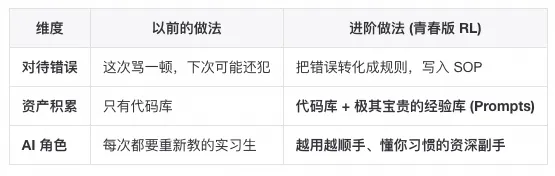
0. 核心目标:从“代码产出者”变成“文档定义者”
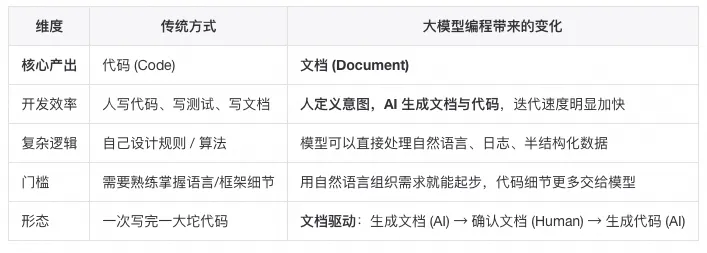
这篇文档不是教你怎么把 Ctrl+C / Ctrl+V 换成“让 AI 写代码”,而是希望帮你完成一次根本性的角色转换:Code is generated, Document is the Source of Truth(代码是生成的,文档才是真理之源)。
你不再是砌砖的工匠,而是画图纸的建筑师。你的核心产出不再是 FunctionImpl,而是 RequirementSpec 和 ArchitectureDesign。
最终目标是:在安全合规前提下,把“写代码”变成一种“自动化生成”过程,人力主要花在:
需求澄清与拆解(把模糊的想法变成清晰的文档);
架构与边界设计(定义 AI 的活动范围);
文档对齐与验收(检查代码是否忠实实现了文档)。
如果我们真的把这些事情做扎实,大概会发生几件很具体的变化:
文档即代码:只要文档改了,代码就能跟着变。修改功能不再是“改代码 -> 改文档”,而是“改文档 -> AI 重写代码”。
模型无关性:只要文档写得够细,用 GPT 还是用Qwen,区别只在于生成的快慢,而不会偏离核心逻辑。
知识资产化:团队沉淀下来的不再是一堆只有原作者能看懂的代码,而是一套套清晰的、可复用的业务逻辑文档。
不管你是程序员、测试还是产品、设计师,今天都应该大用特用大模型写代码和文档——越早把它融进日常工作,越不容易被“会用 AI 的人”替代。年纪大也不一定会被“优化”,只要你会用模型,完全可以带着一堆 AI 再干几十年。
这不是“立刻变成科幻世界”,而是一个可以在几个月内逐步感受到的现实改进。
大模型编程(LLM‑based Programming)的核心变化,是从关注 “怎么做(How)”转向 “需要什么(What)”。
2023 年我还在微软时,GPT 刚刚兴起,大家已经开始尝试用大模型辅助处理一些代码问题。当时微软也在开发基于大模型的 Copilot,但受限于模型能力,功能还比较基础——只能帮忙添加注释、生成简单的单元测试,离真正“会写代码”还有很大差距。
