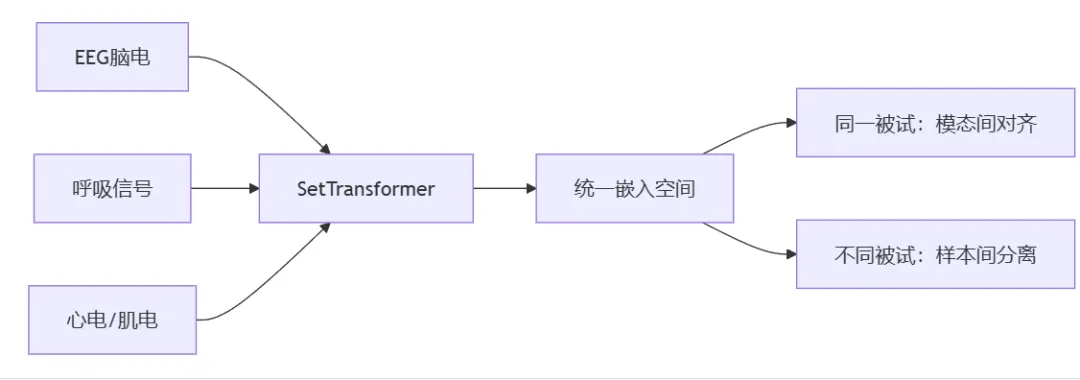
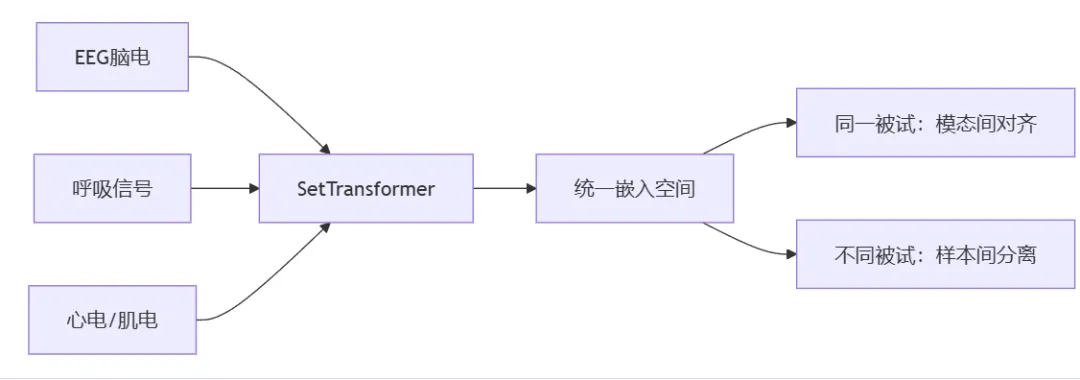
SleepFM是斯坦福大学Zou团队开发的多模态睡眠基础模型,基于超过58 万小时的多模态睡眠监测数据(PSG)训练而成
GitHub https://github.com/zou-group/sleepfm-clinical/blob/main
该模型能够:
- 从单夜睡眠记录中提取临床有意义的特征表示
- 预测130+ 种疾病风险(包括痴呆、心梗、中风、全因死亡率等)
- 在睡眠分期、呼吸暂停检测等传统任务上达到竞争性性能
四步部署实战(以MESA公开数据集为例)
✅ 前置准备:数据下载与目录结构
# 1. 下载 MESA 数据集(需申请)wget https://sleepdata.org/datasets/mesa -O mesa.tar.gztar -xzf mesa.tar.gz -C /data/# 2. 目录结构要求(必须严格遵循)/data/mesa/├── polysomnography/│ ├── edf/ # 原始EDF文件│ │ ├── mesa-sleep-0001.edf│ │ └── ...│ └── annotations-events-nsrr/ # 睡眠分期标签│ ├── mesa-sleep-0001-nsrr.xml│ └── ...└── demographics/ └── mesa-sleep-dataset-0.3.0.csv # 人口学特征
⚠️ 重要:SleepFM 要求 EDF 文件名与标签文件名严格匹配(如 mesa-sleep-0001.edf ↔ mesa-sleep-0001.csv)
📦 Step 0: PSG 预处理(EDF → HDF5)
# 创建预处理脚本(preprocess_mesa.sh)#!/bin/bashpython sleepfm/preprocessing/preprocessing.py \ --root_dir /data/mesa/polysomnography/edf \ --target_dir /data/mesa/hdf5_128Hz \ --resample_rate 128 \ --num_threads 8# 执行预处理(MESA约2000例,8核约2小时)bash preprocess_mesa.sh
关键配置:channel_groups.json 通道映射(MESA 特定)
{ "BAS": ["EEG(sec)", "EEG", "EOG(L)", "EOG(R)", "EMG"], "RESP": ["Airflow", "Thorax", "Abdomen", "SaO2"], "EKG": ["ECG"], "EMG": ["EMG"]}
⚙️ Step 1: 预训练SleepFM(对比学习)
# configs/config_set_transformer_contrastive.yamldata: hdf5_root: /data/mesa/hdf5_128Hz split_path: configs/dataset_split_mesa.json # 自定义8:1:1划分model: embed_dim: 128 num_heads: 8 num_layers: 6 patch_size: 640 # 5秒窗口 @128Hztraining: batch_size: 64 lr: 0.0005 epochs: 50 temperature: 0.1 # InfoNCE损失温度参数
# 启动预训练(单卡A100,MESA约50小时)python sleepfm/pipeline/pretrain.py \ --config configs/config_set_transformer_contrastive.yaml \ --save_path ./checkpoints/mesa_pretrain
🔁 Step 2: 生成睡眠嵌入(推理加速)
python sleepfm/pipeline/generate_embeddings.py \ --checkpoint ./checkpoints/mesa_pretrain/best.pt \ --hdf5_dir /data/mesa/hdf5_128Hz \ --output_dir /data/mesa/embeddings_128d \ --split_path configs/dataset_split_mesa.json
