解决python模型服务线上性能问题
1、线上报警
某天中午下游模型调用方紧急找过,说我们的模型服务在线上大量报错,严重阻塞了线上业务:
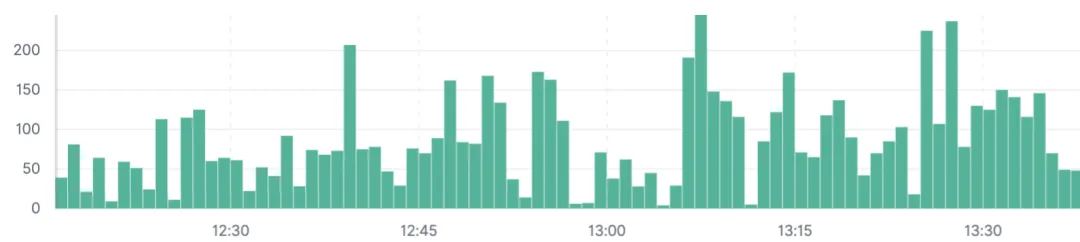
几乎是每分钟都有一百个左右,于是问了一下调用方是不是因为最近起量了,导致我们资源不足,于是检查下了下报错高峰期的调用量:
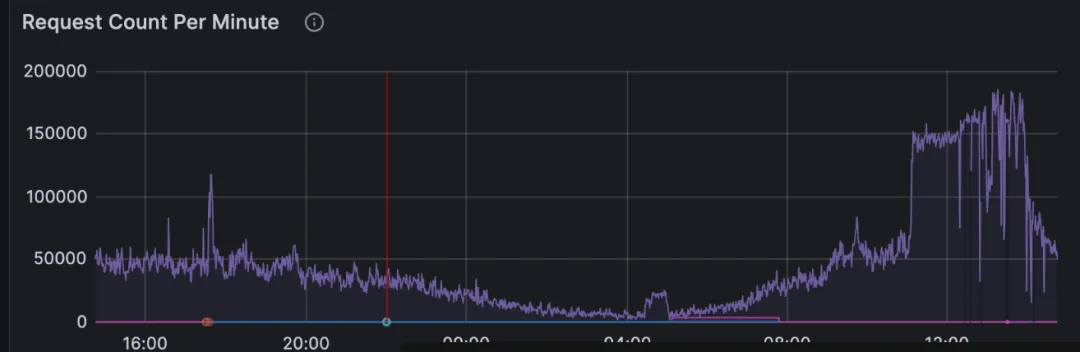
每分钟最多大概有20万调用量,这远远超过了我们服务的承载能力,报错中很多都是read time out超时也就是等待模型服务推理结果的时候超时了,于是我们线上紧急扩容了一波,扩容之后仍然有报错:
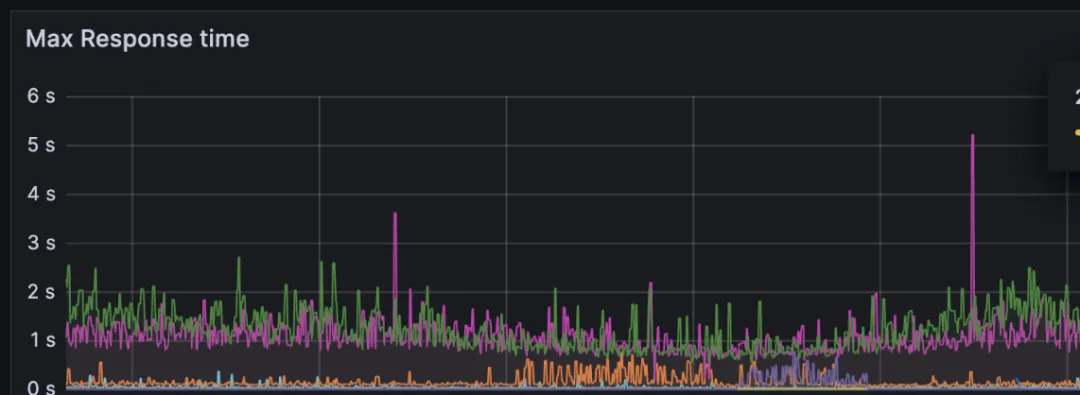
只是报错的量下去了,14点之后业务高峰期过去了就没有报错了,然后我们查了一下这个服务的耗时:
下游方超时时间是2s,接口耗时监控也符合现状也就是说还是有超过2s的突刺最多的有5s的,这就奇怪了,我们这个模型服务有5个模型(这也是一个雷点),然后内部代码没有任何数据库之类的io,都是纯内存计算,模型都是由 PyTorch 导出的 ONNX 模型,使用 ONNX Runtime 进行推理,并且在上线之前对模型推理部分也做过压测,30的并发下单节点tp99才80ms,也就是说性能瓶颈肯定不在模型推理本身。那么问题在哪里呢?
