科研绘图 | 基于Python 绘制环形柱状图:多模型多指标对比
- 2026-06-21 23:59:01
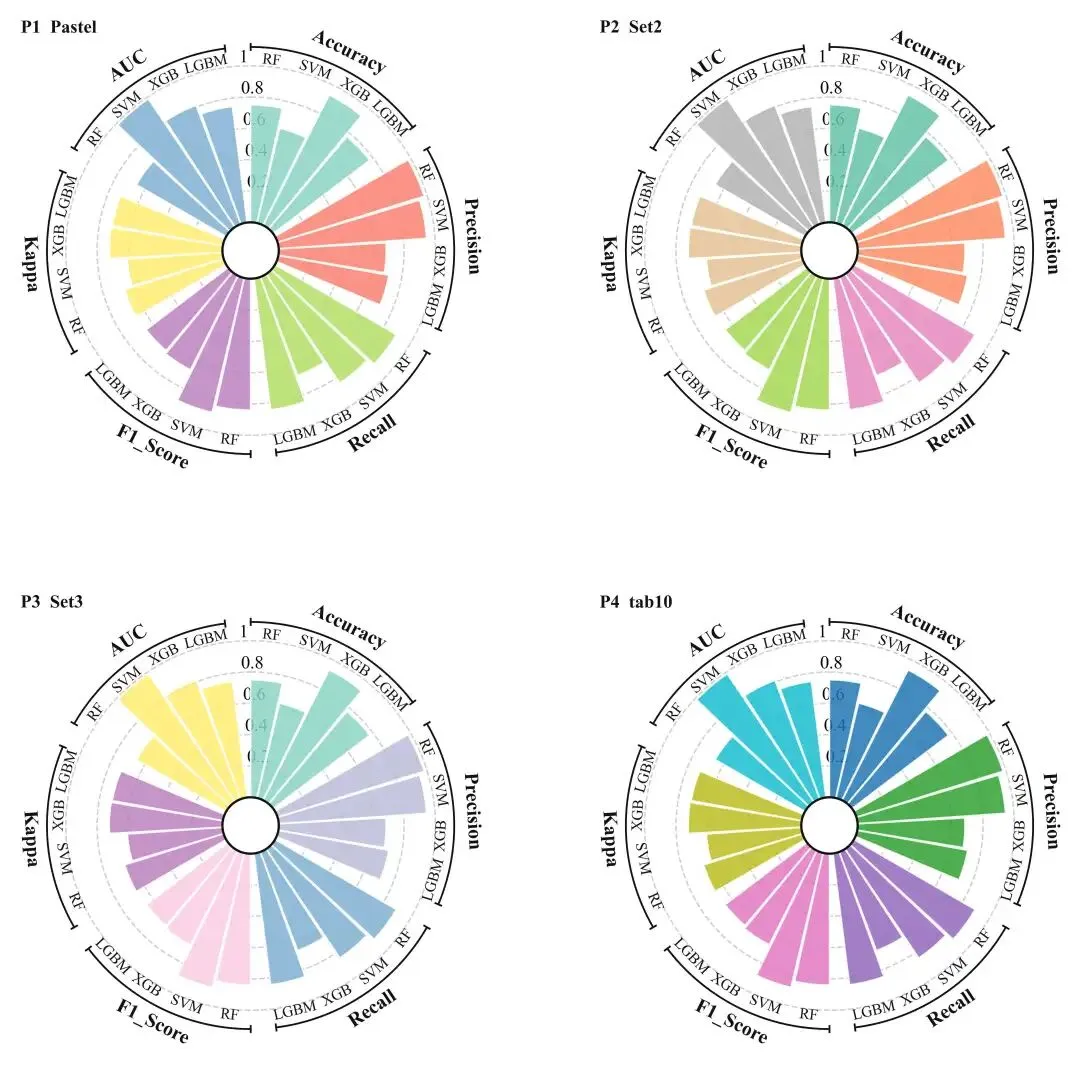
在做机器学习/统计建模对比时,经常同时关注多个指标:Accuracy、Precision、Recall、F1、AUC、Kappa系数……如果用普通柱状图,一张图往往只能清晰呈现 1 个指标;如果把多个指标堆在同一张直角坐标系里,又容易出现“又长又挤”的问题,读者很难快速抓住重点。
环形柱状图(本质上是“极坐标分组柱状图 + 中心留白”)提供了一个折中:把“指标维度”均匀铺在圆周上,把“模型维度”作为每个指标扇区内的并列柱,从而在一张图里同时表达“多指标 + 多模型”的整体格局,而且视觉上比雷达图更接近“可读的柱状比较”。
结果(四张子图也会单独导出)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
defset_style():
rcParams.update(
{
"font.family": "serif",
"font.serif": ["Times New Roman"],
"mathtext.fontset": "stix",
"font.size": 12,
"axes.linewidth": 1.0,
"figure.dpi": 300,
}
)
CSV_NAME = "model_performance.csv"
1)数据准备
环形柱状图最重要的一步不是画图,而是把数据整理好。建议使用最简单、最透明的表格:一行代表一个模型,一列代表一个指标。这样我们最终就能得到一个 values 矩阵,形状为 (n_models, n_metrics),后续所有角度、宽度、颜色的计算都能围绕它展开。
实践中有三个细节容易踩坑:
列名与顺序:你希望指标按什么顺序出现在圆周上,就应该在 CSV 里按这个顺序放列,或者在读取后显式排序;否则读者会觉得“指标位置怎么变了”。 类型强制:很多 CSV 会因为缺失值、千分位、字符串混入导致整列变成 object;绘图前必须把指标列强转为float。
下面的读取函数只做“必要且可解释”的处理:保留 Model 作为名称列表,其余列作为指标名与数值矩阵。
defread_table(csv_path: str):
df = pd.read_csv(csv_path)
if"Model"notin df.columns:
raise ValueError("CSV 必须包含 'Model' 列(模型名称)。")
model_names = df["Model"].astype(str).tolist()
metric_names = [c for c in df.columns if c != "Model"]
ifnot metric_names:
raise ValueError("未发现指标列:除 'Model' 外至少需要一列数值指标。")
values = df[metric_names].astype(float).to_numpy()
return model_names, metric_names, values
2)配色策略