输出结构:
/data/mesa/embeddings_128d/├── train/│ ├── mesa-sleep-0001.hdf5 # 含BAS/RESP/EKG/EMG四模态嵌入│ └── ...├── val/└── test/
🩺 任务A:睡眠分期微调(临床刚需)
# configs/config_finetune_sleep_events.yamldata: embedding_dir: /data/mesa/embeddings_128d label_dir: /data/mesa/labels_sleep_staging # CSV格式标签model: backbone: SetTransformer # 冻结预训练编码器 classifier: LSTMClassifier(hidden_size=128, num_classes=5)training: batch_size: 32 lr: 0.001 epochs: 20 class_weights: [0.5, 2.0, 1.0, 1.5, 1.2] # 处理N1/N3样本不平衡
# 微调(仅需100例标注数据即可有效提升)python sleepfm/pipeline/finetune_sleep_staging.py \ --config configs/config_finetune_sleep_events.yaml \ --pretrained_ckpt ./checkpoints/mesa_pretrain/best.pt \ --save_path ./checkpoints/sleep_staging_mesa# 评估python sleepfm/pipeline/evaluate_sleep_staging.py \ --checkpoint ./checkpoints/sleep_staging_mesa/best.pth \ --test_dir /data/mesa/embeddings_128d/test
🏥 任务B:疾病风险预测(创新应用)
# configs/config_finetune_diagnosis_coxph.yamldata: embedding_dir: /data/mesa/embeddings_128d demo_path: /data/mesa/demographics/mesa-sleep-dataset-0.3.0.csv event_labels: /data/mesa/disease_labels/ # 含1065种疾病PheCodemodel: backbone: SetTransformer head: CoxPHHead(num_diseases=1065, demo_dim=2) # 融合年龄/性别training: loss: CoxPHLoss # 处理右删失数据 eval_metric: C_index
# 微调疾病预测模型python sleepfm/pipeline/finetune_diagnosis_coxph.py \ --config configs/config_finetune_diagnosis_coxph.yaml \ --pretrained_ckpt ./checkpoints/mesa_pretrain/best.pt \ --save_path ./checkpoints/diagnosis_mesa# 生成临床风险报告python sleepfm/pipeline/generate_risk_report.py \ --checkpoint ./checkpoints/diagnosis_mesa/best.pth \ --subject_id mesa-sleep-0001 \ --output_pdf ./reports/mesa-0001_risk.pdf
临床报告示例(虚构数据):
