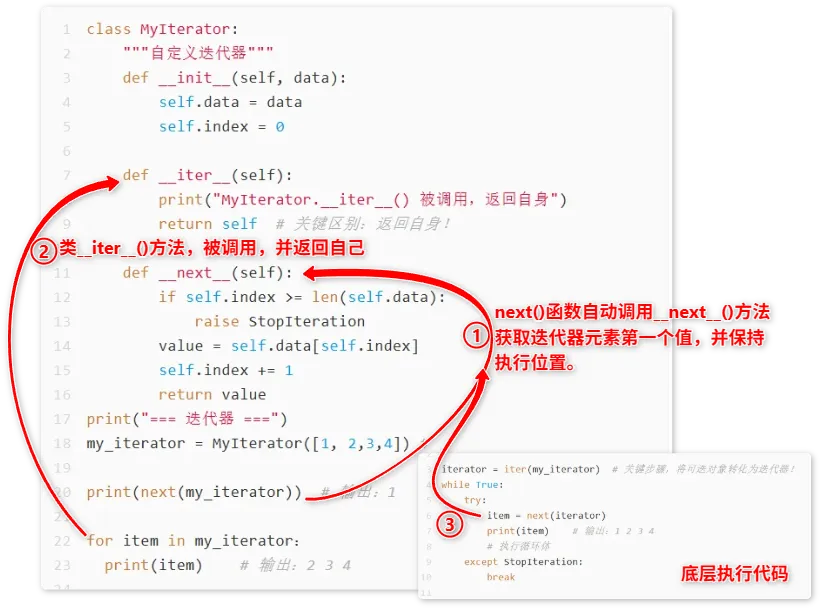
for循环遍历的对象是迭代器对象,底层代码在调用iter()函数时,自动调用迭代器类__iter__()方法,返回一个迭代器(这个迭代器是自己self),然后通过while循环执行迭代器next()函数,自动调用__next__()方法,逐个获取迭代器元素的值,并保持执行状态。
iter() 函数对待不同类型的对象有不同的行为。一个返回新的迭代器,一个返回自己self。可迭代对象执行iter()函数
my_list = [1, 2, 3] # 可迭代对象iterator = iter(my_list) # 关键这一步发生了什么?# 实际调用:my_list.__iter__()# 返回:一个全新的迭代器对象# 每次调用 iter(my_list) 都返回不同的迭代器
迭代器执行iter()函数
my_iterator = iter([1, 2, 3]) # 已经是迭代器iterator2 = iter(my_iterator) # 关键这一步发生了什么?# 实际调用:my_iterator.__iter__()# 返回:迭代器自身 (self)# iter(迭代器) 返回同一个对象
5.3.1可迭代对象
定义:实现了
__iter__()方法,该方法返回一个迭代器对象。特点:可以重复迭代,每次调用
__iter__()都会返回一个新的迭代器。常见示例:列表、元组、字符串、字典、集合。
5.3.2 迭代器
定义:实现了
__iter__()和__next__()方法。特点:有状态,消耗性。遍历时会记住当前位置,且遍历一次后耗尽。
常见示例:
iter()函数返回的对象、生成器、文件对象。
综合示例代码:
class MyIterable:"""自定义可迭代对象(非迭代器)"""def __init__(self, data):self.data = datadef __iter__(self):print("MyIterable.__iter__() 被调用,创建新迭代器")return iter(self.data)class MyIterator:"""自定义迭代器"""def __init__(self, data):self.data = dataself.index = 0def __iter__(self):print("MyIterator.__iter__() 被调用,返回自身")return self # 关键区别:返回自身!def __next__(self):if self.index >= len(self.data):raise StopIterationvalue = self.data[self.index]self.index += 1return value# 创建自定义对象print("=== 可迭代对象 ===")iterable = MyIterable([1, 2, 3])iterator1 = iter(iterable)# 输出:MyIterable.__iter__() 被调用iterator2 = iter(iterable)# 输出:MyIterable.__iter__() 被调用(再次调用)print(f"两个迭代器相同吗?{iterator1 is iterator2}") # False# 生成两个新的迭代器,不是相同的迭代器print("\n=== 迭代器 ===")my_iterator = MyIterator([1, 2, 3])iterator3 = iter(my_iterator)# 输出:MyIterator.__iter__() 被调用iterator4 = iter(my_iterator)# 输出:MyIterator.__iter__() 被调用print(f"两个迭代器相同吗?{iterator3 is iterator4}") # True## 生成两个完全相同的迭代器# 再来看,可迭代对象和迭代器的实际 for 循环print("\n=== 可迭代对象for循环演示 ===")print("第一次遍历可迭代对象:")for x in iterable:print(x) # 正常输出 1,2,3print("第二次遍历可迭代对象:")for x in iterable:print(x) # 再次正常输出 1,2,3print("\n=== 迭代器for循环演示 ===")print("第一次遍历迭代器:")for x in my_iterator:print(x) # 正常输出 1,2,3print("第二次遍历迭代器:")for x in my_iterator:print(x) # 无输出!已耗尽
总结:
for 循环的底层逻辑完全一致:都是
iter()+next()+StopIteration机制唯一区别:
iter()函数的返回值对于可迭代对象:
iter()返回新的迭代器对象对于迭代器:
iter()返回自身消耗性差异的来源:因为迭代器的
__iter__()返回自身,所以多次 for 循环使用同一个耗尽的状态设计原理:迭代器是"一次性读取"的工具,可迭代对象是"可重复读取"的数据源
6. 生成器
6.1 什么是生成器?