在“多模型×多指标”的图里,颜色如果处理不好,读者会陷入“这根柱属于谁?”的反复确认。一个经验做法是:让颜色绑定到“指标”,而不是绑定到“模型”。原因很直观:指标在圆周上分组出现(每个扇区一个指标),当每个扇区的柱都用同一种颜色,读者无需额外图例就能知道“这一组代表什么指标”;而模型名称可以通过沿外圈的文字标注来识别。
当然,颜色绑定也不是绝对规则:当模型数量很少、指标很多时,绑定模型颜色也有优势。本文先采用“指标上色”的策略,并用 Matplotlib 的 colormap 生成离散色板,避免手工配色的维护成本。为了让印刷与屏幕都更舒服,通常会避开 colormap 的两端极值(太浅/太深),只取中间段颜色。
import matplotlib as mpl
defpalette_colors(cmap_name: str, n: int):
cmap = mpl.colormaps.get_cmap(cmap_name)
if n <= 1:
return [mpl.colors.to_hex(cmap(0.5))]
xs = np.linspace(0.12, 0.88, n) # 避开两端极值
return [mpl.colors.to_hex(cmap(x)) for x in xs]
3)极坐标布局:把“分组柱”映射到圆周扇区
直角坐标系里,柱状图的“分组”通常靠 x 方向的离散位置来做;在极坐标里,对应的自由度就是角度 theta。我们的目标是把圆周(0 ~ 2π)切成 n_metrics 个“指标扇区”,扇区之间留一点缝(group_gap)作为视觉分隔;然后在每个指标扇区内部,再放 n_models 根并列柱,柱与柱之间留一点间距(bar_gap)。
另外,“环形”的关键在于中心留白:不是从 r=0 开始画,而是让每根柱从 bottom=hole 起步。这样就会形成一个清晰的内环空洞,既美观,也能减少中心区域的拥挤。
这一步会看到几个重要的参数:
hole_ratio:内圈空洞占“最大数值半径”的比例,决定图的“环宽”。group_gap_ratio:各指标扇区之间的角度缝隙比例,决定分组分隔感。bar_gap_ratio:扇区内部柱与柱之间的间距比例,决定密度与可读性。
参数并不存在唯一最优解,合理的原则是:先确保“读得清”,再追求“摆得满”。
deflayout_params(n_models: int, n_metrics: int, *, hole_ratio=0.18, group_gap_ratio=0.02, bar_gap_ratio=0.06):
total = 2 * np.pi
group_gap = total * group_gap_ratio
group_span = (total - group_gap * n_metrics) / max(1, n_metrics)
# 每个指标扇区里,放 n_models 根并列柱
bar_gap = group_span * bar_gap_ratio / max(1, n_models)
bar_width = (group_span - bar_gap * (n_models - 1)) / max(1, n_models)
return {
"total": total,
"group_gap": group_gap,
"group_span": group_span,