然而短短一年多后,到了 2024 年底,我已经能用 Cursor 完成几乎所有的编码任务。过去一年多,我几乎没有真正“手写”过代码。不仅是我,我认识的很多程序员也是如此:日常工作的重心转向了系统设计、任务拆解和代码 Review,具体的实现则交给 AI 模型。
加入钉钉后,尽管我没有任何 Java 工程经验,依然能快速完成开发需求,产出的代码质量较高,也能很好地与团队现有的代码风格保持一致,全倚仗大模型的帮忙。
所以我非常确信:未来一定是大模型编码的世界,学习大模型编程会像学习使用 IDE 一样,成为一项最基本的工程师技能。
注意:以上场景的效率提升因人而异,关键是找到适合你的使用方式。
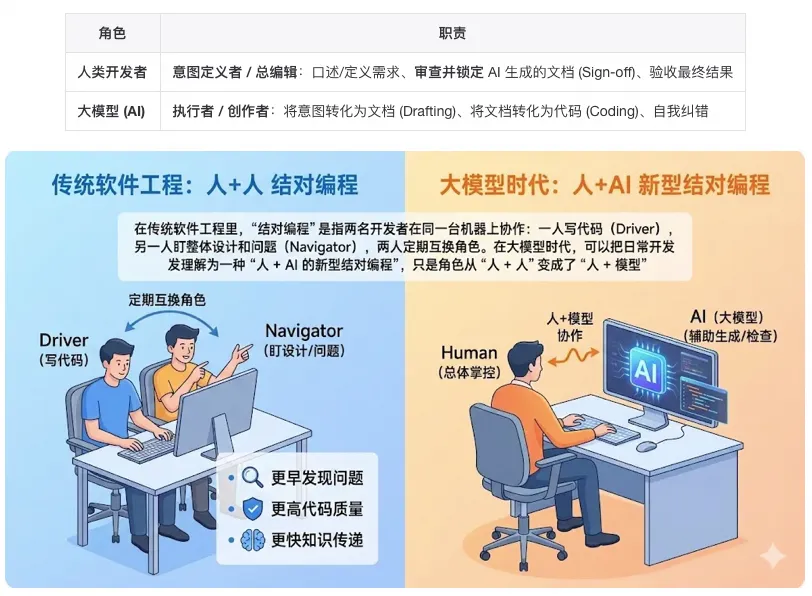
在传统软件工程里,“结对编程”是指两名开发者在同一台机器上协作:一人写代码(Driver),另一人盯整体设计和问题(Navigator),两人定期互换角色。收益主要在于:更早发现问题、更高代码质量、更快知识传递。
在大模型时代,可以把日常开发理解为一种“人 + AI 的新型结对编程”,只是角色从“人 + 人”变成了“人 + 模型”:
在这个模式下,"写代码"不再是你的唯一核心技能,你更多要擅长:
把需求翻译成清晰的 Prompt 和约束条件;
设计合理的步骤(先测试、再改代码、再回归);
识别模型输出中的风险和幻觉,进行二次校对。
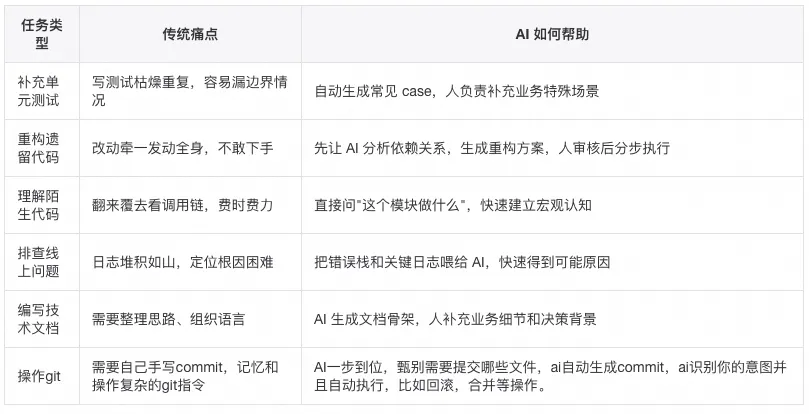
如果你还没有开始用 AI 编程,建议从以下低风险任务开始:
第一次尝试:给现有函数补充单元测试
第二次尝试:理解陌生代码模块
第三次尝试:编写技术方案文档
预期时间:每次 10-20 分钟,完成后你会对 AI 的能力边界有基本认知。
2.2 新的工作节奏:利用“认知缓冲”对抗“代码催眠”
在使用 AI 编程时,你会发现一个显著的变化:键盘敲击声变少了,屏幕前的“等待”时间变多了(我称之为“受迫性摸鱼”)。
请注意:这段“空窗期”不是在浪费时间,而是必要的“认知缓冲(Cognitive Buffer)”。
在大模型高速生成大量代码时,人类很容易陷入“代码催眠”(Code Hypnosis)状态——即看着代码流淌觉得都对,实则大脑已经麻木,失去了批判性思维。
因此,强烈建议大家“合法化”这段等待时间:
强制抽离:在 AI 生成的几十秒内,允许视线短暂离开屏幕,或者清空大脑。这能让你在下一秒 Review 代码时,保持“像看陌生人代码一样”的敏锐度。
思维预演:利用这段间隙,跳出具体语法,在脑中预演逻辑的边界情况,而不是盯着光标发呆。
节奏切换:从“连续的高频输出”转变为“脉冲式的决策—休息—决策”。
给团队的共识:在 AI 时代,不要用“是否一直在敲键盘”来衡量工作饱和度。一个对着屏幕静默思考、正在进行“认知重组”的工程师,往往比一个被 AI 带着跑的工程师,更能守住系统的安全底线。
不要死记某个具体版本"最强",模型迭代很快。
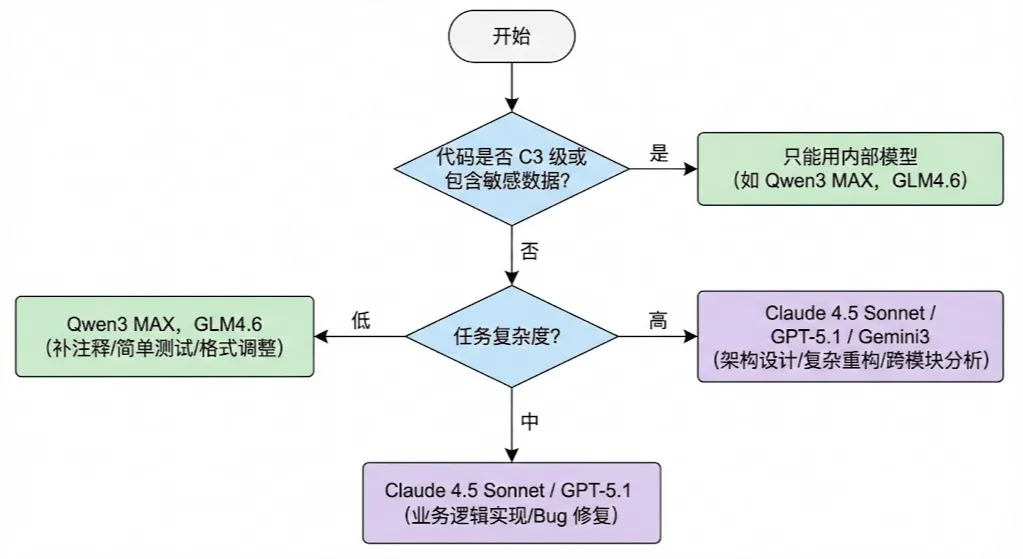
更实用的方式是按决策流程选择:
使用口诀:安全第一,复杂度第二,成本第三
常见模型类型参考:
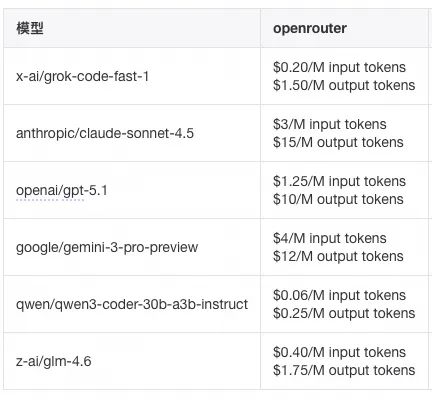
常用模型价格:
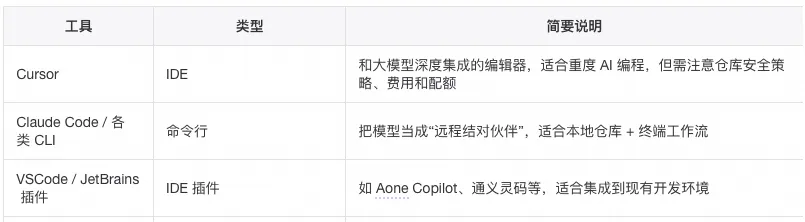
使用原则:
实际使用时,建议团队内统一几种“推荐组合”,例如:
当然在安全可控和你舍得花钱的情况下,你可以使用中转站来使用世界上所有的大模型:
https://openrouter.ai/
https://zenmux.ai/
大模型的“聪明程度”一半来自模型本身,另一半来自你给的提示词(Prompt)。对于经常使用的模型,建议为每个模型准备一份固定提示词文件,例如 claude.md、gpt.md、gemini.md,并在会话开始时整体贴入。
一个实用的个人 Prompt 模板通常包含这些部分:
引用文档:不要在 Prompt 里口述复杂逻辑,请直接引用 URL 或文件路径(@docs/spec.md),让 AI 以文档为准。
角色定义:你希望模型扮演什么角色(结对工程师 / 架构师 / 文档助手等)
目标与范围:这次对话主要解决什么问题,允许/不允许碰哪些模块
工作方式:先问再改、先给方案再写代码、必须生成测试等
禁止事项:不允许拍脑袋造接口、不允许一次改太多文件、不允许忽略安全规则等
输出格式:需要列表、代码块、Diff、还是分步骤说明
项目特定习惯:日志前缀风格、错误码规范、测试框架等
现在因为大模型能力的增强,已经不需要再写以前那种很长的,人设般的提示词了,但是约束型和步骤型的提示词仍然很好用。
网上也有很多很优秀的模版,比如:
https://cursor.directory/
https://github.com/f/awesome-chatgpt-prompts
3.4 进阶技巧:
构建“会自我进化”的 SOP (Real-Time RL Lite)
在深入这个技巧之前,我们需要先对齐一个工程概念,这不仅关乎提示词,更关乎工具链的集成:
💡 核心概念补齐:什么是 Claude Skill?
Claude Skill 是一个将“大模型的思考逻辑”(Prompt/SKILL.md)与“传统代码的执行能力”(Scripts)打包在一起的“能力插件”,旨在让通用的 AI 瞬间变成能精准执行特定复杂任务的垂直专家。
在高阶 AI 编程中,一个成熟的 Skill 通常不止是提示词,而是一个“能力包”,包含两个核心部分:
1. 大脑 (SKILL.md)
2. 手脚 (Scripts/Tools)
结构示例:
my-code-review-skill/├── SKILL.md # 告诉 AI:先跑脚本,再根据日志写评语└── run_linter.py # 实际干脏活累活的传统代码
这种模式的威力在于:你把确定性的逻辑写成脚本(传统编程),把不确定性的逻辑写成 Prompt(大模型编程),然后让 AI 自动调度。
让 Skill 自我进化 (RL Lite)
在 3.3 节中我们提到了静态模板的局限性。“青春版强化学习”的核心逻辑是:每次任务结束后,不只验收代码,还要验收 Skill 包本身。
操作流程:
1. 执行 (Execute):让 AI 读取 SKILL.md 并调用配套脚本执行任务。
2. 复盘 (Review):如果任务失败(例如脚本报错、或者 AI 对脚本输出的理解有误)。
3. 进化 (Evolve):
通过这种方式,你的“资产库”里不仅有越来越聪明的 Prompt,还有一套越来越好用的自动化脚本库。
实战案例:我在使用 Claude Code 时,第一次它生成了不带中文注释的代码。我没有只让它重写,而是让它更新了自己的 Skill 文件。现在的 SKILL.md 里自动多了一行:
Rule 5: All strictly business logic must have simplified Chinese comments explain the 'Why', not just the 'How'.
