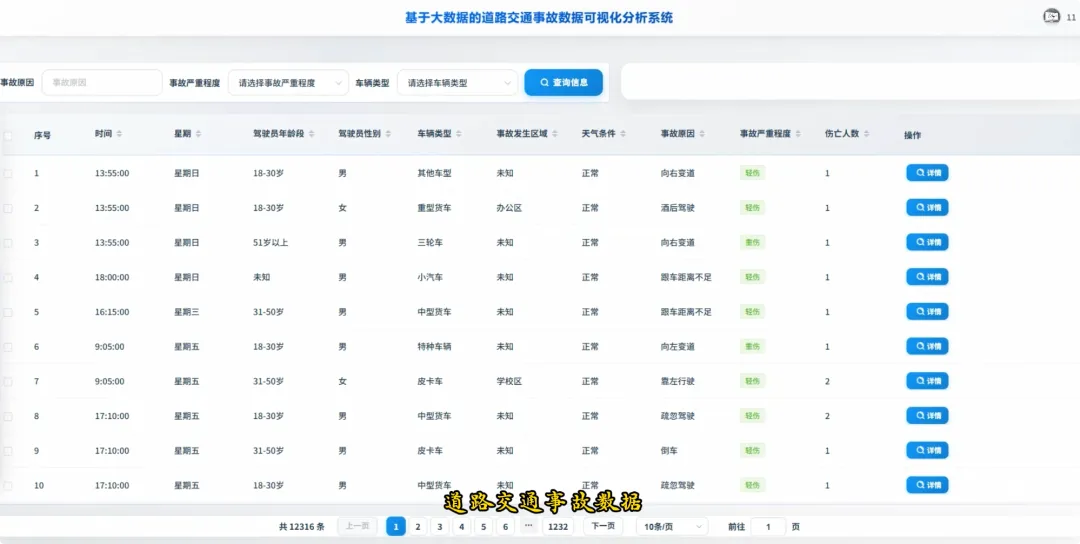
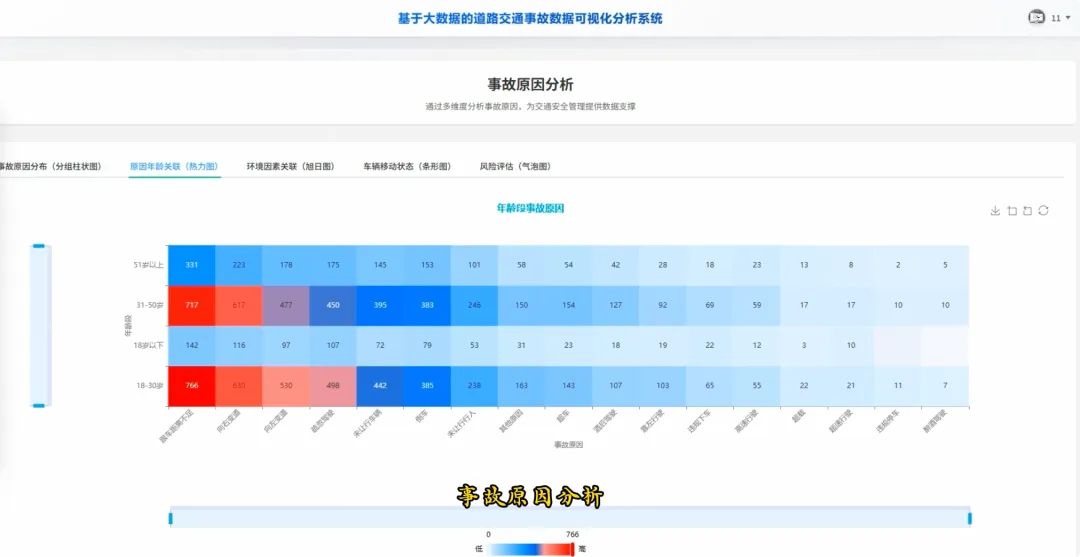
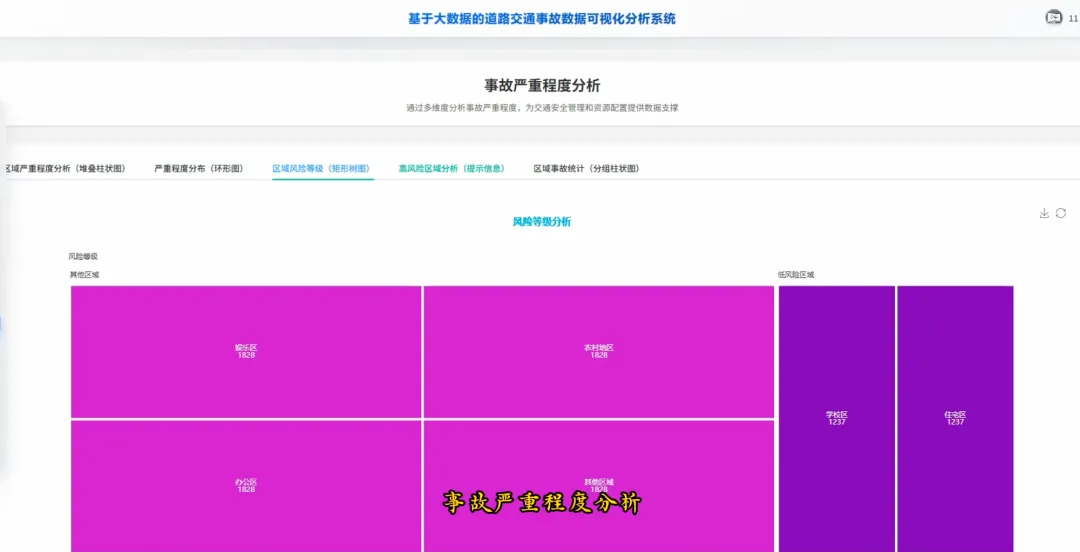
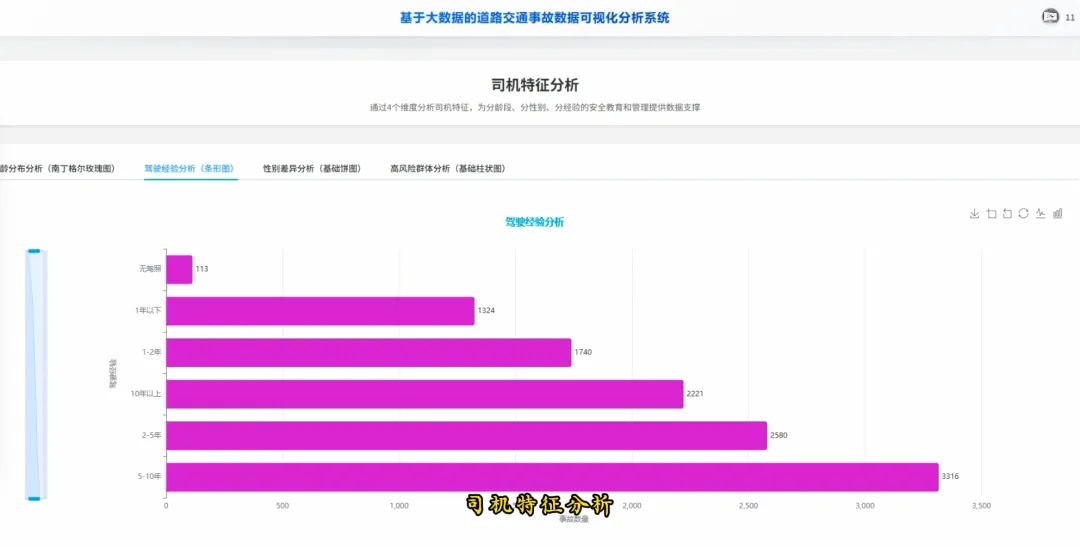
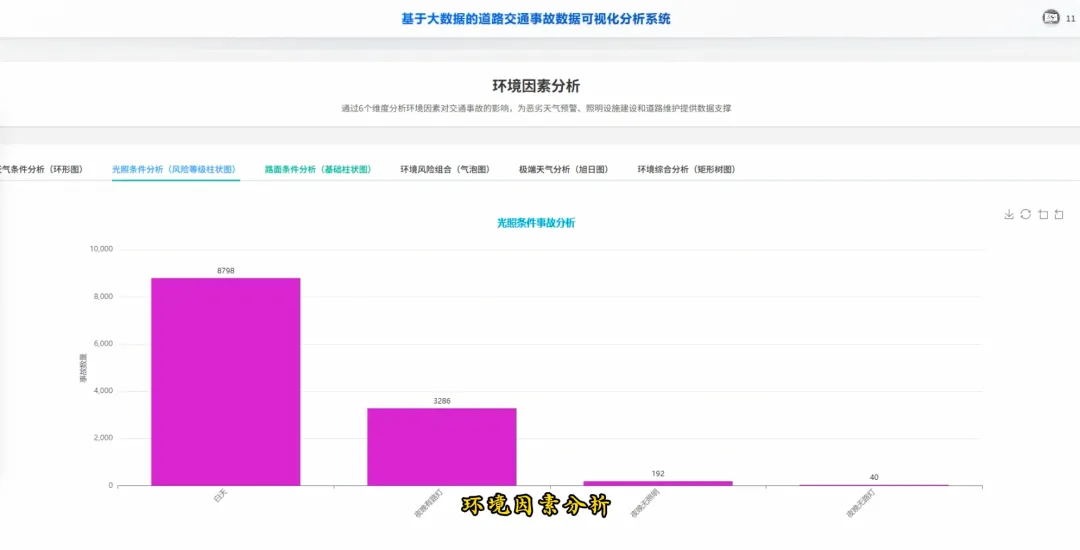
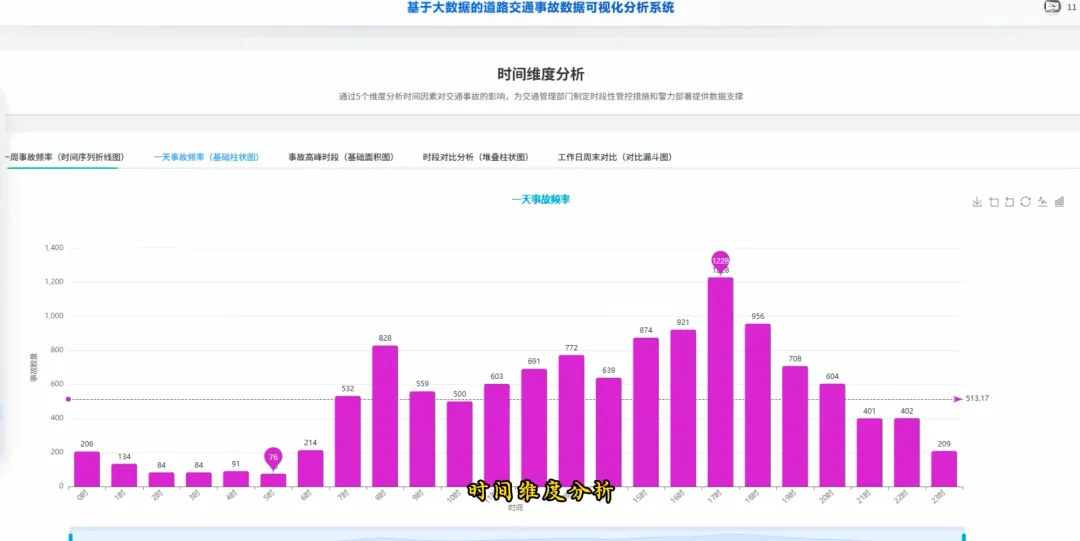
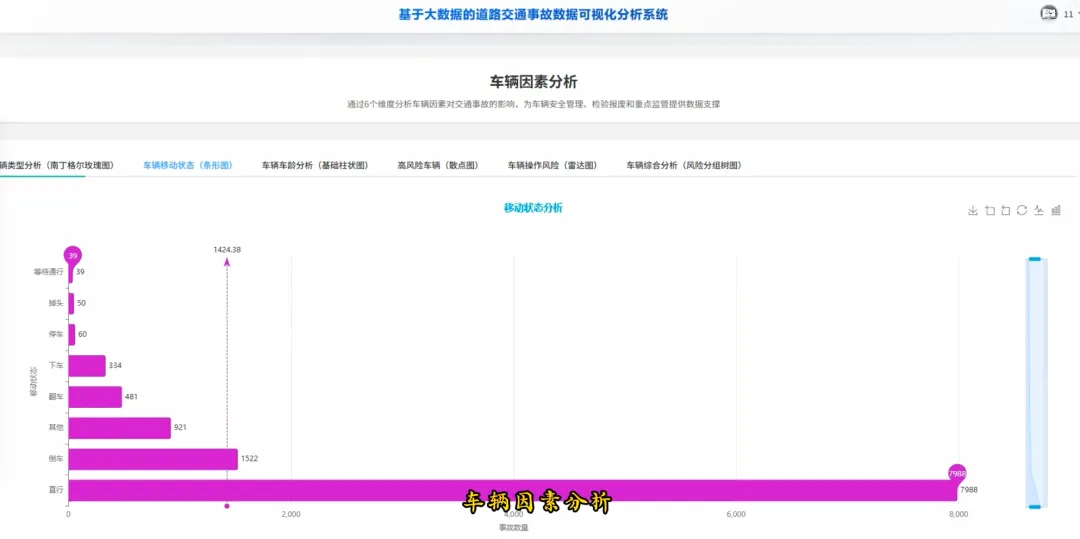
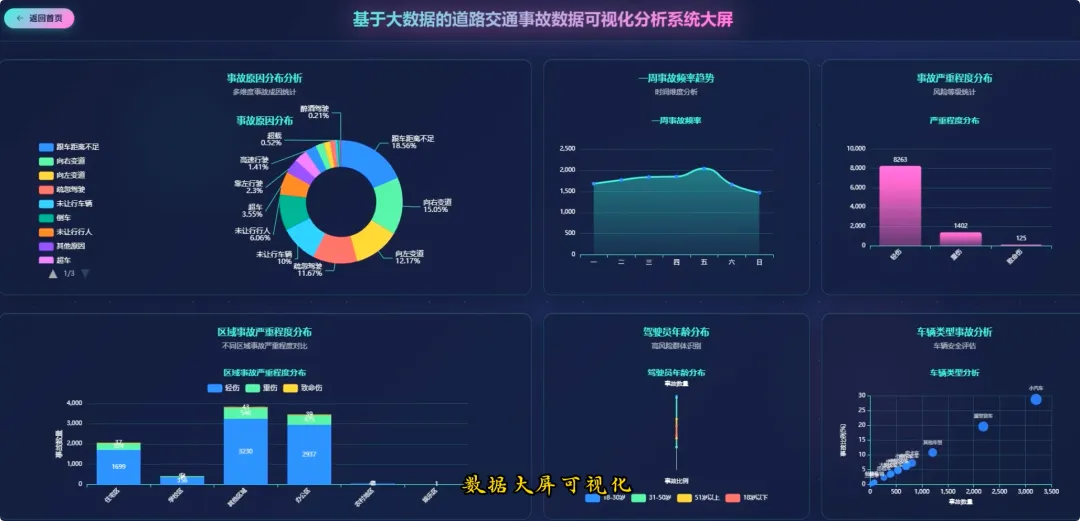
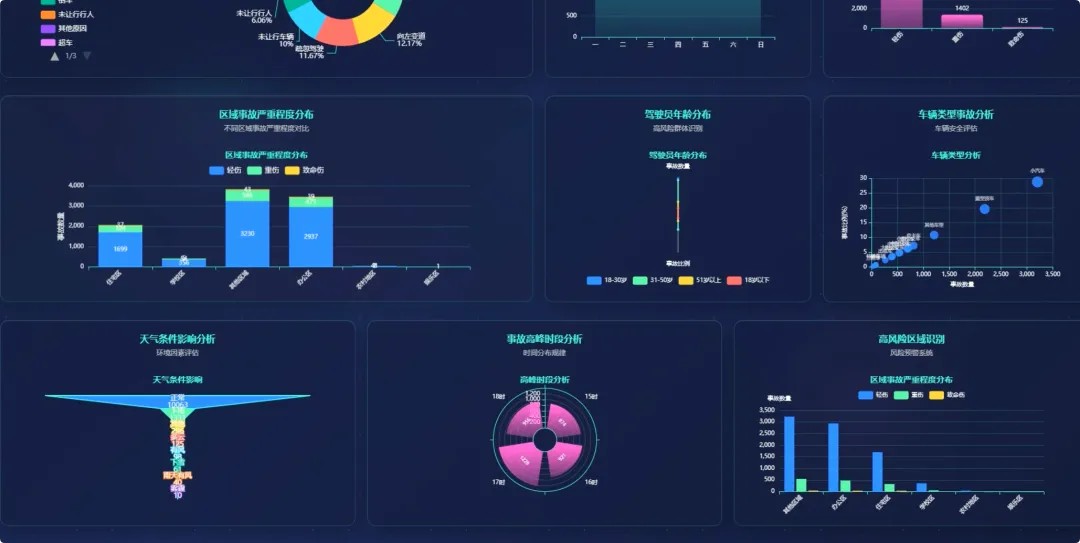