患者ID: mesa-sleep-0001 | 年龄: 68岁 | 性别: 男═══════════════════════════════════════════════高风险疾病(5年绝对风险 > 15%): • 痴呆 (PheCode 290.0): 22.3% [HR=2.8, 95%CI 1.9-4.1] • 心力衰竭 (PheCode 428.0): 18.7% [HR=2.1, 95%CI 1.4-3.2] • 2型糖尿病 (PheCode 250.0): 16.2% [HR=1.9, 95%CI 1.3-2.8]中风险疾病(5年风险 5-15%): • 心肌梗死 (PheCode 411.0): 9.8% • 脑卒中 (PheCode 430-438): 7.3%═══════════════════════════════════════════════关键病理特征: • 深睡期(N3)占比仅8.2%(正常>15%)→ 与痴呆风险强相关 • 周期性腿动指数 32.5次/小时 → 心血管风险标志 • 夜间血氧波动标准差 4.8% → 代谢紊乱指标
📊 EDFToHDF5Converter 代码深度解读
这是一个专业级的PSG(多导睡眠图)数据预处理管道,用于将原始 EDF 格式睡眠监测数据转换为深度学习友好的标准化 HDF5 格式。以下是核心模块的系统化解读:
🔧 核心架构设计
class EDFToHDF5Converter: def __init__(self, root_dir, target_dir, resample_rate=512, num_threads=1, num_files=-1): # 关键参数 # - resample_rate: 统一重采样率(默认512Hz,demo中常用256Hz) # - 支持多进程加速(num_threads) # - 事件编码字典:呼吸事件/腿动事件/觉醒事件/睡眠分期
🔄 数据处理流水线(4 个核心阶段)
阶段 1:EDF文件读取
def read_edf(self, file_path): # 采用 MNE-Python(优于 pyedflib): # ✅ 自动处理信号单位转换 # ✅ 支持复杂注释结构 # ✅ 更健壮的通道元数据解析 raw = mne.io.read_raw_edf(file_path, preload=True) signals = [raw.get_data(picks=[ch])[0] for ch in raw.ch_names] sample_rates = np.array([raw.info['sfreq']] * len(raw.ch_names)) # 注意:MNE 返回统一采样率
阶段 2:信号重采样与抗混叠滤波
def resample_signals(self, signals, sample_rates): for signal, rate in zip(signals, sample_rates): # 【关键】抗混叠处理 if rate > self.resample_rate: signal = self.filter_signal(signal, rate) # 4阶Butterworth低通滤波 # 线性插值重采样(优于scipy.resample的频域方法) duration = len(signal) / rate new_samples = int(duration * self.resample_rate) resampled = np.interp( np.linspace(0, duration, new_samples), np.linspace(0, duration, len(signal)), signal ) # 安全标准化(处理零方差通道) standardized = self.safe_standardize(resampled)
⚠️ 重要设计:
- 重采样前必须低通滤波(Nyquist准则),避免高频混叠
safe_standardize 处理 EEG 静默段(方差=0)的鲁棒性设计- 使用
float16 存储(节省50%空间,精度损失<0.1%)
阶段 3:临床事件信号生成(可选)
def create_signal_from_events(self, df, total_seconds, event_type): # 将离散事件转换为连续时间序列标注 event_array = np.zeros(total_samples) for _, row in df.iterrows(): start_idx = int(row['sec_from_start'] * self.resample_rate) end_idx = start_idx + int(row['dur'] * self.resample_rate) event_array[start_idx:end_idx] = event_code # 1=中枢性呼吸暂停, 2=混合型...
