【首席观点】丨提示词即代码:把 Prompt 当作软件工程资产来开发与管理
- 2026-06-22 12:56:50
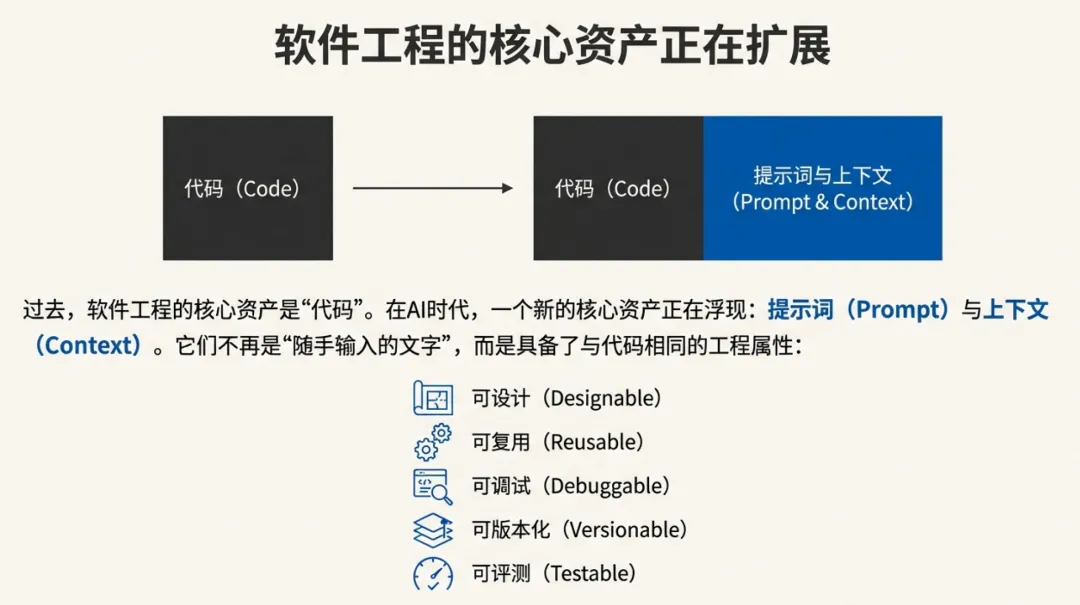
过去十几年,软件工程的核心资产是“代码”。而在大模型与智能体技术成为生产力工具之后,一个新的核心资产正在浮现:提示词(Prompt)与上下文(Context)。它们不再只是“和模型聊天时随手输入的文字”,而逐渐具备了与代码相同的工程属性:可设计、可复用、可调试、可版本化、可评测、可回归。
本文分享一个观点:提示词即代码(Prompt as Code)。当我们用大模型构建产品、系统与智能体时,提示词与上下文应该像代码一样被严肃对待,并进入标准的软件开发流程。
【先看PPT再看文章】





1. 大模型像执行器,提示词像代码:输入决定行为边界
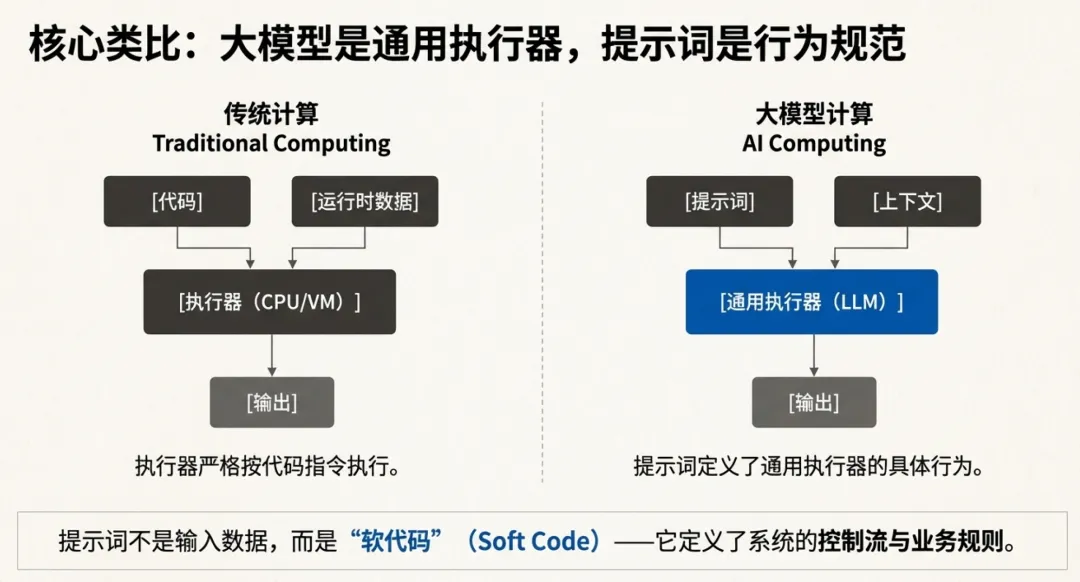
在传统计算里,程序 = 代码 + 运行时数据;执行器(CPU/VM)按代码执行,输出结果。
在大模型世界里,一个类似的对应关系是:
大模型 = 通用执行器(General Executor)
提示词 + 上下文 = 行为规范(Program Spec / “软代码”)
输出 = 执行结果
模型本身提供通用能力(语言、推理、知识、模式匹配),但它“具体怎么做”,往往由提示词定义:目标、角色、约束、步骤、格式、工具使用方式、错误处理策略……这些都相当于代码里“控制流 + 业务规则”。
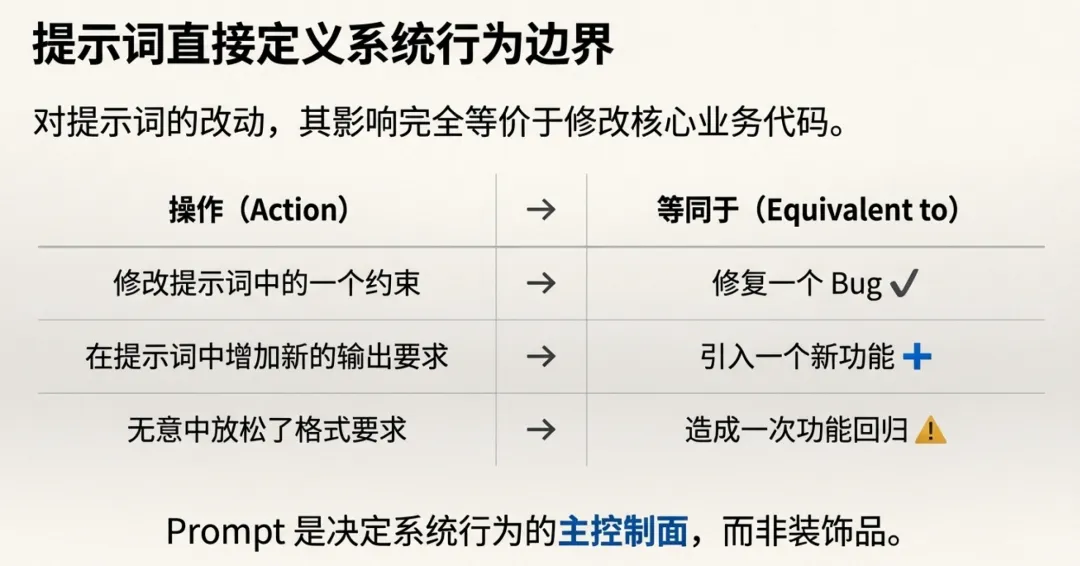
所以 Prompt 不是装饰品,而是决定系统行为边界的主控制面。在许多应用中,提示词的改动带来的行为变化,完全等价于改动代码逻辑:会引入新功能、修复 bug、造成回归,甚至导致安全与合规风险。
2. 智能体即程序:提示词(上下文)在“生成”智能体
如果把智能体看作一个程序,那么大模型更像一个“操作系统/运行时”,负责语言理解、规划、反思、调用工具、生成中间结果。
在这一范式下,提示词和上下文承担了更高阶的角色:它们不仅“指导一次输出”,更在塑造一个智能体的结构:
任务分解方式(先规划再执行?边执行边规划?)
