论文标题:Reinforcement Learning via Self-Distillation
论文地址:https://arxiv.org/abs/2601.20802
论文作者:Jonas Hübotter, Frederike Lübeck, et al.
核心亮点:提出了SDPO(自蒸馏策略优化),无需外部教师模型,利用环境反馈(如报错信息)构建“回顾性”自教师,实现稠密的Token级信用分配。在LiveCodeBench上超越GRPO,准确率提升显著且生成内容更简洁。
关键词:强化学习、自蒸馏、RLVR、Rich Feedback、信用分配、大模型后训练
01. 引言
背景简述: 随着 DeepSeek-R1 等模型的爆发,基于强化学习(RL)的大模型后训练(Post-training)已成为提升推理能力的关键路径。目前的各种方法主要集中在可验证奖励的强化学习(RLVR),即通过代码执行结果或数学答案的对错来优化模型。
尽管 RLVR 取得了巨大成功,但主流方法(如 GRPO)仍面临严峻挑战:
- 信号稀疏与信用分配难:RLVR 通常只提供标量奖励(0或1)。模型只知道“错了”,但不知道“哪一步错了”。这种稀疏信号导致训练效率低下。
- 强教师依赖或资源瓶颈:为了获得更密集的信号,传统蒸馏方法依赖 GPT-4 等强教师模型,这在在线学习或探索新能力时并不可行。
- 推理冗长:为了“骗取”奖励,现有 RL 方法往往倾向于生成极长的思维链(CoT),导致推理效率降低。
本文提出了一种名为 SDPO (Self-Distillation Policy Optimization) 的新框架。其核心洞察是:大模型具备极强的“事后诸葛亮”能力(In-context Learning)。即模型虽然第一遍做错了,但在看到环境反馈(如编译器报错)后,往往能识别出错误。SDPO 利用这一点,将“看到反馈后的模型”作为Self-Teacher,将其概率分布蒸馏给“未看到反馈的学生(当前策略)”,从而实现无需外部教师的稠密信号学习。
如图 2 所示,SDPO 将传统的标量奖励扩展为富反馈(Rich Feedback),利用环境输出(如 Traceback)作为学习信号。
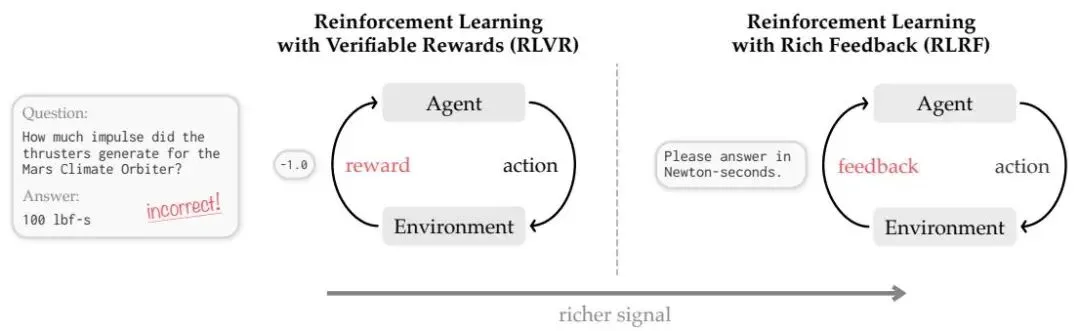 Figure 2: RLVR 与 RLRF 的对比。左侧 RLVR 仅使用标量奖励 ,丢失了环境状态信息;右侧 RLRF 利用 Token 化的负反馈(如运行时错误),为模型提供更丰富的信息。
Figure 2: RLVR 与 RLRF 的对比。左侧 RLVR 仅使用标量奖励 ,丢失了环境状态信息;右侧 RLRF 利用 Token 化的负反馈(如运行时错误),为模型提供更丰富的信息。
02. 问题痛点
- 信息瓶颈(Information Bottleneck):在代码生成或数学证明中,环境不仅会返回“通过/失败”,还会返回具体的错误信息(如