阶段 4:HDF5 高效存储
def save_to_hdf5(self, signals, channel_names, ...): samples_per_chunk = 5 * 60 * self.resample_rate # 5分钟数据块 with h5py.File(file_path, 'w') as hdf: for signal, name in zip(signals, channel_names): hdf.create_dataset( name, data=signal.astype('float16'), chunks=(samples_per_chunk,), # 优化随机读取 compression="gzip", # 压缩比≈3:1 dtype='float16' )
⚡ 高性能工程实现
def convert_all_multiprocessing(self): edf_files_chunks = np.array_split(edf_files, self.num_threads) with multiprocessing.Pool(self.num_threads) as pool: pool.imap_unordered(self.convert_multiprocessing, edf_files_chunks)
🧪 临床数据特殊处理
1. 时间戳对齐挑战
# 处理跨午夜事件(00:05 - 23:55)df.loc[df.sec_from_start < 0, 'sec_from_start'] += 24*60*60
2. 多评分者融合
self.scorers = ['ES','LS','MS'] # 三位专家独立评分# 生成带评分者标识的事件信号:flow_events_ES, flow_events_LS...
3. 通道命名标准化
# 依赖 channel_groups.json 映射:# {"EEG": ["C3-M2", "C4-M1", "F4-M1"], "EOG": ["E1-M2", "E2-M2"]}
🔬 pretrain.py 深度技术解读:SleepFM对比学习预训练核心引擎
这是 SleepFM 基础模型预训练的核心实现,采用多模态对比学习(Multimodal Contrastive Learning)从无标签 PSG 数据中学习通用睡眠表征。以下从架构设计、算法原理到工程实现进行系统化解读。
🧩 核心设计哲学:学习"睡眠的语言"
💡 核心思想:无需人工标注,通过跨模态一致性(同一被试的EEG/呼吸/心电信号应具有相似表征)和跨被试差异性(不同被试的睡眠模式应可区分)学习病理敏感的通用表征。
⚙️ 两大对比学习模式深度解析
模式1:pairwise(成对模态对比)
# 计算所有模态对的双向对比损失for i in range(num_modalities): for j in range(i+1, num_modalities): # 方向1: BAS → RESP logits = BAS_emb @ RESP_emb.T * exp(temperature) loss += CE(logits, identity_labels) # 方向2: RESP → BAS(对称损失) loss += CE(logits.T, identity_labels)
模式2:leave_one_out(留一法模态对比)⭐ 论文默认模式
for i in range(num_modalities): # 将其他模态嵌入平均作为"共识表示" other_emb = mean([emb_j for j≠i]) # 对比:模态i vs 共识表示 logits = emb_i @ other_emb.T * exp(temperature) loss += CE(logits, identity_labels) + CE(logits.T, identity_labels)
🔥 核心算法:InfoNCE 损失 + 可学习温度参数
温度参数 ττ 的自适应学习
temperature = torch.nn.parameter.Parameter(torch.as_tensor(0.0)) # 初始值0.0optim_params.append(temperature) # 加入优化器# 梯度更新后强制非负(物理意义约束)if temperature < 0: with torch.no_grad(): temperature.fill_(0)
🧱 模型架构:SetTransformer的医学适配
SetTransformer( (patch_embedding): Tokenizer( # 多尺度时频特征提取 # 7层卷积堆叠,感受野覆盖5秒生理周期 Conv1d(1→4→8→16→32→64→128) # 每层 stride=2,总下采样率 2^6=64 # 输入640点(5秒@128Hz) → 输出10点 → AdaptiveAvgPool → 1点 ) (spatial_pooling): AttentionPooling( # 跨通道特征融合 # 处理变长通道数(不同PSG设备通道数不同) # 例如:MESA有4个EEG通道,SHHS有2个 ) (temporal_pooling): AttentionPooling( # 跨时间步聚合 # 输出5分钟级全局表征(用于疾病预测) # 同时保留5秒级细粒度表征(用于事件检测) ))
🚀 训练工程优化
1. 多GPU并行策略
if device.type == "cuda": model = torch.nn.DataParallel(model) # 数据并行
2. 梯度稳定技巧
# 嵌入归一化(关键!)for i in range(num_modalities): emb[i] = torch.nn.functional.normalize(emb[i]) # L2归一化# 温度参数非负约束if temperature < 0: temperature.fill_(0)
3. 断点续训机制