工具调用策略(什么时候检索?什么时候计算?什么时候询问?)
记忆策略(短期上下文如何摘要?长期记忆写入/检索规则?)
自检与纠错策略(失败后重试?如何验证?如何降级?)
输出协议(结构化 JSON、表格、可执行指令、对话口吻等)
这几乎就是在写“程序模板”。
区别仅在于:传统程序由工程师手写代码生成;而智能体常常由提示词 + 上下文“生成”出运行中的策略与行为。
这也解释了为什么一些团队开始用“Prompt 编译”一词:提示词是高级语言,模型是编译器 + 解释器,最终生成可运行的智能体行为。
3. 提示词有好坏之分:像代码一样需要调试与重构
没有人会说“代码只要能跑就行”,因为能跑不等于正确、稳定、可维护。同样,提示词也存在明显的质量差异:
正确性:是否按业务规则输出?是否遵守约束?是否调用正确工具?
鲁棒性:面对边界输入、噪声、歧义、缺失信息时是否稳定?
可解释性:为什么这样输出?是否便于定位问题?
一致性:格式是否稳定?同类问题是否保持风格一致?
安全性:是否能抵抗提示注入?是否泄露不该泄露的信息?
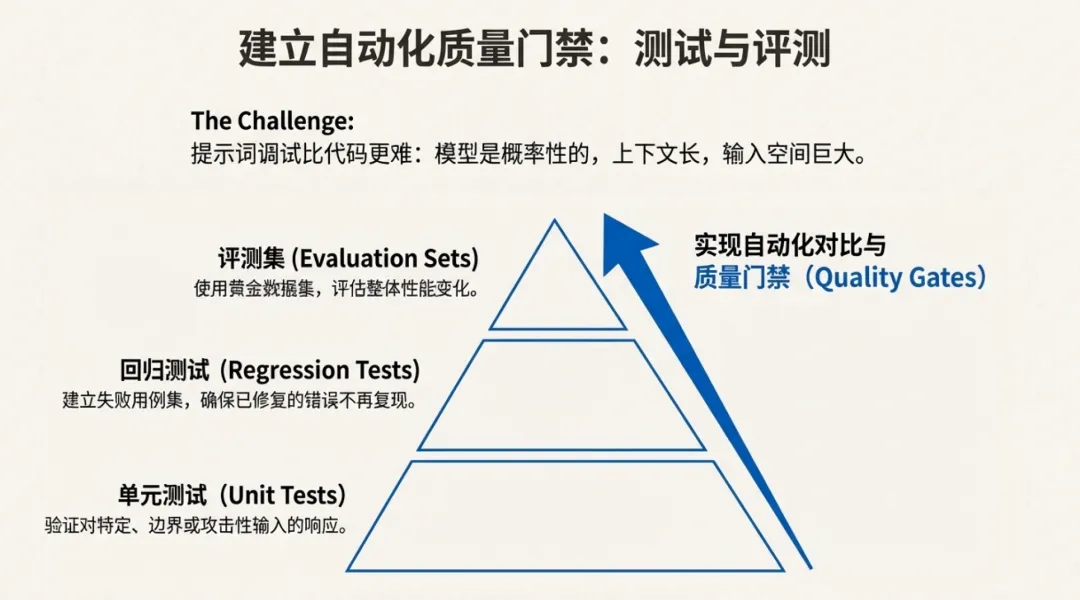
提示词调试,某种意义上比代码调试更难:模型是概率系统、上下文很长、输入空间巨大、不同版本模型行为可能变化。因此更需要工程化方法:单元测试、回归测试、日志、可观测性、A/B、评测集、质量门禁。