从此以后,我再也不用在这个问题上浪费口舌。即使哪天换了模型,换了新人,只要这份 SOP 还在,团队的战斗力就能在几分钟内恢复 80%。
我的极速版Gemini.md
Protocol Selection Rules
From now on, please adhere to the following protocols based on the task type:
Medium/Large Code Tasks: Refer to @/Users/wuyue/Documents/RIPER-5.md
Small Code Tasks: Refer to @/Users/wuyue/Documents/RIPER-LITE.md
Documentation Tasks: Refer to @/Users/wuyue/Documents/RIPER-DOC.md
Please try to communicate with me in Chinese as much as possible.
而且你也可以在和大模型的对话和工作的过程中,根据自己的习惯和喜好,命令大模型帮你更新对应的claude skill,这样也可以满足懒人的需求,比如这一版Gemini.md就是我让gemini写的。
这里还有一些claude skill的例子,大家熟练了之后可以作为参考。
https://github.com/ComposioHQ/awesome-claude-skills
4. 基于文档的开发流程 (Spec-Driven Development)
什么是 Spec-Driven Development (SDD)?Spec-Driven Development (SDD) 是一种软件开发方法论,强调在编码开始之前编写详细、结构化的规格说明书(Specifications),通常用于指导 AI 编程代理。它采用分阶段的方法:首先明确用户需求和意图,接着创建技术方案,将工作拆解为微小的、可审查的任务,最后逐一实施这些任务。这一过程旨在通过提供清晰的开发蓝图,减少猜测和返工,从而显著提高代码质量、可控性和可预测性。
这是本指南推荐的标准作业流程。它的核心在于:严禁在没有文档支撑的情况下直接修改代码。让大模型完全基于文档,以文档为唯一核心,这样程序员只需要控制文档,就可以约束大模型,就可以控制代码的质量,保证下限。