ZeroDivisionError 或 IndexError)。标准的 PPO/GRPO 直接丢弃了这些文本反馈,将其坍缩为标量 ,浪费了巨大的信息量。 - 信用分配的粗糙性:GRPO 等方法采用群组相对优势,对同一个输出序列中的所有 Token 赋予相同的优势值(Advantage)。这意味着模型无法区分“关键推理步骤”和“无关废话”,导致训练震荡。
- 探索的盲目性:在二值奖励设置下,如果模型未能生成任何正确答案,梯度往往为零,导致学习停滞(Cold Start 问题)。
03. 方案细节
整体架构: SDPO 的核心流程是一个在线的自蒸馏循环。它不引入额外的奖励模型(Reward Model)或价值网络(Value Network),而是利用策略本身在不同上下文下的表现差异来计算损失。
核心模块详解:
1. The Self-Teacher
这是 SDPO 的灵魂。对于输入问题 ,模型 生成了尝试 ,并从环境中获得了反馈 (例如报错信息)。
- Self-Teacher:,即同一个模型,但在 Prompt 中拼接了反馈信息。
- 逻辑:由于多了反馈 作为上下文,自教师对下一个 Token 的预测往往比学生更准确。
2. 稠密信用分配 (Dense Credit Assignment)
SDPO 不使用标量奖励计算优势,而是计算学生分布与自教师分布之间的差异。具体来说,它计算 Logit 级别的优势。
如图 4 所示,通过对比学生和自教师的 Log-probs,SDPO 可以精确地指出序列中哪些 Token 是“偏离”了正确方向的(红色部分),哪些是需要加强的。
 Figure 22 (原文对应Figure 4的详细版): SDPO 的稠密信用分配示例。红色表示自教师不认同学生的生成,蓝色表示认同。模型精准定位到了导致错误的 Token。
Figure 22 (原文对应Figure 4的详细版): SDPO 的稠密信用分配示例。红色表示自教师不认同学生的生成,蓝色表示认同。模型精准定位到了导致错误的 Token。
3. 数学原理与损失函数
SDPO 的目标是最小化学生策略与自教师策略之间的 KL 散度。其损失函数定义为:
其中 stopgrad 操作符阻止梯度流向教师(因为教师就是模型本身,我们需要它作为锚点)。 其梯度可以推导为 Logit 级的策略梯度,其中的“优势函数”变为了:
- 物理含义:如果某个 Token 在看到错误反馈后(教师视角)概率变高了,说明该 Token 是好的修正方向,优势为正;如果概率变低了(例如导致错误的那个 Token),优势为负。这实现了 Token 级别的细粒度奖惩。
04. 实验结果
实验设置:
- 数据集:LiveCodeBench v6 (LCBv6, 2025年发布的竞赛级代码题),以及科学推理(SciKnowEval)和工具调用(ToolAlpaca)。
- 基线模型:GRPO(目前最强的 RLVR 方法之一,类似 DeepSeek-R1-Zero 的核心算法)。
- 基础模型:Qwen3-8B, Olmo3-7B-Instruct。
主要结果 (Main Results) :
