碾压!Axe异构布局编译器:跨设备统一编程模型,覆盖多GPU/TPU/Trainium
- 2026-06-26 23:44:01
Axe Layout 的提出,是机器学习系统领域向统一抽象迈进的重要一步。这种统一抽象的威力,是让开发者能够以接近手工调优代码的性能,轻松编写出高效利用最新 GPU 特性、实现通信计算重叠、并能跨 GPU 和 AI 加速器移植的复杂内核。Axe 不仅仅是一个编译器或 DSL,它更是一种思维范式。它试图弥合高层分布式编程与底层硬件微架构之间的语义鸿沟,为下一代机器学习编译器和框架奠定了坚实的基础。
在当今大模型时代,训练和部署像 GPT-4、DeepSeek-R1、Llama 这样的巨型模型,已不仅仅是算法创新的比拼,更是对底层计算系统的终极考验。模型参数动辄千亿,数据量浩如烟海,计算任务需要分布在成千上万的 GPU 或专用 AI 加速器上协同完成。
然而,如何高效地将数据和计算任务“摆放”在从设备集群到芯片内部寄存器的每一层硬件上,成为了一个极其复杂且分裂的系统难题。传统的解决方案往往“头痛医头,脚痛医脚”:
分布式框架(如 PyTorch DTensor、GSPMD)负责设备间的数据分片与复制; 设备级 DSL(如 Triton、CuTe)则专注于 GPU 线程块和寄存器级别的数据排布与计算映射。
这种割裂的抽象导致跨层优化困难,程序难以移植,更无法应对 GPU、TPU、Trainium 等异构硬件带来的挑战。

AXE: A Simple Unified Layout Abstraction for Machine Learning Compilers https://arxiv.org/pdf/2601.19092 9000 字,阅读 30 分钟,播客 12 分钟
PipeThreader:软件定义流水线驱动的 DNN 编译器,FlashAttention与Mamba2性能显著超越现有方案! 性能超传统库达 1.79×!AMD 提出 Triton 原生多 GPU 通信库 Iris:以 tile 级抽象实现 GEMM+All-Scatter 近峰值带宽 打破库依赖与 93% 峰值效率!Intel 提出 MLIR 驱动的编译器自动生成 NanoKernel 实现高性能矩阵乘法内核!性能媲美手工优化
今天,我们读一篇来自学术界和工业界合作者的重要论文《AXE: A Simple Unified Layout Abstraction for Machine Learning Compilers》。
这项工作提出了一种名为 Axe Layout 的革命性抽象,旨在用一套统一的“语言”,描述从设备集群、GPU 内存层次到 AI 加速器片上存储的完整数据布局与计算映射,并在此基础上构建了一个强大的编译栈。
实验表明,基于 Axe 生成的代码,性能可逼近手工调优的高性能内核,同时在编程效率和硬件覆盖率上实现了巨大飞跃。更多性能数据见后文。


unsetunset本文目录unsetunset
零、 关键问题 问题一:统一的代价——Axe 的跨硬件抽象是否牺牲了特定架构的极致性能? 问题二:抽象的边界——Axe 是否将硬件映射的复杂性重新交给了开发者? 小小的总结 :) 一、 挑战:跨越尺度的布局迷宫 1.1 分布式执行(Inter-Device) 1.2 内存与线程层次(Intra-Device) 1.3 硬件异构性(Heterogeneity) 二、 核心创新:Axe 布局抽象——命名轴的统一映射 2.1 分片(D - Shard) 2.2 副本(R - Replica) 2.3 偏移(O - Offset) 三、 Axe 编译器:多粒度感知的编程与编译 3.1 多粒度执行作用域(Execution Scopes) 3.2 携带布局的张量抽象(Tensor with Layout) 3.3 高阶算子与调度(Operators and Schedules) 3.4 布局操作与编译器分析 四、 效果评估:性能与生产力的双重胜利 4.1 在最新 GPU 上能否达到接近最优性能? 4.2 多设备执行能否提升? 4.3 能否支持异构硬件后端? 五、 相关工作对比:Axe 的独特定位 5.1 布局系统 5.2 深度学习编译器与 DSL 5.3 分布式机器学习框架 六、 总结与展望:迈向统一的软硬件协同栈
 交流加群请在 NeuralTalk 公众号后台回复:加群
交流加群请在 NeuralTalk 公众号后台回复:加群unsetunset零、 关键问题unsetunset
问题一:统一的代价——Axe 的跨硬件抽象是否牺牲了特定架构的极致性能?
