2019年,土耳其籍数据科学家厄尔戈安・塔克斯森(Erdogan Taskesen)首次发布了benfordslaw库。
该库是专门为本福特定律(Benford's Law) 验证打造的 Python 第三方工具,核心作用是通过程序化方式检验数据集是否符合本福特定律,进而判断数据的真实性、完整性或是否存在伪造或篡改嫌疑。
本福特定律的核心规律是在自然产生的真实数值型数据中(无人工干预、无固定取值范围),数字的首位出现频率并非均匀分布,而是呈现对数衰减特征(1 出现约 30.1%、2 约 17.6%、3 约 12.5%……9 约 4.6%);若数据偏离这一规律,往往暗示数据可能被人为修改、伪造,或数据生成机制存在异常。
该库的检验能力可应用于多个需要数据真实性核验的领域,典型场景包括:
- 金融审计:检验财务报表、交易数据、税务申报数据是否伪造;
- 科研验证:核查实验数据、调研数据是否存在人为篡改(如为符合预期结果修改数据);
- 数据分析:判断业务数据(如用户行为数据、销售数据)是否自然生成,是否存在异常刷量 /造假;
- 法务取证:作为电子数据取证的辅助手段,验证涉案数据的真实性。
下面就来简单说说这个库吧。
步骤1:安装benfordslaw库
直接运行pip install benfordslaw即可。
步骤2:准备测试数据
这里我使用事先准备好的测试数据test.csv,为了简单起见,测试数据只有一个字段【金额】,行数为1000行。
步骤3:测试代码
# -*- Coding:UTF-8 -*-'''====================================================@File : 20260202-本福特定律测试.py@IDE : PyCharm 2024.3 Professional Edition@Version : Python 3.10.10@WebChat : victory54610@Date : 2026/2/2 07:42@Addr : JINCHENG ===================================================='''import pandas as pdfrom benfordslaw import benfordslawimport osos.chdir(r'E:\TestData')df = pd.read_csv('test.csv')data = df['金额'].valuesbl = benfordslaw()results = bl.fit(data)bl.plot()
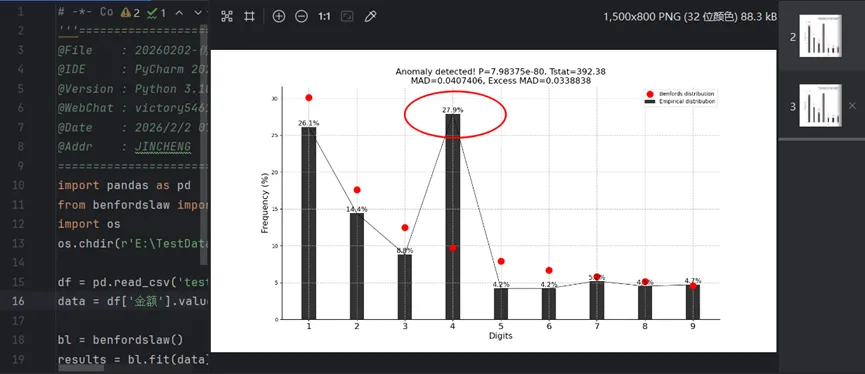
测试结果:
由于我伪造的测试数据有点夸张哈。但是很明显,首位数字4偏差很大,存在很大嫌疑。
特别提醒注意:
虽然这个工具很强大,但也要防范“聪明的造假者”。如果造假者懂本福特定律,他们会按照 30.1/%, 17.6%等等的比例去伪造数据,这时单一的本福特检验就会失效。
在这种情况下,我们通常会结合“第二位数字检验”或“最后两位数字频率分析”(检测是否有很多整数)来综合判定。
有兴趣的朋友可以自己继续深挖!哈哈哈!
今天的分享就到这儿啦,非常感谢您对“Python SQL审天下”公众号的关注和点赞。如果您觉得我的公众号能给您带来一丝丝的收获,请多多转发给您的朋友圈,让更多的人看到并了解。也许您不经意间的点赞和转发,会给他人带来独特的体验和感受。