"bar_gap": bar_gap,
"bar_width": bar_width,
"hole_ratio": hole_ratio,
}
4)文字沿切线摆放:让标签跟随圆周、避免倒着读
环形柱状图的“高级感”很大一部分来自文字排版:模型名与指标名如果像普通极坐标那样横着放,往往会出现大面积重叠;如果简单按角度旋转,又会出现“上半圈是正的,下半圈是倒的”,读者读起来非常别扭。
一个常见做法是:把文字旋转成“贴着圆周切线”的方向,并且做一次“可读性纠正”——当文字角度翻到背面时,额外加 180° 让它回到正向。这样读者沿着外圈扫一圈,基本不会遇到倒置文字。
下面这个 tangent_text 是整张图可读性的关键小工具:它根据 Matplotlib 当前的极坐标方向与偏移(theta_direction、theta_offset)推导显示角度,再计算合适的旋转角。
deftangent_text(ax, theta, r, text, *, fontsize=10, fontweight="normal"):
# 把数据坐标的 theta 转成屏幕显示的角度(考虑方向与偏移)
display_theta = ax.get_theta_direction() * theta + ax.get_theta_offset()
angle_deg = (np.degrees(display_theta) + 360) % 360
# 切线方向:角度 - 90°
rotation = angle_deg - 90
rotation = (rotation + 180) % 360 - 180# 归一到 [-180, 180]
# 让文字始终“正着读”
if rotation < -90or rotation > 90:
rotation += 180
rotation = (rotation + 180) % 360 - 180
ax.text(
theta,
r,
text,
ha="center",
va="center",
rotation=rotation,
rotation_mode="anchor",
fontsize=fontsize,
fontweight=fontweight,
color="#111111",
zorder=30,
)
5)总结与调参清单:让图“更像你的图”
到这里,已经可以用一份相对精简的脚本稳定画出“多模型×多指标”的环形柱状图了。核心思路是(1)把数据变成矩阵;(2)把指标均匀映射到圆周分组;(3)在每个分组内并列画模型柱;(4)通过 bottom=hole 做出内圈空洞;(5)用切线排版解决文字可读性。
这套思路的价值在于它非常“工程化”:当你换数据集、换指标列、换模型数量时,只要表格结构不变,图形逻辑就基本不需要改。
现在绘图代码都不支持免费获取了,20/篇文章。同时欢迎加入小编科研绘图VIP群,198/年,保证每年更新40篇以上的科研绘图相关文章,涵盖机器学习模型(回归和分类)的shap分析、还有各种如皮尔逊分析等相关的图,以及期刊复现图,源代码直接复制或者打开就能绘图。同时进群还赠送微信推文中所有绘图代码以及科研绘图SHAP分析软件和依赖图分析软件,且免费更新使用。后期还会免费赠送一些科研绘图小软件,还有拼图软件(开发中)VX:GISyanjiushengya!!!