Axe 声称实现从线程到设备的“统一布局抽象”,展示了在 NVIDIA B200、Trainium 等硬件上的性能数据,但实际异构硬件(如 NVIDIA Tensor Core、TPU/训练芯片)中,未深入探讨 Axe 布局【是否】在【某些特定硬件上】【无法】表达其最优内存布局如 Tensor Core 的特定 swizzle 模式、TPU 的脉动阵列布局,换句话说,其“统一”是否以牺牲特定硬件的最优布局为代价?若统一抽象不得不引入冗余或对齐约束,则可能在高性能计算场景中带来不可忽略的开销,论文中的性能对比是否充分证明了其在各类硬件上均能接近手工优化内核?能否澄清“统一”的真实代价与边界?
Axe 的统一抽象【并未】以显著牺牲硬件最优性为代价,论文中的实验数据表明其在多种硬件上能接近或达到手工优化内核的性能,但其“统一”能力仍依赖于布局表达式的正确构造,且在某些极端场景下【可能存在】表达性或优化空间上的妥协。具体来说,有下面几点:
Axe 在保持统一抽象的同时,通过其灵活的轴映射机制避免了严重的性能损失,且在论文涵盖的硬件和负载中表现出竞争力。然而,“统一”并不意味着在所有场景下都能自动达到硬件绝对最优,它依赖编译器或开发者正确构造布局,并且在面对未来新型硬件时,其抽象可能需进一步扩展。
问题二:抽象的边界——Axe 是否将硬件映射的复杂性重新交给了开发者?
Axe 的“多粒度、分布感知”编程模型依赖于开发者正确设置布局与执行作用域,这是否将复杂的硬件映射责任重新转移给了程序员?这与 Axe 试图降低开发成本的初衷是否矛盾?在实际使用中的“易用性”,论文示例显示开发者需显式指定
Layout中的轴映射、复制、偏移等细节,并正确使用with warp()、with cta()等作用域。这实质上要求程序员对硬件架构有深入理解,而非完全依赖编译器自动化。这与 Triton 等更高级的抽象(以线程块为集体单位)形成对比。看起来 Axe 在“抽象层次”上的定位模糊性,它究竟是面向编译器开发者的底层抽象,还是面向算法工程师的高层工具?
Axe 确实将部分硬件映射责任交给了程序员,但这是一种“可控的暴露”,旨在通过统一的抽象降低跨平台、跨层级的开发成本,而非完全隐藏硬件细节。其目标用户是系统开发者与高性能库作者,而非终端算法工程师。从下面几个角度来说:
| 目标用户定位 | with warp()、with cta())2. 面向人群:编译器开发者、内核库作者、框架集成者,非普通ML研究者3. 核心用途:用于构建ML编译器和框架,提供可重用、声明式操作符,替代冗余样板代码 |
| 与Triton/CuTe的对比揭示其定位 | |
| 降低的开发成本体现在何处 | |
| 与完全自动化的对比 |
Axe 并未将硬件责任“重新转移”给程序员,而是针对其目标用户(系统开发者)提供了一套比纯手写内核更高效、比全自动编译器更可控的抽象。其“降低开发成本”体现在跨硬件的一致性和布局驱动的代码生成上,而非完全免除硬件知识。这种设计选择与构建可维护、可移植的高性能内核库的需求是一致的。
小小的总结 :)
Axe 的核心贡献在于提供了一套表达力强、跨层级统一、编译器可推理的布局抽象,并在实验中证明其能在多种硬件上实现接近手工优化的性能。 它的设计哲学是暴露必要的硬件控制,但通过统一抽象降低跨平台与跨层级的开发复杂度,适用于需要兼顾性能与可移植性的系统级开发场景。
unsetunset一、 挑战:跨越尺度的布局迷宫unsetunset
要理解 Axe 的价值,首先需看清当前深度学习系统在布局(Layout)与映射(Mapping)上面临的三重挑战,如图 1 所示。
1.1 分布式执行(Inter-Device)