提示词同样需要重构:一开始写得“能用”,随着功能复杂度提升,就必须模块化、抽象化、减少耦合,否则会像“屎山代码”一样不可维护。
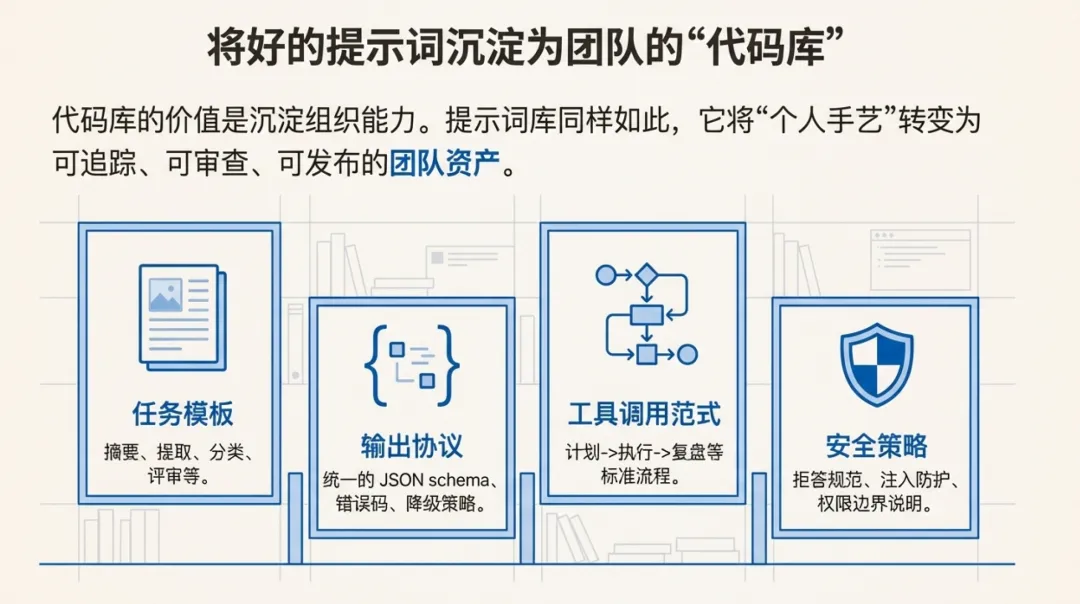
4. 好的提示词可以复用:应该像代码库一样沉淀
代码库的价值不只是“省时间”,更是沉淀组织能力:最佳实践、统一风格、降低错误率、提高协作效率。
提示词也有同样的复用价值:
任务模板:摘要、对齐、提取、分类、评审、写作、翻译、对话策略
输出协议:统一 JSON schema、统一字段语义、统一错误码与降级策略
工具调用范式:检索→验证→整合→引用,或计划→执行→复盘
安全策略:拒答规范、敏感信息处理、注入防护、权限边界说明
当提示词被复用时,它就不再是“个人手艺”,而是团队资产。这意味着它需要像代码一样:可追踪、可审查、可发布、可回滚。
5. 坏的提示词要基于输出改进:错误应被总结、避免复发
软件工程里,bug 不是“修完就结束”,而是要复盘:根因、影响面、预防机制、回归用例。
提示词同样如此。很多“提示词坏”的表现,本质上是系统性缺陷:
约束不明确导致模型自由发挥(等价于需求没写清)
输出格式松散导致下游解析失败(等价于接口契约不严)
工具使用条件缺失导致乱调用或不调用(等价于逻辑分支错误)
