https://github.com/Open-X-Humanoid/TienKung-Lab是北京人形机器人创新中心开源的“天工”人形机器人代码仓库,天工机器人ultra版本在2025北京亦庄半程马拉松获得了冠军,本仓库中使用的是lite版本。
 lite
lite ultra
ultra项目运行
在legged_lab/assets/tienkung2_lite/usd下可以找到 usd 文件在 isaac-sim 中看它的结构。
 usd
usd在安装好 isaacsim 和 isaaclab 的前提下,执行下面命令安装 TienKung-Lab 代码。
cd TienKung-Labpip install -e .cd TienKung-Lab/rsl_rlpip install -e .
训练命令python legged_lab/scripts/train.py --task=walk --logger=tensorboard --num_envs=512 --headless。4090 单卡,50000次迭代,需要执行 10 个小时。
在TienKung-Lab代码所在路径/logs/任务名称(比如walk)/年月日_时分秒路径下可以看到保存的模型
 image
image推理命令python legged_lab/scripts/play.py --task=walk --load_run=2026-02-02_14-52-13 --checkpoint=model_10000.pt --num_envs=4。可以在 isaac-sim 中查看训练的效果。
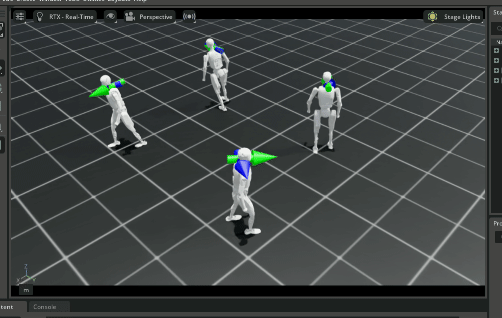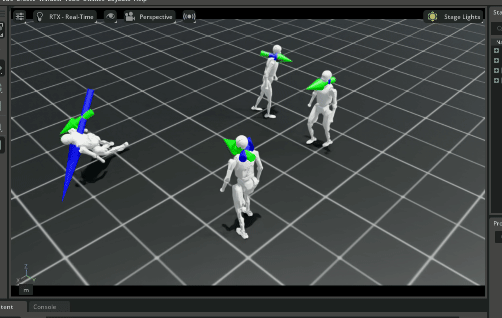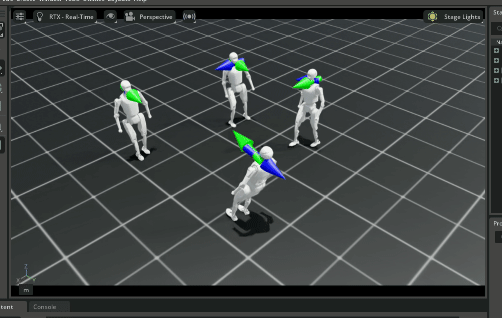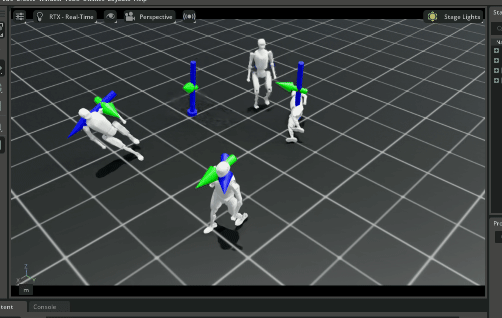
下面三个 gif 分别是模型训练 1000,10000和49900轮的效果。
49900轮看起来和10000轮差别不大。
下面开始解读项目代码。首先关注机器人环境配置,启动脚本 train.py 和策略runner。(如果第一次了解 Isaac 系列可以了解一下)IsaacLab 的项目都遵循相同的规范:仿真环境用 task_registry.register 注册;train.py 负责获取配置启动训练,代码在不同的任务中区别不大;train.py 中调用 runner_class,这里实现针对具体任务的算法。
任务启动脚本
--task 参数需要从注册的名称中选
# legged_lab/envs/__init__.pytask_registry.register("walk", TienKungEnv, TienKungWalkFlatEnvCfg(), TienKungWalkAgentCfg())sk_registry.register("run", TienKungEnv, TienKungRunFlatEnvCfg(), TienKungRunAgentCfg())task_registry.register("walk_with_sensor", TienKungEnv, TienKungWalkWithSensorFlatEnvCfg(), TienKungWalkWithSensorAgentCfg())task_registry.register("run_with_sensor", TienKungEnv, TienKungRunWithSensorFlatEnvCfg(), TienKungRunWithSensorAgentCfg()
省去一大堆获取配置项和打日志的代码,核心就是初始化runner类和执行
# legged_lab/scripts/train.pyrunner_class: OnPolicyRunner | AmpOnPolicyRunner = eval(agent_cfg.runner_class_name)runner = runner_class(env, agent_cfg.to_dict(), log_dir=log_dir, device=agent_cfg.device)runner.learn(num_learning_iterations=agent_cfg.max_iterations, init_at_random_ep_len=True)
learn 方法
下面来看rsl_rl/rsl_rl/runners/amp_on_policy_runner.py中learn()的具体实现。
训练前准备
首先随机初始化 episode 长度,目的是让不同的环境处于不同的 episode 阶段,防止机器人每次从头开始学,前面学的好,后面渣渣。这种技术在学术界通常被称为 RSI (Reference State Initialization),由著名的 DeepMimic 论文提出。
if init_at_random_ep_len: self.env.episode_length_buf = torch.randint_like( self.env.episode_length_buf, high=int(self.env.max_episode_length) )
接下来初始化了三个观测状态
