800 行代码,从 while(true) 到状态机: Agent 架构演进实践,扩展性更强
- 2026-07-02 18:57:37
上篇文章,我们新增了 500 行代码,为我们的 agent 实现了 skills 的接入,这种渐渐式的加载上下文,的确是人类工程化思维的结晶。在测试的过程中,我发现,当任务复杂起来,当你 Agent 从 Demo 走向实际生产任务时,while(true) 的简洁会变成噩梦。所以本文记录我如何用 800 行代码完成架构升级,以及背后的设计思考。
问题的起点
我们的 Agent 最初只有一个简单的循环:
while (true) {const response = await llm.chat(messages);if (response.hasToolCalls) {awaitexecuteTools(response.toolCalls);continue; }return response.content;}这 10 行代码支撑了早期所有功能。简洁、优雅、一目了然。
它其实就是一个隐式的状态机,其实早期 langchain 这种 agent 框架也是这么个实现,这种方式有一些明显的问题。
所以,问题是什么呢?
我举四个让我们不得不改的场景
场景 1:用户问"它卡住了吗?"
一个测试同学跑来问:「Agent 跑了 2 分钟没反应,是卡住了还是在处理?」
我看了看代码,发现我也不知道。
while 循环里没有任何状态暴露。是在等 LLM 响应?在执行工具?还是真的卡住了?从外部完全无法判断。
痛点:状态黑盒,无法观测。
当然,其实可以在 tool-use 的前后增加日志,这种方式是可行的,但是,优雅性尚待商榷。
场景 2:LLM 陷入工具调用死循环
有一次,Agent 反复调用同一个工具,循环了 200 多次才因为 token 超限报错。
[工具调用] readFile -> 成功[工具调用] readFile -> 成功[工具调用] readFile -> 成功... (重复 200 次)[错误] token 超限LLM 有时会"犯傻",陷入无意义的循环。而我们的 while(true) 完全没有防护机制。
痛点:缺乏限制,无法自我保护。
当然,这种情况下,我们也能轻松想到,我也可以增加一个MAX_RETRY,这样基本也可以解决这个工具调用死循环的问题。
场景 3:前端状态不同步
Web UI 上有个 loading 指示器。问题是:Agent 都返回结果了,指示器还在转。
排查发现,assistant_end 事件有时会丢失,而前端只能被动等待事件,无法主动查询"现在到底完成没有"。
痛点:事件驱动的脆弱性,缺乏状态同步机制。
这种时候,还真没好的办法,最好的办法就是能确确当前在什么状态,llm 思考,还是工具调用,调用的结果是?
场景 4:想加"反思"功能加不进去
产品说要加一个功能:执行完工具后,让 Agent 反思一下结果对不对,不对就重试。
我盯着 while 循环看了半天:
if (response.hasToolCalls) {awaitexecuteTools(response.toolCalls);// 反思逻辑加在这里?// 重试逻辑呢?重新规划呢?continue;}加是能加,但代码会变成一团意大利面。而且这种"反思-重试-重新规划"的流程,本质上是一个状态流转问题,硬塞进 while 循环里会越来越乱。
所以,这个地方的痛点是,痛点:扩展性差,难以支撑复杂流程。,总结起来原因是,太封闭了,扩展性不太好,所以我们要想办法把它拆开来。
怎么招呢,不如做下来做设计推导,所以,我们需要什么?
从上面四个场景,我们提炼出核心需求:
而解决这些需求,最容易让人想到的是一个经典模式:有限状态机(FSM)。
状态机设计:Plan-Execute-Critique
你可能会问,为什么是这三个阶段?