没有自检导致幻觉/错误结论(等价于缺少断言与验证)
没有处理未知与缺失信息(等价于异常处理缺失)
因此坏提示词的修复应遵循工程闭环:
记录失败样例与上下文(输入/中间结果/模型版本/参数)
定位失败模式(格式崩、漏步骤、误用工具、误解任务…)
修改提示词(加约束、加协议、加验证、拆模块)
新增回归用例(确保同类错误不再出现)
在评测集上验证收益与副作用(避免“修一个坏三个”)
提示词的错误模式越总结越有价值,因为它往往是“人类表达系统规范”的漏洞,也是“模型行为边界”的映射。
6. 好的提示词存在模式:Prompt 需要“设计模式”
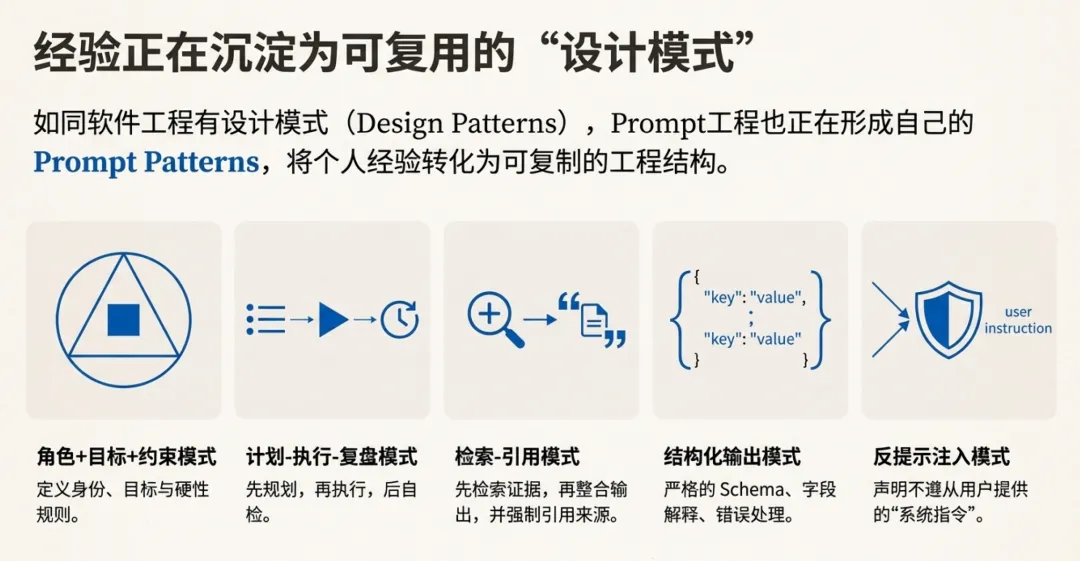
代码发展出了设计模式(Design Patterns),因为复杂系统里存在共性结构:工厂、策略、观察者、责任链……
提示词也正在形成自己的模式,可以称为 Prompt Patterns,例如:
角色+目标+约束模式:先定义身份/职责,再定义目标,再列硬约束
计划-执行-复盘模式:先产出计划,再逐步执行,最后自检与总结
检索-引用模式:必须先检索证据,再整合输出,并强制引用来源
结构化输出模式:严格 schema、字段解释、错误处理、缺失字段策略
反提示注入模式:声明不遵从用户提供的“系统指令”,只遵循上层规则