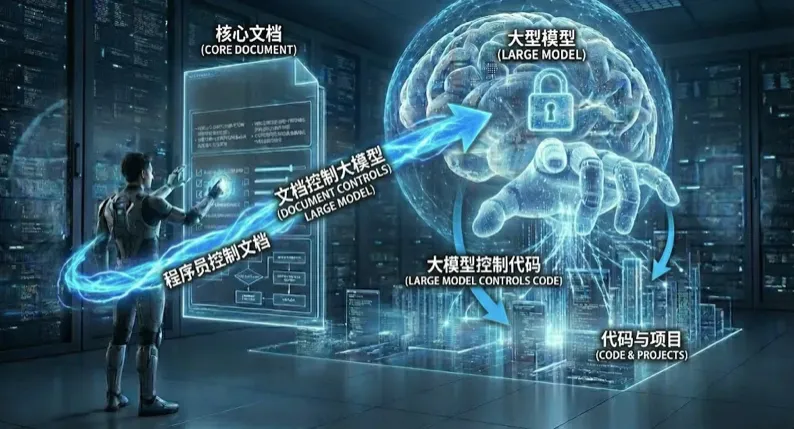
4.1 核心理念:文档即源码 (Doc as Code)
在 AI 编程时代,自然语言文档就是你的“源代码”,而 Java/Python 代码只是某种“编译产物”。
Source Code: requirements.md,api_spec.md,architecture_decision.md
Compiled Binary: UserService.java,main.py
Compiler: LLM (Claude, GPT, Qwen)
4.2 标准工作流 (The SDD Workflow)
Phase 1: 意图定义与文档生成 (Intent & Spec Generation)
- Prompt: "我想给结算流程增加 VIP 折扣,参考现有的 Coupon 逻辑。"
- Result: AI 生成了
docs/tasks/vip-discount.md,包含修改步骤、接口定义和数据流。
Phase 2: AI 编译 (AI Implementation)
Phase 3: 文档验收 (Verification & Alignment)
动作:检查 AI 生成的代码。
关键点:如果发现代码逻辑不对,不要直接动手改代码,也不要只在对话框里骂 AI。
正确做法:回到 feature-xxx.md,修改描述得不清楚的地方(比如增加一个约束条件),然后让 AI “重新编译”(Re-generate)。
原因:这样能确保你的文档永远是最新的,且下一次(或换一个模型)还能生成正确的结果。
4.3 Demo 示例一:用日志 + AI 做 Debug
(内部项目只能使用内部工具 iflow+Qwen3 coder)
1. 先用大模型添加全流程日志:
2. 推送代码并且部署
让大模型提交代码的好处就是可以帮你自动生成commit和自动解决一些落后和冲突的问题,比如
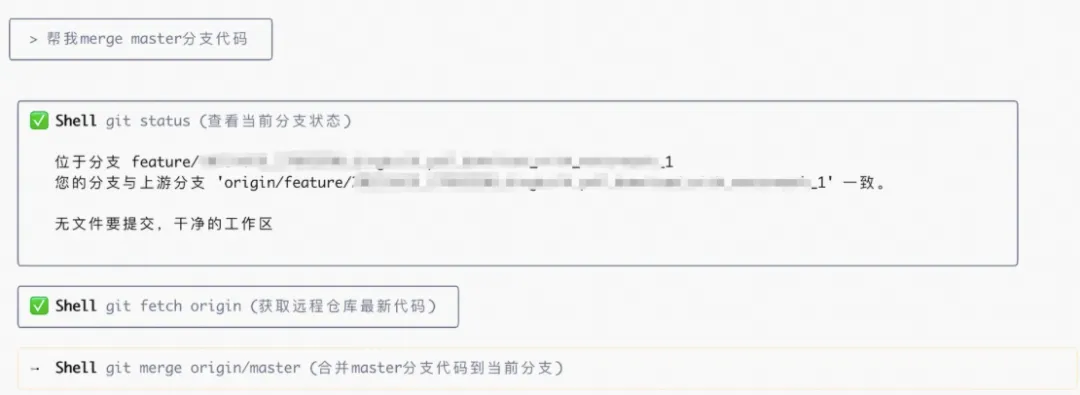
3. 运行测试然后获得日志,再把日志喂给大模型
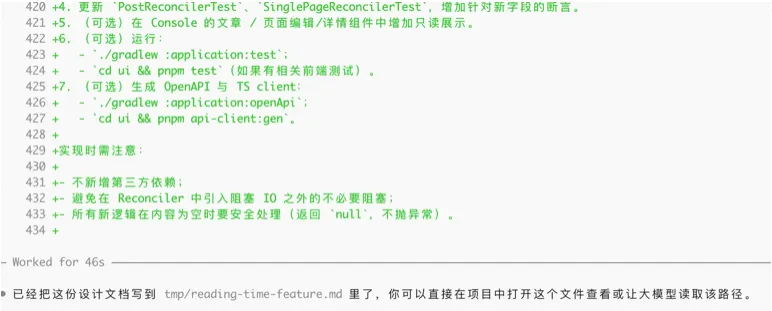
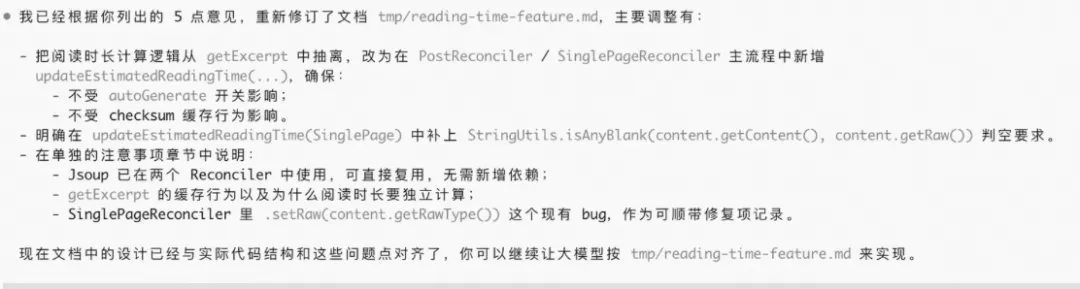
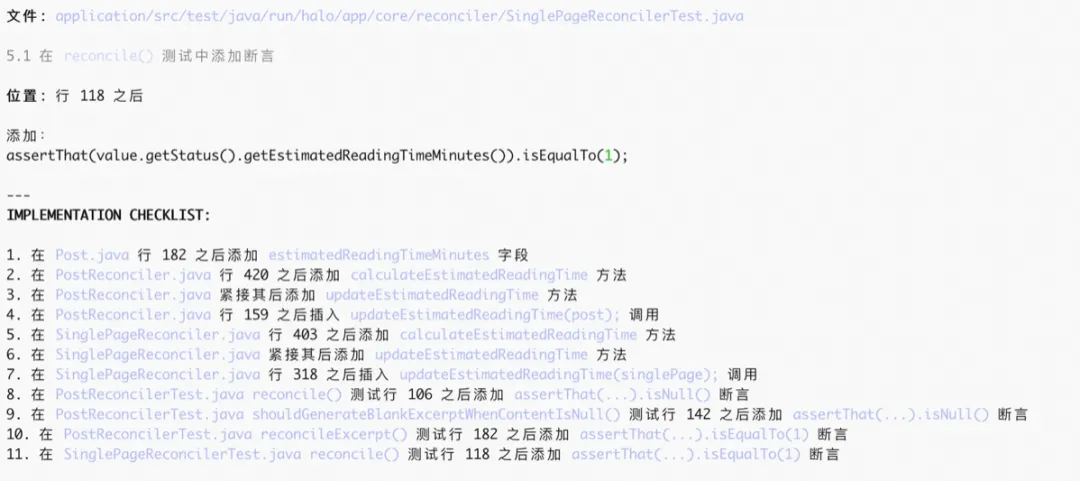