当模型太大,单设备无法容纳时,我们必须将模型或数据分割到多个设备上。这涉及到数据分片(Sharding)、复制(Replication) 和设备网格(Device Mesh) 上的放置策略。不同的策略(如数据并行、模型并行、专家混合并行)对应不同的通信模式如 All-Reduce、All-Gather,需要框架或编译器做出明确选择并优化通信与计算的重叠。
1.2 内存与线程层次(Intra-Device)
在单个 GPU 或加速器内部,硬件具有复杂的层次结构:
内存层次:全局内存 -> 共享内存 -> 寄存器。 线程层次:线程网格(Grid) -> 线程块(Block/CTA) -> 线程束(Warp) -> 线程(Lane)。
高效的内核必须精心设计数据如何在各级内存间分块(Tiling)、搬运,以及计算任务如何映射到线程层次上。特别是像 Tensor Core 这样的专用计算单元,要求特定线程组以特定格式协同读取寄存器中的数据。
1.3 硬件异构性(Heterogeneity)
硬件的世界并非只有 GPU。Google 的 TPU、AWS 的 Trainium 等 AI 加速器有着与 GPU 截然不同的内存架构(如多维暂存器、存储体约束)。即便在 NVIDIA 家族内部,从 Ampere 到 Hopper 再到 Blackwell,Tensor Core 的片上数据格式和要求也在不断变化。编译器必须为每种硬件生成定制化代码,同时为程序员提供相对统一的体验。
现有的工作往往只聚焦于某一层:
GSPMD、Alpa擅长分布式;Triton、CuTe专注于 GPU 内核开发;Pallas、NKI则针对特定加速器。
缺乏一个贯穿多层的统一抽象,是系统优化道路上的一道鸿沟。
unsetunset二、 核心创新:Axe 布局抽象——命名轴的统一映射unsetunset
Axe Layout 的核心理念非常优雅:它将逻辑张量的索引,通过一组命名的轴(Named Axes),映射到一个多维的物理空间坐标上。这个物理空间可以涵盖设备 ID、GPU 线程束、内存存储体等任何硬件资源。
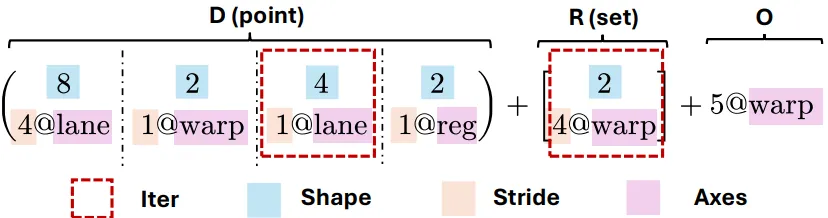
一个 Axe 布局 L 由一个三元组定义:L = (D, R, O)。让我们通过论文中的图 1 和示例来拆解它。
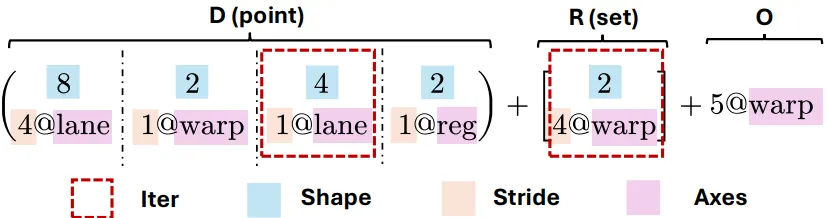
2.1 分片(D - Shard)
是什么:一个有序的 Iter 列表。每个 Iter是一个三元组(范围, 步长, 轴),例如(8, 4@lane)表示在lane轴上,有 8 个连续元素,每个元素在物理空间中间隔 4 个单位。作用: D将逻辑索引空间划分到多个硬件轴上,产生一个基础坐标。它是对传统“形状-步长(shape-stride)”模型的泛化,允许步长与命名的硬件轴(如thread,warp,gpuid,sram_bank)绑定。示例:将一个形状为 (8, 16)的逻辑块映射到 GPU 线程和寄存器。可以表示为:D = ( (8, 4@lane), (2, 1@warp), (4, 1@lane), (2, 1@reg) )这表示逻辑索引被分解为8,2,4,2四个因子,分别分布在lane,warp,lane,reg轴上。
2.2 副本(R - Replica)
是什么:一个无序的 Iter 集合。这些 Iter 的枚举独立于逻辑索引。 作用:将 D产生的基础坐标进行复制或广播。每个副本 Iter 定义了一组偏移量,加到基础坐标上,从而在物理空间创建多个数据副本。示例:在 warp轴上复制 2 份,副本间间隔 4 个 warp:R = [ (2, 4@warp) ]
2.3 偏移(O - Offset)