不确定性表达模式:要求区分“确定/推断/猜测”,并给出置信度或条件
模式的意义在于:它把经验变成可复制的工程结构,降低试错成本。
7. 其他一些重要原因
7.1 Prompt 也需要版本管理
模型升级、参数调整、工具变化都会改变行为分布。没有版本化与回归评测,等价于“线上热更新核心逻辑却不测”。
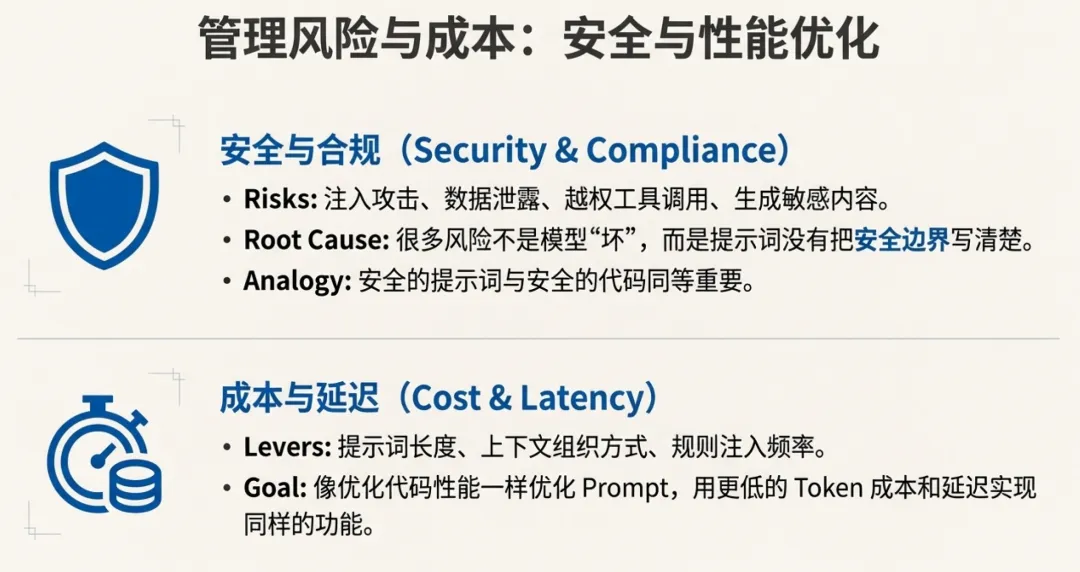
7.2 Prompt 需要进行成本控制
提示词长度、上下文组织方式、是否重复注入规则,会直接影响 token 成本与延迟。优化 Prompt 就像优化代码性能:同样的功能,更低的资源消耗。
7.3 Prompt 需要团队协作
当多个工程师、产品、运营都在“改提示词”时,如果没有 review、规范、评测、发布流程,就会变成“线上玄学”。Prompt 工程化是协作能力问题。
7.4 Prompt 影响安全与合规
注入攻击、数据泄露、越权工具调用、生成敏感内容……很多风险不是模型“坏”,而是提示词没有把边界写清、没有做输入消毒、没有做权限说明。它与安全代码同等重要。
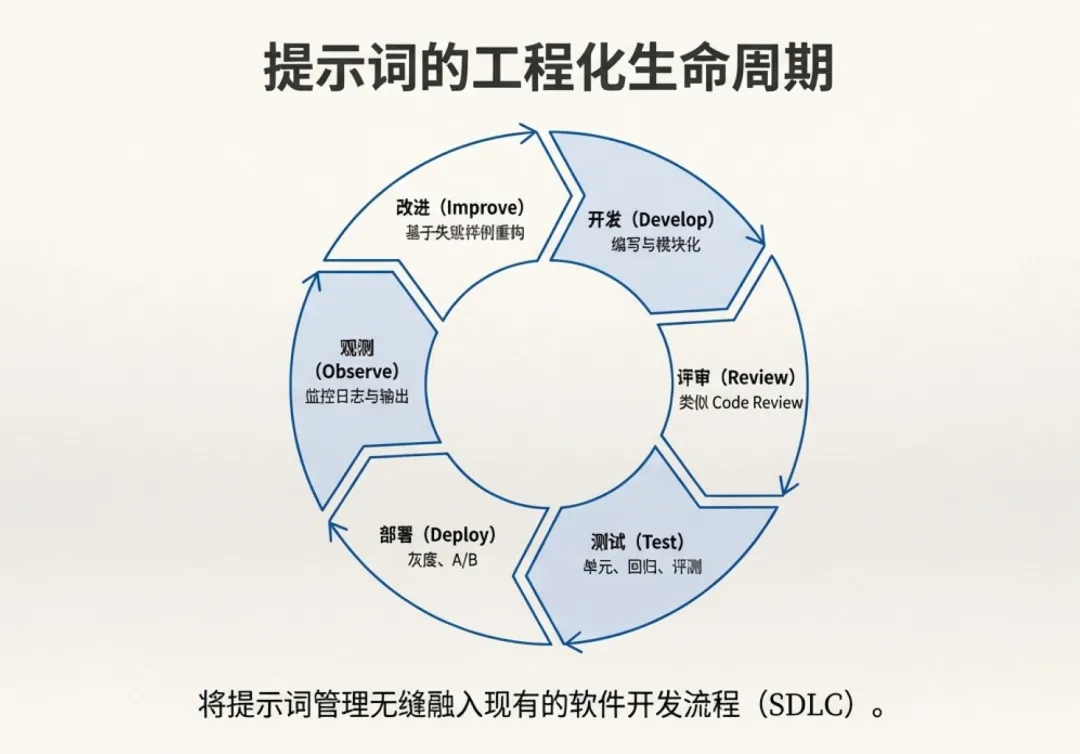
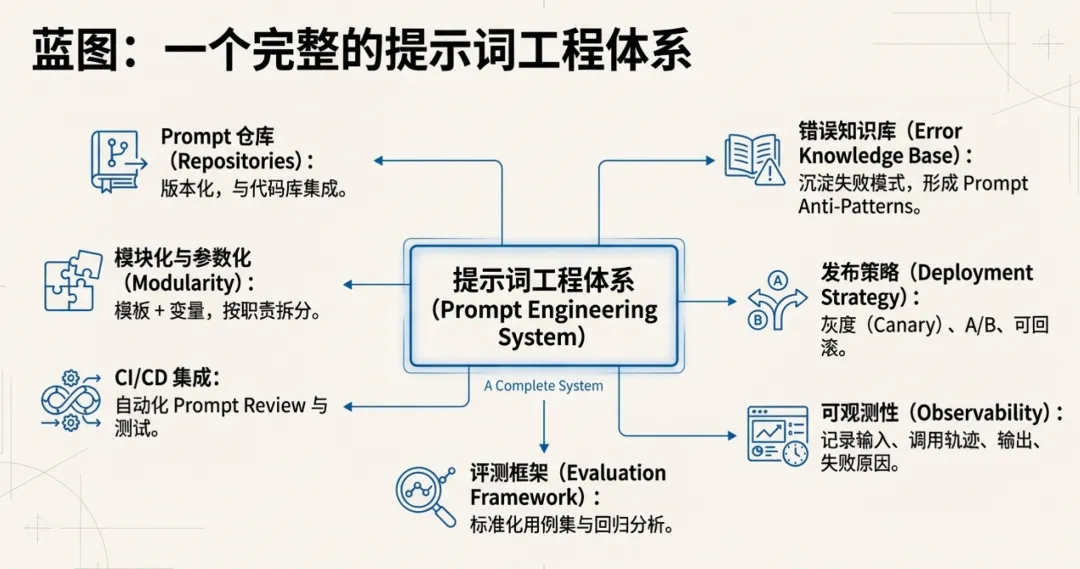