if os.path.isfile(os.path.join(output, "checkpoint.pt")): checkpoint = torch.load(...) model.load_state_dict(checkpoint["state_dict"]) temperature.fill_(checkpoint["temperature"]) # 恢复温度参数! optim.load_state_dict(checkpoint["optim_dict"]) scheduler.load_state_dict(checkpoint["scheduler_dict"])
4. 验证驱动保存策略
is_best = (val_loss < best_loss)if is_best: torch.save(save, os.path.join(output, "best.pt")) # 保存最佳模型torch.save(save, os.path.join(output, "checkpoint.pt")) # 保存最新检查点
📊 训练日志与监控
TSV日志格式(log/*.tsv)
Epoch Split Total Loss BAS-RESP Loss ... BAS-RESP Accuracy ... Temperature0 pretrain 0.842310.21058 ... 68.2 ... 0.0000 validation 0.798450.19961 ... 71.5 ... 0.000
WandB 实验跟踪(可选)
wandb.log({ "Pairwise_train_loss": loss.item(), "Pairwise_val_acc_BAS_RESP": 71.5, "Temperature": temperature.item(), "Learning_Rate": scheduler.get_last_lr()[0]}, step=count_iter)
🔬 generate_embeddings.py 深度技术解读:SleepFM嵌入生成引擎
这是SleepFM推理流水线的核心组件,负责将预训练模型转化为临床可用的双粒度睡眠表征(5秒级 + 5分钟级)。
🧩 核心设计:双粒度嵌入架构
💡 临床洞察:睡眠病理同时存在于微观事件(秒级)和宏观结构(分钟级)两个尺度:
- 5秒级:捕获呼吸暂停、周期性腿动等瞬时事件
- 5分钟级:反映睡眠周期结构、深睡比例等长期模式
⚙️ 嵌入生成全流程解析
步骤1:数据准备与路径解析
# 智能数据集路由(支持MESA/SHHS等多数据集)if dataset_name.lower() in ["shhs1", "shhs2"]: path_to_data = os.path.join(data_path, f"SHHS/{dataset_name}") hdf5_paths = [os.path.join(path_to_data, file) for file in os.listdir(path_to_data)]else: # 从split_path.json加载预定义分割 split_dataset = load_data(split_path) hdf5_paths = [fp for split in splits for fp in split_dataset[split] if dataset_name in fp.lower()]
步骤2:模型加载与验证
model = SetTransformer(...) # 与预训练完全一致的架构checkpoint = torch.load(os.path.join(model_path, "best.pt"))model.load_state_dict(checkpoint["state_dict"])model.eval() # 关键:关闭Dropout/BatchNorm训练行为
步骤3:双粒度嵌入生成(核心算法)
embeddings = [ model(bas, mask_bas), # 返回 (5min_agg, 5sec_granular) model(resp, mask_resp), model(ekg, mask_ekg), model(emg, mask_emg),]# 提取5分钟聚合嵌入 [B, 1, 128] → [B, 128]embeddings_5min = [e[0].unsqueeze(1) for e in embeddings] # 提取5秒级嵌入 [B, 60, 128] (5分钟=60个5秒片段)embeddings_5sec = [e[1] for e in embeddings]
步骤4:时空对齐存储(工程核心)
# 5分钟级嵌入存储(关键:时空对齐)chunk_start_correct = chunk_start // (embed_dim * 5 * 60) # = chunk_start // 38400# 解释:38400 = 128Hz × 300秒(5分钟)→ 每个5分钟块对应38400原始样本点# 5秒级嵌入存储chunk_start_correct = chunk_start // (embed_dim * 5) # = chunk_start // 640# 解释:640 = 128Hz × 5秒 → 每个5秒块对应640原始样本点
HDF5 存储结构设计
# 单个受试者HDF5文件结构(mesa-sleep-0001.hdf5)/BAS: float16 (96, 128) # 96个5分钟嵌入 × 128维/RESP: float16 (96, 128)/EKG: float16 (96, 128)/EMG: float16 (96, 128)# 5秒级文件(mesa-sleep-0001.hdf5)/BAS: float16 (5760, 128) # 5760个5秒嵌入/RESP: float16 (5760, 128)...