是什么:一个固定的坐标偏移向量(每个轴一个整数值)。 作用:将所有坐标整体平移,用于数据对齐、预留资源或实现特殊的放置策略。 示例:在 warp轴上整体偏移 5 个单位:O = 5@warp
完整的映射公式:对于一个逻辑索引 x,Axe 布局产生一个物理坐标的集合:L(x) = { D(x) + r + O | r ∈ R }
如果 R 为空,则 L(x) 是单点集;否则,其大小等于 R 中所有 Iter 范围的乘积。
统一性的体现:让我们看图 2 中的例子,感受 Axe 如何统一不同场景。
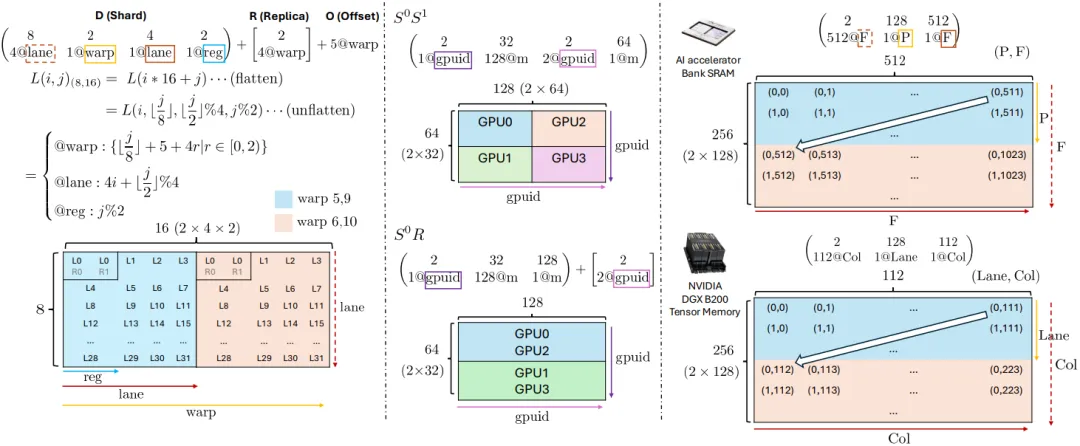
上图左列,中列、右列分别代表不同场景:
场景 A(GPU Tensor Core):描述一个适配 Tensor Core 指令的寄存器布局,涉及 lane、warp、reg轴。该场景聚焦单设备细粒度资源分配,8×16 张量块适配 GPU 的 warp - lane - reg 层级,D 拆解维度、R 实现数据复用、O 调整位置,充分发挥线程级并行性,减少交互开销场景 B(分布式 GPU 网格):描述一个矩阵在 4 个 GPU 间的分片与复制,涉及 gpuid_x、gpuid_y、m(内存)轴。这可以直接对应像S(0)S(1)(完全分片)或S(0)R(行分片并复制)这样的高层分布式策略。针对多 GPU 分布式场景,Axe 布局灵活实现全分片或分片 + 复制策略,全分片减少跨设备通信,分片 + 复制平衡通信与计算效率,适配 Alpa 等分布式框架并行策略场景 C(AI 加速器内存):描述数据在加速器专用内存(如片内 SRAM)中的排布,涉及分区轴 P和自由轴F。体现对异构加速器的适配,AI 加速器 SRAM 通过布局避免内存 bank 冲突,Blackwell GPU 张量内存布局适配专用存取指令,验证 Axe 可贯穿全硬件栈,为统一编译优化奠基。
可以看到,无论是设备间的分片,还是设备内寄存器的排布,亦或是加速器特殊内存的约束,都可以用同一套(D, R, O)语言来形式化地描述。 这为编译器进行跨层、跨硬件的统一分析和优化提供了可能。
unsetunset三、 Axe 编译器:多粒度感知的编程与编译unsetunset
有了强大的布局抽象,Axe 团队在此基础上构建了一个多粒度、分布式感知的编译器。其核心思想是:允许程序员在一个内核中,自由混合线程级别的细粒度控制和线程块/设备级别的集体操作语义,由编译器基于 Axe 布局自动推导出高效的硬件原生调度。
编译器的工作流程概览如下:

copy.async算子如何根据布局被 lowering 为线程绑定的循环,发出具体的硬件指令。左侧:GEMM 内核代码通过执行作用域明确硬件层级,kernel 覆盖所有线程,cta 限定线程块内操作,warp 针对线程束级计算。带 Axe 布局的张量定义是关键,共享内存张量确保线程块内数据高效共享,寄存器张量适配 warp 内线程访问模式,让编译器自动推断数据位置。 右侧上方:共享内存(shared memory)和寄存器(register)中的张量携带 Axe 布局信息,标注不同布局下迭代器的范围、步长与轴(如 “16@reg、4@lane、2@reg、1@lane、16@reg” 等)。 右侧中间:“tile” 工具通过规范化、分组、切片实现布局变换与匹配,将寄存器分片与 lane 轴组合形成 warp 级视图,识别适配张量核心指令的硬件原生布局,如 “8@reg、1@lane” 等布局的组合。 右侧下方:代码生成中,编译器依据 Axe 布局推导地址,生成绑定线程的循环和专用指令: copy.async算子被下转为绑定线程的循环,该循环发出cp.async.cg.shared.global指令,指令中的地址由 Axe 布局推导得出。开发者仅需关注高层逻辑,兼顾手写优化内核性能与开发效率,解决 “性能与效率难兼顾” 问题。