2、开始排查
首先我们需要对完整的模型服务做一个压测,看一下到底服务能承压多少QPS,然后再针对线上的真实QPS做分析,例如线下压测到QPS 50的时候tp99不超过2s,线上最大QPS不超过50,那么就说明服务能力能承载但是因为线上环境和测试环境有差异导致没有承载到这么高的并发
我们服务本身是fastApi+gunicron,然后workers是1,threads是4,也就是说一个工作进程,4个线程,之所以这样配置是因为我们服务是CPU密集的,可以少进程多线程
然后我们把线上的镜像放到了测试环境,用vegeta从10的并发开始,QPS为10然后压测10S(vegeta是非常好用的压测工具,是golang写的,比ab准确和好用太多):
非常夸张!!!
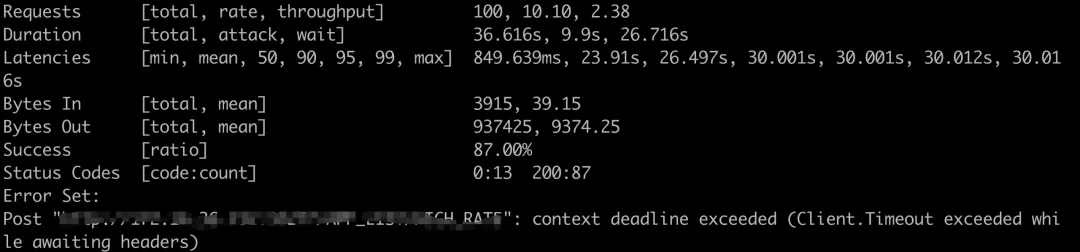
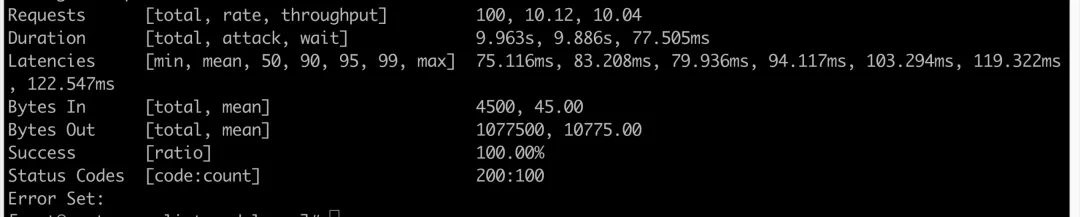
tp99达到了夸张的30S,这和线上的现状符合,我们测试环境是单节点,线上一共12个节点,高峰大概是60的QPS,也就是说我们单节点大概承载5的QPS,我们用5的QPS来再压一下:
tp99是4S,和线上观测到的数据基本上一致!
那么问题就变成了为什么这个接口的性能这么差
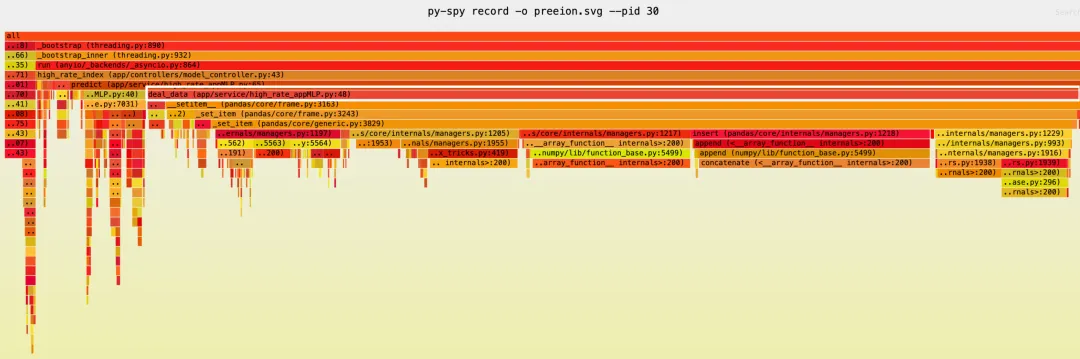
我接下来用py-spy来对服务做性能分析生成火焰图,py-spy类似于java的perf可以attach到运行中的py进程中来生成火焰图,我们attach到进程中之后,然后就开启py-spy来采集数据生成火焰图,py-spy到好处是对代码和环境是完全0侵入的,可以在容器内用pip安装即可,不过要使用py-spy的话必须要容器开启PTRACE能力:
这里很直观的可以看到,我用白色框起来的部分是最长最红的,这表明,这一行代码的耗时是最长的,我们看下这行代码在干什么:
for item in set(effective) - set(user_matrix.columns): df[item] = 0
这种写法会触发逐列赋值,也就是完整复制一次user_matrix,然后根据在不在effective中来给值,要添加 100 列,就会有 100 次这样的操作,总体复杂度接近 O(n × m),其中 n 是行数,m 是缺失列数
我们的effective大概有一百来列,user_matrix就是几十列,不慢才怪!
