在软件研发界有一句名言:“如果你想走得快,一个人走;如果你想走得远,一群人走。”
在车企研发体系中,代码评审(Code Review, CR)常被误解为一种“繁文缛节”,甚至被管理层视为对开发时间的额外挥霍。但事实上,CR 是内建质量(Built-in Quality)中性价比最高的环节。它不是在“找茬”,而是在代码进入集成环境前,筑起的一道防线。
如果每个模块不管是新建还是维护都走全量评审,研发效率又会受到损伤。 每行代码都经历同样的审查流程不太现实,最好采取“因地制宜、按需分级”的策略。
一、 四种审查工具
代码评审不是单一的行为,而是一套组合拳。我们需要根据场景,从工具箱里选择最合适的工具:
1. 静态代码工具自查:数字化的“第一道安检”
适用场景: 所有的代码提交(Commit)。
侧重点: 语法规范、安全漏洞、内存泄漏、圈复杂度。
逻辑: 借助静态代码分析工具(如 SonarQube, Coverity),在代码离开开发机之前,由机器完成 80% 的体力劳动。如果代码连 MISRA C/C++ 规范都过不去,根本不配占用同事的评审时间。
2. 交叉评审(Peer Review):团队的“逻辑校对”
适用场景: 普通功能开发、常规需求迭代。
侧重点: 业务逻辑、可读性、异常处理。
逻辑: 由同组或临近模块的开发者通过 GitLab/Gerrit 进行异步评审。这不仅是查错,更是“知识广播”——确保团队内至少有两个人懂这块代码,降低“单点故障”风险。
3. 会议评审(Meeting Review):针对“重大工程”的会诊
适用场景: 涉及核心协议修改、跨模块接口调整、重大架构变动。
侧重点: 系统性影响、全局耦合度、接口兼容性。
逻辑: 召集相关方坐在会议室里(或线上会议),逐行讲解核心逻辑。这种方式成本最高,但对于预防灾难性的系统崩溃最为有效。
4. 专家评审(Expert Review):顶层设计的“安全阀”
适用场景:核心驱动开发、性能敏感模块、高等级安全(Functional Safety)代码。
侧重点:架构契合度、极致性能、安全鲁棒性。
逻辑:由架构师或领域专家进行深度审计。专家不关注分号写在哪,他们关注的是:这个设计是否会在极端工况下导致系统死锁?
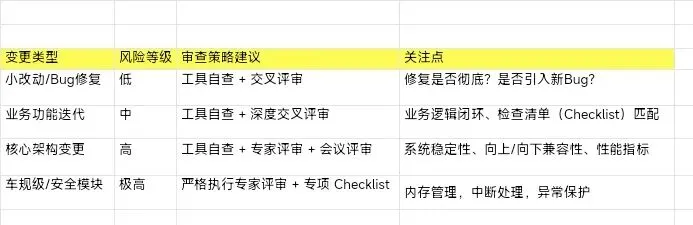
二、 因地制宜,拒绝“一刀切”
为了平衡质量与效率,我们需要建立一套“阶梯式审查模型”:
三、 Checklist(检查清单)
没有Checklist的CR只是在“聊天”。每一类评审都应该有对应的指引,确保审查者不会因为心情或疲劳度而漏掉关键点。
一个典型的座舱软件 CR 检查清单应包含:
资源管理: 是否存在内存泄漏?互斥锁是否成对出现?
边界检查: 数组索引是否越界?指针是否进行了非空校验?
异常逻辑: 所有的错误分支(Error Case)是否都有对应的处理和日志?
性能损耗: 是否在循环中进行了不必要的耗时操作或大对象拷贝?
示例如下:
四、 如何度量 CR 的成效?
对于那些“不放心”的管理者,我们要用数据证明 CR 的价值:
CR 缺陷拦截率: 在测试阶段发现的问题,有多少是本该在 CR 阶段拦截的?(反推评审质量)。
评审密度(Defects per kLoC): 平均每千行代码通过 CR 发现的问题数。过低可能意味着评审走形式,过高意味着代码初始质量差。
评审时延: 提交评审到合入的平均时间。如果这个时间太长,说明流程阻塞了开发效率,需要优化。
结语
在车企研发的丛林中,代码评审不是为了限制开发者的自由,而是为了给专业的人提供一份“安全保障”。
优秀的 CR 文化不应该是“批斗会”,而是一次次“技术围观”下的共同成长。它让那些“外行人”明白:软件的质量不是靠在测试场跑几万公里“撞”出来的,而是在一行行代码、一次次审查中“磨”出来的。
好的代码是写给机器跑的,但优秀的架构是写给人看的。 如果你的代码连朝夕相处的同事都看不懂、不放心,凭什么让用户在驾驶时把生命托付给它?
本文首发于公众号《软件研发质量与效率》,用专业的研发治理,驱动极致的交付价值。
相关链接:
研发体系度量指标设计原则