3.1 多粒度执行作用域(Execution Scopes)
Axe DSL 引入了显式的作用域概念,来界定一组线程(或设备)共同执行一个操作:
kernel: 内核启动的所有线程。cta(或block): 一个线程块。warp: 一个线程束。thread: 单个线程。device: 跨设备的集合。 程序员可以在不同作用域内编写代码,编译器会理解其语义。例如,在cta作用域内的一个copy操作,意味着整个线程块协同完成一次数据搬运。
3.2 携带布局的张量抽象(Tensor with Layout)
在 Axe 中,张量是一个一等公民,它携带了形状、数据类型、内存指针和至关重要的 Axe 布局信息。这使得编译器能够精确地知道每个张量元素在物理硬件上的位置。
# 示例:定义一个分布在4个GPU上,并在每个GPU内按特定方式排布的分布式张量input = Tensor(shape=(4, 64, 64), layout=((4, 64, 64), (1@gpuid, 64, 1)))3.3 高阶算子与调度(Operators and Schedules)
Axe 提供了一组高阶算子(如
copy、gemm、reduce),类似于嵌入在原生内核语言中的集体库(如 CUB),但更加通用。关键创新在于算子的具体实现(调度)是根据操作数张量的 Axe 布局和当前执行作用域,由编译器自动分派的。
同一 copy算子,用在thread作用域操作寄存器张量,可能被编译为简单的寄存器移动指令。用在 cta作用域从全局内存拷贝到共享内存,可能被分派为向量化加载指令或异步拷贝指令(如cp.async)。如果源和目的张量分布在不同的设备上, copy可能会在底层被翻译为一个all-gather或broadcast集合通信操作。
3.4 布局操作与编译器分析
布局是编译器进行分析和优化的基石。Axe 定义了一组核心布局操作:
规范化(Canonicalize):将布局转换为唯一的标准形式,用于判断两个布局在语义上是否等价。这涉及消除范围为 1 的 Iter、合并相同轴上相邻的 Iter 等规则,详见论文附录 A,有点长本文略,下同。 分组(Group):给定一个逻辑形状 S,将 D 中的 Iter 列表分割或融合成连续的块,使得每个块的维度乘积等于 S 的对应维度。这是进行分块、切片等操作的前提,见附录 B。 分块(Tile / Kronecker Product):这是支持分块计算和利用 SIMD/张量核心指令的关键。给定两个布局 A 和 B,分块操作 A ⊗ B产生一个新布局,其中 B 布局作为“内部块”,A 布局作为“外部块”并按 B 的跨度(span)进行缩放,以确保内部块互不重叠,见附录 C。公式如下:f_{A⊗B}(x || y) = f_A(x) ⊙ span(f_B) + f_B(y)切片(Slice):给定一个张量布局和它的一个逻辑子区域 R,推导出该子区域对应的布局 L[R:S],使得其映射与原布局在该区域上完全一致。这允许编译器只对感兴趣的数据区域生成高效代码,见附录 E。
通过这些布局操作,编译器能够:
匹配硬件指令:判断某个张量(或切片)的布局是否符合特定硬件指令(如 Tensor Core、TMA 异步拷贝)的要求。 推导地址计算:自动生成从逻辑索引到复杂物理地址(可能涉及设备 ID、线程 ID、内存体偏移)的计算代码。 优化数据搬运:为 copy等算子选择最合适的实现方式。
unsetunset四、 效果评估:性能与生产力的双重胜利unsetunset
Axe 的实现基于 Apache TVM 的 TensorIR。评估围绕三个核心问题展开:
4.1 在最新 GPU 上能否达到接近最优性能?