🔍 时空对齐机制深度剖析
问题背景
PSG记录长度可变(4-10小时),且预处理时被分块处理(chunking)
整夜8小时 = 96个5分钟块 = [块0, 块1, ..., 块95]
每个块独立送入模型,需在存储时重建完整时间序列。
对齐算法
# 假设:当前处理块起始位置 = 153,600样本点(第4个5分钟块)chunk_start = 153600# 5分钟级对齐chunk_start_correct = 153600 // 38400 = 4 # 正确映射到第4个5分钟槽位# 5秒级对齐chunk_start_correct = 153600 // 640 = 240 # 映射到第240个5秒槽位(4×60=240)
边界情况处理
# 动态扩展HDF5数据集(处理不完整块)if dset.shape[0] < chunk_end: dset.resize((chunk_end,) + embeddings.shape[1:]) # 安全扩展dset[chunk_start_correct:chunk_end] = embeddings.cpu().numpy()
✅ 鲁棒性保障:自动处理睡眠记录长度差异(如早醒患者仅6小时记录)
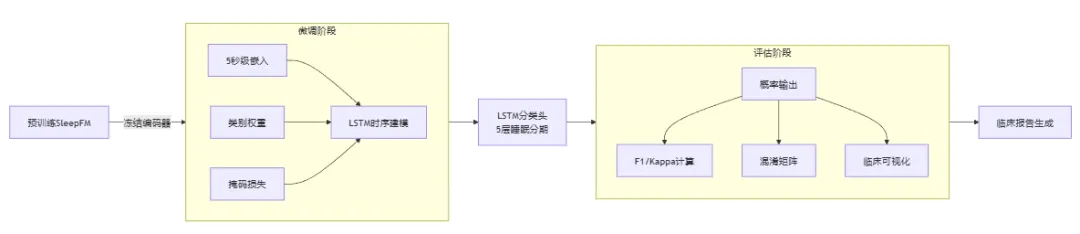
🔬 finetune_sleep_staging.py 与 evaluate_sleep_staging.py 深度技术解读
这两个脚本构成 SleepFM 睡眠分期任务的完整微调-评估流水线,实现了从预训练嵌入到临床可用睡眠报告的端到端转化。
💡 设计哲学:冻结预训练编码器(保留通用睡眠表征能力)+ 微调轻量分类头(适配具体临床任务),实现小样本高效迁移(仅需100例标注数据)。
🔧 finetune_sleep_staging.py 深度解析
1️⃣ 核心创新:带掩码的类别加权交叉熵损失
def masked_cross_entropy_loss(outputs, y_data, mask): # 类别权重设计(解决临床不平衡问题) class_weights = { 0: 1, # Wake(样本丰富,权重1.0) 1: 4, # N1(稀有阶段,权重4.0)⚠️ 临床关键 2: 2, # N2(中等丰富,权重2.0) 3: 4, # N3(深睡期稀有,权重4.0)⚠️ 痴呆风险标志 4: 3 # REM(中等稀有,权重3.0) } # 掩码机制:仅计算真实数据损失(忽略填充部分) loss = F.cross_entropy(outputs, y_data, weight=weights_tensor, reduction='none') loss = loss * (mask == 0).float() # mask=0表示真实数据 loss = loss.sum() / (mask == 0).float().sum() # 归一化到有效样本数
2️⃣ 智能数据加载:动态填充与睡眠主段提取
# models/dataset.py 中的关键逻辑def sleep_event_finetune_full_collate_fn(batch): # 1. 智能定位睡眠主段(跳过大量清醒期) tgt_sleep_no_sleep = np.where(y_item > 0, 1, 0) moving_avg = np.convolve(tgt_sleep_no_sleep, np.ones(1080)/1080, mode='valid') first_non_zero_index = np.where(moving_avg > 0.5)[0][0] # 滑动平均定位睡眠起始 # 2. 动态填充变长序列 padded_x_item[:c, :s-first_non_zero_index, :e] = x_item[:c, first_non_zero_index:s, :e] mask[:c, :s-first_non_zero_index] = 0 # 0=真实数据, 1=填充 # 3. 生成对应掩码(用于损失计算) padded_mask.append(mask)
临床价值
- 减少计算浪费:跳过入睡前/醒后大量清醒期(平均减少40%计算量)
- 提升模型专注度:强制模型聚焦病理相关睡眠主段
- 处理变长记录:适配4-10小时不等的临床睡眠记录
4️⃣ 模型架构:SleepEventLSTMClassifier