生成器是一种特殊的迭代器,它延迟计算值,只在需要时生成一个值,而不是一次性生成所有值。示例代码如下:
# 对比:列表 vs 生成器# 列表:一次性生成所有值,占用内存numbers_list = [x**2 for x in range(1000000)] # 占用大量内存# 生成器:按需生成,节省内存numbers_gen = (x**2 for x in range(1000000)) # 几乎不占内存
6.2 生成器的两种创建方式
6.2.1 生成器函数(yield)
def count_up_to(n):"""生成从1到n的数字"""count = 1while count <= n:yield countcount += 1# 使用counter = count_up_to(5)print(next(counter)) # 1print(next(counter)) # 2
6.2.2 生成器表达式
语法:iterator=(expression for item in iterable)
# 语法:(expression for item in iterable)squares = (x*x for x in range(10)) # 生成器表达式# 等价于def squares_func():for x in range(10):yield x*x
6.3 生成器函数详细用法解析
6.3.1 yield关键字的工作原理
def stateful_generator():"""演示生成器状态保持"""print("开始执行")value = 0while True:received = yield value # yield 返回value,暂停等待send()if received is not None:value = receivedelse:value += 1gen = stateful_generator()print(next(gen)) # 开始执行 → 0print(gen.send(10)) # 10 # send()函数实现双向通信print(next(gen)) # 11print(next(gen)) # 12
6.3.2 生成器的生命周期
def lifecycle_demo():"""演示生成器完整生命周期"""try:yield "第一阶段"yield "第二阶段"except ValueError as e:yield f"捕获异常: {e}"finally:yield "清理资源"yield "这行不会执行"gen = lifecycle_demo()print(next(gen)) # 第一阶段print(next(gen)) # 第二阶段print(gen.throw(ValueError("测试异常"))) # 捕获异常: 测试异常print(next(gen)) # 清理资源# print(next(gen)) # StopIteration
6.4 生成器案例—处理大文件
def tail_file(filename, n=10):"""模拟tail命令,读取文件最后n行"""with open(filename, 'r') as f:# 高效读取:不一次性加载整个文件lines = []for line in f:lines.append(line.rstrip())if len(lines) > n:lines.pop(0)yield from lines# 使用for line in tail_file('large.log', 5):print(line)
相关链接:
【零基础学Python】第九课:编程效率翻倍神器— 函数(function)
【零基础学Python】第十课:探索Python编程利器— 函数(扩展)
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 40个简单但有效的Linux Shell脚本示例
- 如何用Python网络爬虫爬取网易云音乐歌曲
- 金竹社区机器人/编程寒假班 | 社区合伙人项目,社区精选,家长省心之选
- 实战为王!MySQL+Python 可视化项目详解
- 只需20个Linux命令,让你的工作效率翻倍!
- AI-Python自然科学领域机器学习与深度学习技术——随机森林、XGBoost、CNN、LSTM、Transformer,从数据预处理到时空建模
- 【本周五开课】最新AI-Python自然科学领域机器学习与深度学习技术
- 《生命科学深度学习:附 Python Notebook 示例和练习(解码进化,1)》
- 新书推荐丨Python心理学应用
- 敲代码累了吗,写论文写不出来吗,来做个数学题换换脑子继续写