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("TrafficAccidentAnalysis").getOrCreate()df = spark.read.csv("hdfs://localhost:9000/accident_data.csv", header=True, inferSchema=True)df.createOrReplaceTempView("accidents")def analyze_weekly_accidents(): print("开始分析一周内事故发生频率...") result_df = spark.sql("SELECT Day_of_week, COUNT(*) as accident_count FROM accidents WHERE Day_of_week IS NOT NULL GROUP BY Day_of_week ORDER BY accident_count DESC") results = result_df.collect() print("分析完成,结果如下:") for row in results: print(f"星期{row['Day_of_week']}: {row['accident_count']}起事故") return resultsdef analyze_driver_age(): print("开始分析不同年龄段司机事故率...") result_df = spark.sql("SELECT Age_band_of_driver, COUNT(*) as accident_count FROM accidents WHERE Age_band_of_driver IS NOT NULL AND Age_band_of_driver != 'Unknown' GROUP BY Age_band_of_driver ORDER BY accident_count DESC") results = result_df.collect() print("分析完成,结果如下:") for row in results: print(f"年龄段 {row['Age_band_of_driver']}: {row['accident_count']}起事故") return resultsdef analyze_weather_severity(): print("开始分析天气条件对事故严重程度的影响...") result_df = spark.sql("SELECT Weather_conditions, Accident_severity, COUNT(*) as count FROM accidents WHERE Weather_conditions IS NOT NULL AND Accident_severity IS NOT NULL GROUP BY Weather_conditions, Accident_severity ORDER BY Weather_conditions, count DESC") results = result_df.collect() print("分析完成,结果如下:") for row in results: print(f"天气: {row['Weather_conditions']}, 严重程度: {row['Accident_severity']}, 事故数: {row['count']}") return results