- obs (普通观测): 机器人能够获取到的关节角度,躯干姿态等。用于 Policy(策略网络) 决定下一步该做什么。
- privileged_obs (特权观测):作为上帝视角,机器人运行中获取不到的数据,比如地面摩擦力等。训练过程中只对 Critic 网络可见,用于评估。
- amp_obs(Adversarial Motion Prior对抗运动先验):获取运动姿态的数据,用于和人类数据作对比。
obs, extras = self.env.get_observations() privileged_obs = extras["observations"].get(self.privileged_obs_type, obs) amp_obs = self.env.get_amp_obs_for_expert_trans() obs, privileged_obs, amp_obs = obs.to(self.device), privileged_obs.to(self.device), amp_obs.to(self.device) self.train_mode() # switch to train mode (for dropout for example)
具体的状态可以在 legged_lab/envs/base/base_env.py 中找到
| | | |
|---|
| 角速度 | | | |
| 重力投影 | | | |
| 速度命令 | | | |
| 关节位置 | | | |
| 关节速度 | | | |
| 上一动作 | | | |
| 根节点线速度 | | | |
| 足端接触力 | | | |
| 手部末端位置 | | | |
| 脚部末端位置 | | | |
| 高度扫描 | | | |
AMP观测详细组成 (48维)
Book keeping 这几个变量用于记录 reward 和 episode 长度。
ep_infos = []rewbuffer = deque(maxlen=100)lenbuffer = deque(maxlen=100)cur_reward_sum = torch.zeros(self.env.num_envs, dtype=torch.float, device=self.device)cur_episode_length = torch.zeros(self.env.num_envs, dtype=torch.float, device=self.device)
训练流程
下面开始正式训练的流程了,看看模型迭代一次做了什么。
rollout 的部分用 with torch.inference_mode(): 套起来,不参与梯度计算。下面的过程每一次模型迭代都要重复 num_steps_per_env (默认值 24)次。
动作和状态采样。
actions = self.alg.act(obs, privileged_obs, amp_obs)obs, rewards, dones, infos = self.env.step(actions.to(self.env.device))
获取AMP 特征向量,用于判别器判断动作是否像人类
next_amp_obs = self.env.get_amp_obs_for_expert_trans()
因为当环境重置时,next_amp_obs 实际上是新回合的初始状态,而不是上一回合的终止状态。这里需要用上一回合的终止状态 (terminal_amp_states) 替换重置后新回合的初始状态。
next_amp_obs_with_term = torch.clone(next_amp_obs)reset_env_ids = self.env.reset_env_idsterminal_amp_states = self.env.get_amp_obs_for_expert_trans()[reset_env_ids]next_amp_obs_with_term[reset_env_ids] = terminal_amp_states
计算amp reward
rewards = self.alg.discriminator.predict_amp_reward( amp_obs, next_amp_obs_with_term, rewards, normalizer=self.alg.amp_normalizer)[0]
记录 reward 和终止标记。
self.alg.process_env_step(rewards, dones, infos, next_amp_obs_with_term)
至此 num_steps_per_env (默认值 24)次 循环结束。计算整个 episode 的 return。
if self.training_type == "rl": self.alg.compute_returns(privileged_obs)
inference_mode 结束,更新梯度
loss_dict = self.alg.update()
至此已经整体上介绍了训练代码的框架,下一步要深入 rsl_rl/rsl_rl/algorithms/amp_ppo.py 看算法的具体实现。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