这其实是参考咱们人类解决问题的方式:
1. Plan(规划):拿到任务,先想想怎么做 2. Execute(执行):按计划干活 3. Critique(评估):干完了,看看结果对不对
这不是我们发明的,而是 AI Agent 领域的经典范式。OpenAI 的 Function Calling、LangChain 的 Agent、AutoGPT 都是类似思路,我只是照搬过来而已。也许以后有更好的实现,我们需要思考的是,怎么能够实现这里的可扩展。
状态流转图
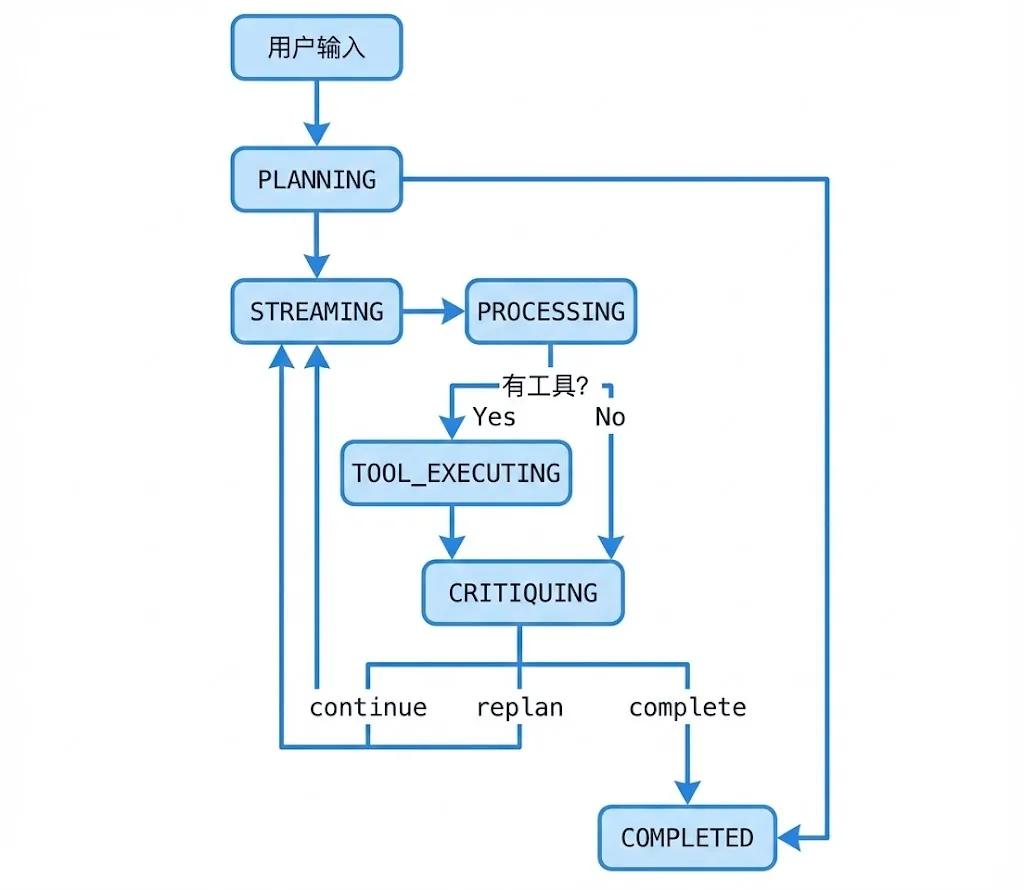
为什么要拆这么细?
你可能会问:为什么不只用 PLANNING、EXECUTING、COMPLETED 三个状态?
答案是:颗粒度决定了可观测性和可控性。
举个例子,如果只有一个 EXECUTING 状态:
• 用户问"在干嘛",你只能说"在执行" • 想单独给工具执行加超时,做不到 • 想在 LLM 响应后、工具执行前插入逻辑,没有切入点
拆细之后:
• STREAMING:正在接收 LLM 流式响应 • PROCESSING:正在解析响应内容 • TOOL_EXECUTING:正在执行工具
每个阶段都有明确的语义,可以独立监控、独立设置超时、独立插入逻辑。
这个地方的一个设计原则:状态的颗粒度应该与你需要的控制颗粒度匹配。
Critique 阶段的四种决策
Critique 是整个设计的关键。它回答一个问题:执行完了,下一步干什么?
{action: 'continue' | 'retry' | 'replan' | 'complete',reason: '判断依据',confidence: 0-100}四种决策对应四种场景:
这个设计让 Agent 具备了"反思"能力:不是闷头执行到底,而是每一步都会评估要不要调整。
限制机制:三道防线
回到"死循环"问题。我们设计了三道防线:
constLimits = {maxLoops: 50, // 最大循环次数maxToolCalls: 100, // 最大工具调用次数timeoutMs: 5 * 60 * 1000, // 总超时 5 分钟};为什么是这三个维度?
1. 循环次数:防止逻辑死循环(Plan→Execute→Critique→Plan...) 2. 工具调用次数:防止工具滥用(比如反复读同一个文件) 3. 总时间:兜底保护,无论什么原因,5 分钟必须结束
为什么是 50/100/5min?
这是经验值。我们观察了正常任务的分布:
• 90% 的任务在 10 次循环内完成 • 99% 的任务在 30 次循环内完成 • 工具调用次数通常是循环次数的 1-3 倍
所以 50 次循环、100 次工具调用,已经覆盖了 99.9% 的正常场景。超过这个数,大概率是出问题了。
状态同步的好处,什么时候该用状态机?
设计原则:事件用于过程通知,状态用于结果确认。两者结合才可靠。
不需要:
• Demo / PoC • 简单的单轮对话 • 不需要观测和控制的场景
需要:
• 生产环境 • 复杂的多轮任务 • 需要 UI 展示状态 • 需要限制和保护机制 • 未来可能扩展流程
写在最好
从 while(true) 到状态机,本质上是从"能跑就行"到"可观测、可控制、可扩展"的转变。
800 行代码,换来的是:
1. 用户不再问"卡住了吗" 2. Agent 不再无限循环 3. 加新功能比较容易,只是增加新状态
总体上来讲,当我们系统复杂度增长时,架构必须跟上。
如果你也想学习从 0 开始做 Agent,欢迎交流。代码已小范围分享。我们这不是一个生产用的 agent,生产直接用 ClaudeCode 会很香,这个就是学习 agent 的本质,摸透各种工程化的思路是为什么。