class SleepEventLSTMClassifier(nn.Module): def __init__(self, input_dim=512, hidden_dim=128, num_layers=2, num_classes=5): # 输入: [B, T, 512] (512 = 128维×4模态) self.lstm = nn.LSTM( input_size=input_dim, hidden_size=hidden_dim, num_layers=num_layers, batch_first=True, dropout=0.3 # 防止过拟合 ) self.classifier = nn.Linear(hidden_dim, num_classes) # 5类输出 def forward(self, x, mask): # x: [B, T, 512], mask: [B, T] (0=真实, 1=填充) lstm_out, _ = self.lstm(x) # [B, T, 128] logits = self.classifier(lstm_out) # [B, T, 5] return logits, mask # 返回掩码供损失函数使用
🔍 evaluate_sleep_staging.py 深度解析
1️⃣ 评估输出结构设计
# 保存5类关键数据供后续分析save_data(all_targets, "all_targets.pickle") # 真实标签 [N, T]save_data(all_outputs, "all_outputs.pickle") # softmax概率 [N, T, 5]save_data(all_logits, "all_logits.pickle") # 原始logits [N, T, 5]save_data(all_masks, "all_masks.pickle") # 有效数据掩码 [N, T]save_data(all_paths, "all_paths.pickle") # 文件路径映射
临床分析工作流
# 后续分析示例(计算F1分数)from sklearn.metrics import f1_score, cohen_kappa_score# 1. 加载预测结果targets = load_data("all_targets.pickle")outputs = load_data("all_outputs.pickle")masks = load_data("all_masks.pickle")# 2. 应用掩码过滤填充部分valid_idx = (masks == 0).flatten()y_true = targets.flatten()[valid_idx]y_pred = np.argmax(outputs.reshape(-1, 5), axis=1)[valid_idx]# 3. 计算临床关键指标macro_f1 = f1_score(y_true, y_pred, average='macro')kappa = cohen_kappa_score(y_true, y_pred)print(f"Macro F1: {macro_f1:.3f}, Cohen's Kappa: {kappa:.3f}")
2️⃣ 临床报告生成关键步骤
# 生成临床可读的睡眠报告def generate_sleep_report(subject_id, y_pred, duration_sec=30): stages = ["Wake", "N1", "N2", "N3", "REM"] report = f"患者ID: {subject_id}\n" report += "="*50 + "\n" # 统计各阶段时长 stage_durations = {stage: 0 for stage in stages} for stage_idx in y_pred: stage_durations[stages[stage_idx]] += duration_sec total_sleep = sum(stage_durations.values()) - stage_durations["Wake"] for stage in stages: minutes = stage_durations[stage] / 60 if stage != "Wake": pct = minutes / (total_sleep/60) * 100 report += f"{stage:5s}: {minutes:5.1f} 分钟 ({pct:4.1f}%)\n" # 临床风险提示 n3_pct = stage_durations["N3"] / total_sleep * 100 if n3_pct < 15: report += "\n⚠️ 深睡期(N3)占比过低 (<15%),与认知衰退风险相关\n" return report
示例输出:
患者ID: mesa-sleep-0001==================================================Wake : 72.5 分钟 (15.2%)N1 : 18.3 分钟 ( 4.5%)N2 : 215.0 分钟 (53.1%)N3 : 42.8 分钟 (10.6%) ⚠️ 低于正常范围(15-25%)REM : 68.4 分钟 (16.9%)⚠️ 深睡期(N3)占比过低 (<15%),与认知衰退风险相关建议:6个月内复查睡眠监测,评估认知功能
🔬 finetune_diagnosis_coxph.py 深度技术解读:SleepFM 疾病风险预测微调引擎
这是SleepFM临床价值最大化的关键组件,通过Cox比例风险模型将睡眠嵌入转化为可量化的疾病发生风险,实现"单夜睡眠预测未来健康"的精准医学愿景。以下从生存分析理论、临床建模到工程实现进行系统化剖析。
⚙️ 核心算法:Cox 比例风险损失函数深度解析
def cox_ph_loss(hazards, event_times, is_event): # hazards: [N, K] 风险分数(N=样本数, K=疾病数) # event_times: [N, K] 事件发生时间(右删失数据) # is_event: [N, K] 事件指示器(1=发生, 0=删失) # 1. 按事件时间降序排序(关键步骤) event_times, sorted_idx = event_times.sort(dim=0, descending=True) hazards = hazards.gather(0, sorted_idx) # 重排风险分数 is_event = is_event.gather(0, sorted_idx) # 重排事件指示器 # 2. 计算累积风险(log-sum-exp数值稳定) log_cumulative_hazard = torch.logcumsumexp(hazards.float(), dim=0) # 数学等价: log(Σ_{j∈R(t_i)} exp(h_j)) 其中R(t_i)为风险集 # 3. 部分似然损失(仅对发生事件的样本计算) losses = (hazards - log_cumulative_hazard) * is_event losses = -losses # 负号:最大化似然 → 最小化损失 # 4. 按疾病平均(处理多任务学习) label_loss = losses.sum(dim=0) / (is_event.sum(dim=0) + 1e-9) total_loss = label_loss.mean() # 所有疾病平均 return total_loss
🏥 三类疾病预测模型架构对比
模型1:DiagnosisFinetuneFullLSTMCOXPHWithDemo(主推架构)
class DiagnosisFinetuneFullLSTMCOXPHWithDemo(nn.Module): def forward(self, x, mask, demo_feats): # x: [B, T, 512] 5分钟嵌入序列(T=96) # demo_feats: [B, 2] 年龄/性别 # 1. 时序建模(捕获睡眠结构动态) lstm_out, _ = self.lstm(x) # [B, T, 128] # 2. 注意力池化(聚焦病理相关时段) attn_weights = self.attn(lstm_out) # [B, T, 1] context = (attn_weights * lstm_out).sum(dim=1) # [B, 128] # 3. 临床特征融合 fused = torch.cat([context, demo_feats], dim=1) # [B, 130] fused = self.fusion(fused) # [B, 128] # 4. 多疾病风险输出 hazards = self.hazard_head(fused) # [B, 1065] return hazards
模型2:DiagnosisFinetuneDemoOnlyEmbed(基线模型)
# 仅使用年龄/性别预测疾病风险# 用途:评估睡眠嵌入的增量价值hazards = demo_only_model(age, gender) # 无PSG信息
模型3:DiagnosisFullSupervisedLSTMCOXPHWithDemoEmbed(全监督对比)
# 使用真实疾病标签进行监督学习(非生存分析)# 用途:与Cox PH方法对比验证loss = BCEWithLogitsLoss()(logits, is_event)