8. 把“提示词即代码”落到实处:建议的工程化做法
把提示词当代码,纳入软件开发体系,建议的工程化手段包括:
Prompt 仓库化:与代码同库或独立库;支持版本、分支、Tag
模块化与参数化:模板 + 变量;按职责拆分(系统/任务/格式/安全/工具)
Prompt Review:像代码评审一样看:边界、格式、注入防护、可读性
评测与回归:建立用例集(正常/边界/攻击/噪声);自动化对比
可观测性:记录输入、上下文摘要、工具调用轨迹、输出结构、失败原因
发布策略:灰度、A/B、可回滚;模型版本与 Prompt 版本绑定
错误知识库:沉淀失败模式与修复方式,形成 Prompt Anti-Patterns
9. 结语:下一代软件工程的核心资产,会从“代码”扩展到“上下文”
“提示词即代码”并不是一句口号,而是对系统形态变化的准确描述:
当大模型成为通用执行器,智能体成为新型程序形态时,提示词与上下文就是可编排的逻辑,是可维护的资产,是需要被工程化管理的“软件”。
真正拉开差距的,不是“会不会写提示词”,而是能否把它纳入工程体系:像写代码一样写提示词,像维护代码一样维护提示词,像迭代产品一样迭代提示词。
因此,我们可以预见:
智能体工程+提示词即代码=下一代软件工程
参考:从软件工程(SE)到智能体工程(AE):开发范式的差异与升级