测试平台为 NVIDIA B200 GPU。对比基线为行业标杆 cuBLAS 和流行的 Triton。
FP16 GEMM:在多种来自真实模型(如 LLaMA-3.1, Qwen3)的权重形状上,Axe 达到了 cuBLAS 97%到 100%的吞吐量,而 Triton 约为 90%。Axe 的成功在于其 DSL 能轻松表达Warp 专业化和线程块集群(Thread Block Cluster) 等先进特性。例如,在 Blackwell 架构上,Axe 内核可以显式指定两个 SM 协同处理一个 GEMM 块,而 Triton 编译器自动生成的计划则未能利用此特性。 MoE 层:在 Qwen3-30B MoE 层推理中,对比 FlashInfer 和 SGLang(基于 Triton),Axe 获得了最高达 1.36 倍的加速。Axe 能够精细地编排第一组和第二组 GEMM 之间的流水线,实现计算重叠。

上图表示了不同输入 token 数量下 Qwen3 - 30B - A3B(FP16 精度)混合专家(MoE)层的延迟(ms,毫秒),数值越低表示性能越好。
4.2 多设备执行能否提升?
测试多 GPU GEMM+Reduce-Scatter 工作负载。Axe 将分布式张量、求和算子与计算融合在单个内核中,由编译器自动分派到
multinem.ld_reduce等底层原语。
对比非融合的 cuBLAS+NCCL基线以及Triton-distributed,Axe 实现了最高 1.40 倍的加速。关键在于Axe 在单个内核内实现了通信与计算的细粒度重叠,从而提高了内存带宽和 Tensor Core 利用率。

4.3 能否支持异构硬件后端?
测试平台为 AWS Trainium-1 AI 加速器。对比基线为供应商手工优化的 NKI 库。
FP16 GEMM:Axe 生成的代码性能与手工 NKI 库完全匹配。 多头注意力(MHA):Axe 实现了平均 1.26 倍,最高 1.44 倍的加速。通过更优的软件流水线和内存分配计划超越了手工实现。 生产力:手工 NKI 实现需要 120 行代码(GEMM)和 1188 行代码(MHA),而Axe 仅需 78 行和 228 行。高级的 DSL 极大简化了调度和地址计算。
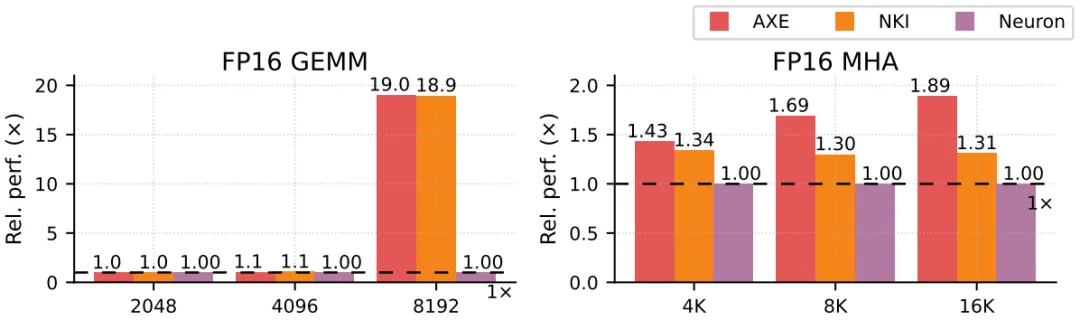
左图 FP16 GEMM 实验在 Trainium 1 AI 加速器上进行,Axe 在所有方形矩阵形状下均匹配手写 NKI 库性能,体现其对 AI 加速器硬件特性的适配能力。Axe 通过布局优化将矩阵块映射到加速器计算单元,适配硬件指令要求,充分利用硬件资源。 右图 MHA 实验中,Axe 相对 Neuron 编译器实现 1.26 倍平均提速,最高达 1.44 倍,其优势在于优化软件流水线调度与内存分配计划,减少数据传输延迟与内存访问冲突。Axe 代码量远低于手动优化的 NKI 实现,简化算子调度与地址计算,从高层生成高效 NKI 程序,验证其在异构硬件后端的优势,为跨硬件平台的深度学习编译提供统一、高效的解决方案。