这里的业务背景是,我们根据用户的入参构建了一个dataframe列表,然后和我们维护的标准列做差集,保证最后给到模型推理的参数有所有的列,如果用户参数里没有这些列就加上这些列并且赋值为0
3、紧急修复
既然找到了问题的根因,那么就很好修复了:
missing = set(self.effective) - set(oot_user_matrix.columns)if missing: new_cols = pd.DataFrame(0, index=oot_user_matrix.index, columns=list(missing)) oot_user_matrix = pd.concat([oot_user_matrix, new_cols], axis=1)# 只保留有效APP列并按照effective的顺序排列 oot_user_matrix = oot_user_matrix[self.effective]
直接获取到差的列,根据差的列生成一个全是0的列表,最后让这个列表和用户的列表做合并即可,这里就不会复制和遍历,只是简单的合并,最后再根据标准列的顺序排序,防止推理出问题,时间复杂度就只有O(n),做合并是O(1),大大减少了耗时
然后我们用相同的10的并发压测10s看下效果:
立竿见影!刚刚优化之前10的并发的tpo99 30S,这里相当于优化了300倍!
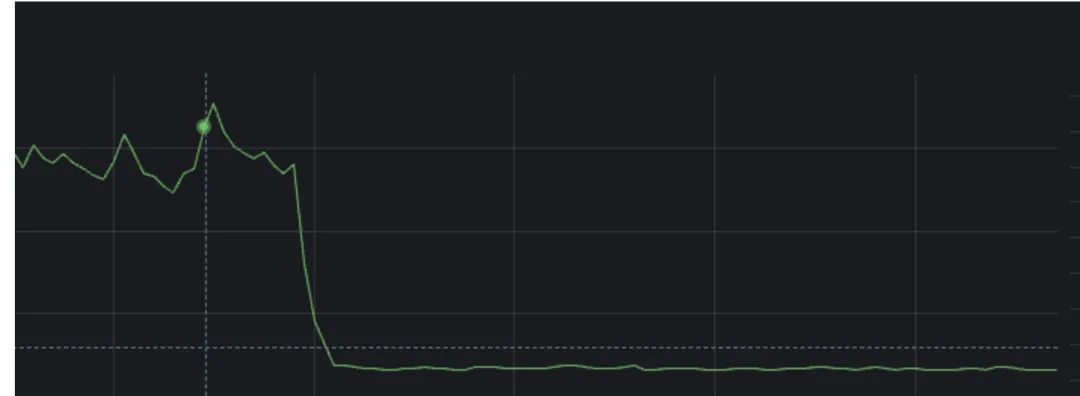
我们发布上线之后,接口的耗时肉眼可见的下降了:
说明优化起作用了!
4、总结
这次优化之后彻底消灭了线上的超时报错,后面再有流量高峰我们用更少的节点也扛住了,不过每天仍然有少量的报错,如果是下游使用的是java的Apache的httpclient报错信息就是:
failed to respond
如果是golang的报错就是:
EOF
经过笔者查阅资料之后发现,是因为我们服务使用的是gunicorn来对外提供http的,gunicorn在请求较多的时候会错误的关闭连接,直接发送FIN给客户端,但是客户端这里这个链接是keep alive的,下一次又使用了这个链接来请求,服务端发现这个链接已经发送过了FIN,所以不返回内容了,客户端就报错了,解决方法就是外面套一层nginx来提供http,然后nginx在转发到gunicorn,这是py的web服务的最佳实践,说到底就是笔者java写多了,以为可以直接在生产中使用框架的http中间件。
经过这次事故,笔者总结到的教训就是:
1、不要多个模型都在一个服务里,这样服务的QPS会线性上升,但是耗费的资源上涨级别又很大,比如我服务里只有一个模型只需要2个节点,如果是两个模型可能就不止4个节点了,而且一个模型要是出问题会连带的影响其他模型,这次报错的其实就两个模型,但是这个服务里的其他模型都受到了影响都在报错,ai模型部署的最佳实践应该是serverless
2、不管怎么自信,上线之前都需要压测,做到应对流量洪峰心里有数