- 准确率显著提升: 在 LCBv6 上,SDPO 将 Qwen3-8B 的 Pass@1 准确率从 GRPO 的 41.2% 提升至 48.8% ,超越了 Claude 3.5 Sonnet 等强模型在公开榜单上的表现。如图 1 所示,SDPO 不仅最终效果好,而且收敛速度极快。
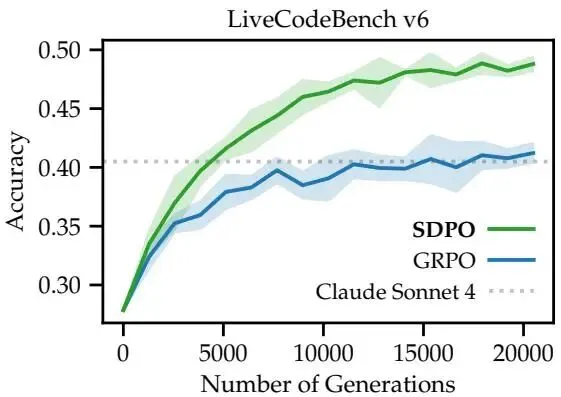 Figure 1: LCBv6 上的性能对比。SDPO(橙色)仅用 1/4 的步数就达到了 GRPO(蓝色)的最终性能,且最终上限更高。
Figure 1: LCBv6 上的性能对比。SDPO(橙色)仅用 1/4 的步数就达到了 GRPO(蓝色)的最终性能,且最终上限更高。
推理更简洁 (Conciseness) : 实验发现,GRPO 倾向于生成极长的“废话”来通过测试(例如反复输出 "Wait", "Hmm"),而 SDPO 生成的答案平均长度仅为 GRPO 的 1/3(见文中 Table 8,SDPO 255 tokens vs GRPO 820 tokens),且准确率更高。这意味着 SDPO 优化了推理的质量而非单纯堆砌长度。
Scaling Law (扩展性分析) : 作者在 Qwen 系列(0.5B 到 8B)上测试发现,模型越大,SDPO 相对 GRPO 的优势越大(见 Figure 8)。这是因为大模型的 In-context Learning 能力更强,构建的“自教师”质量更高。
在线 A/B 测试与工程性能:
- 计算开销:虽然 SDPO 需要计算两次 Forward(一次学生,一次教师),但得益于 KV Cache 和并行的 Log-prob 计算,实际训练时间仅比 GRPO 略微增加,且由于收敛快 4 倍,总训练成本大幅降低。
- Test-Time Training :在极难的二值奖励任务上,SDPO 可以作为一种 TTT 方法。如图 13 所示,在测试阶段对单题进行自蒸馏,SDPO 发现解的概率显著高于 Best-of-K 采样和多轮对话。
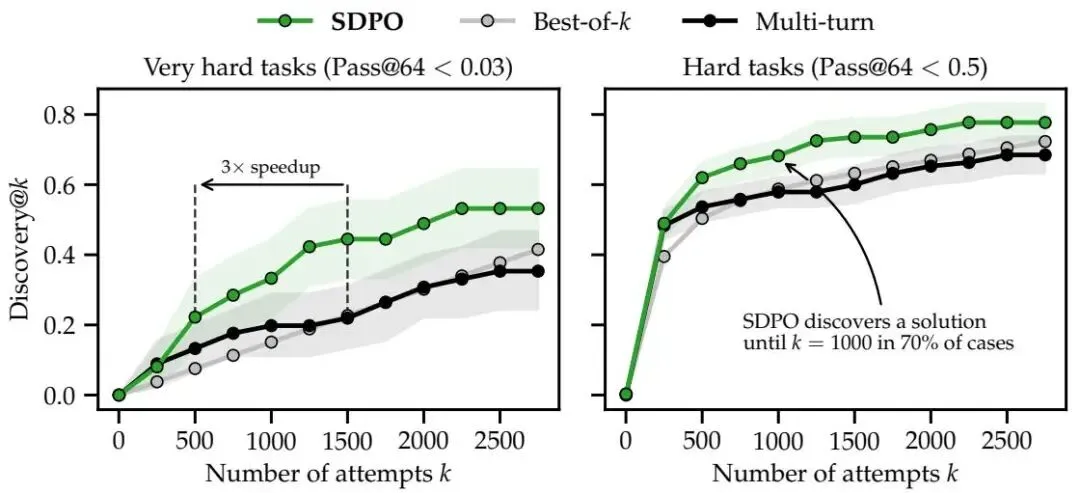 Figure 13: 在极难题目上的发现概率(Discovery Probability)。SDPO(橙色)显著优于多轮对话和 Best-of-K 采样。
Figure 13: 在极难题目上的发现概率(Discovery Probability)。SDPO(橙色)显著优于多轮对话和 Best-of-K 采样。
个人一点思考,限制 RL 效果的不是算法本身,而是反馈信号的贫瘠。既然 LLM 具备通过上下文学习(ICL)来利用反馈进行自我修正的能力,为何不将其内化到参数更新中?
SDPO 的动机在于利用这种回顾性(Retrospection):让模型在训练阶段利用“未来的”反馈信息来指导“当下的”生成,从而把“Token级的调试信息”转化为具体的梯度更新信号。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