unsetunset五、 相关工作对比:Axe 的独特定位unsetunset
5.1 布局系统
CuTe:Axe 继承了 CuTe 的形状-步长代数,并将其泛化。核心区别在于,CuTe 的映射是单值的,主要用于 GPU 内核内的工作划分和 TMA 地址计算;而 Axe 引入了命名轴和 (R, O),支持多值映射(副本),并天然覆盖分布式和异构硬件。线性布局(Linear Layouts):采用基于 F2 的位线性函数,对形状有 2 的幂次限制,在处理非 2 幂次形状(如某些分布式场景)时受限。Axe 的整数线性形式更为通用。
5.2 深度学习编译器与 DSL
Halide/TVM:算法与调度分离的开创者。Axe 更侧重于为异构、分布式环境定义统一的底层数据映射原语。 Triton:提供线程块级别的集体编程模型,隐藏线程级细节。Axe 则允许在同一内核中混合集体语义和线程级控制,兼具生产力和对尖端硬件特性的控制力。 CuTeDSL / Mojo / TileLang:这些 DSL 在不同层次上抽象数据布局和计算。Axe 的布局抽象可以作为它们底层的一个通用中间表示,增强其跨硬件和分布式的能力。
5.3 分布式机器学习框架
GSPMD / Alpa / PyTorch DTensor:这些框架在高层定义张量在设备网格上的分片。Axe 可以看作是其向设备内部的延伸,用同一套语言描述了分片张量在每个设备内部的具体内存和线程布局,使得跨层联合优化成为可能。 TileLink / Triton-Distributed:将集合通信引入内核。Axe 的分布式感知能力与之类似,但其基于统一布局抽象的设计更具扩展性和硬件无关性。
unsetunset六、 总结与展望:迈向统一的软硬件协同栈unsetunset
Axe Layout 的提出,是机器学习系统领域向统一抽象迈进的重要一步。它通过
(D, R, O)这一简洁而富有表达力的三元组,为数据与计算在跨越设备、内存层次和异构单元的物理空间中的放置,提供了一套共享的词汇表。
基于此构建的 Axe 编译器,验证了这种统一抽象的威力:它让开发者能够以接近手工调优代码的性能,轻松编写出高效利用最新 GPU 特性、实现通信计算重叠、并能跨 GPU 和 AI 加速器移植的复杂内核。
Axe 不仅仅是一个编译器或 DSL,它更是一种思维范式。它试图弥合高层分布式编程与底层硬件微架构之间的语义鸿沟,为下一代机器学习编译器和框架奠定了坚实的基础。未来,我们有理由期待 Axe 或类似的思想被更广泛地采纳,从而真正实现“编写一次,高效运行在任何 AI 硬件之上”的愿景。
端到端 LLM 编译器 nncase:基于 e-graph 的异构存储架构高性能统一编译框架 无需手动构建MegaKernels!Luminal 编译生成 MegaKernels:解决 GPU SM 负载不均,消除内核启动开销与内存气泡,适配任意架构! 性能相比SGLang/vLLM最高提升1.7倍!Mirage Persistent Kernel:首个自动巨核化多GPU LLM推理的编译器-运行时系统,细粒度计算-通信重叠