4.4 Demo 示例二:从开源项目到“文档 + 小改动”
(开源项目可以使用任何工具,例如claude code+claude4.5, codex + gpt 5.1, kilo code+gemini3等)
1. 使用大模型A(codex+gpt5.1)来生成文档
花费了大约八分钟(注意token消耗,这都是钱)
2. 提出修改需求,让大模型输出详细的修改文档
3. 让大模型B(claude code + claude 4.5)阅读文档和项目,让他说明这份文档是否足够帮助修改代码,以及有什么可能的问题。
4. 让大模型A根据意见修改文档
如果你有耐心,可以反复让多个大模型互相review,直到他们都不再有意见。
5. 让大模型B开始实施代码
6. 让大模型A和大模型B分别review,最好再加上一个新的大模型C一起review,然后根据意见修改文档和代码。这样反复直到你和大模型都没有更多意见。
7. 让大模型补充大量的日志,并且使用专用的日志管理器,来方便进行debug。
8. 推送和测试。
让大模型提交和推送,再也不用担心推错文件、用错git命令、或者编不好commit了。
最后参考demo示例一,在pre环境进行全流程/回归测试,捕捉对应日志再喂给大模型。
4.5 进阶图景:文档是 AI 智能体之间的“通信协议”
(Protocol of Agents)
我们常把文档看作是“给人看的”,但在大模型时代,文档有了全新的身份:不同 AI 智能体之间的 API。
这开启了一种全新的团队协作模式:以后不再是你和我沟通,而是你的大模型和我的大模型进行沟通,人类只需要做 Review 和信息确认。
这种“Agent-to-Agent”的协作可以覆盖软件工程的全链路:
1. 产品 <-> 开发 (PM AI 🤝 Dev AI):
- 产品经理口述需求,让“产品 AI”生成一份结构化极强、无歧义的
Requirement_Spec.md。 - 开发人员不需人工翻译需求,而是直接把这份文档喂给“架构师 AI”,自动生成
API_Design.yaml 和 DB_Schema.sql。
2. 开发 <-> 开发 (Backend AI 🤝 Frontend AI):
- 前端开发的 AI 读取该文档,自动生成 TypeScript 类型定义、Mock 数据和 API 调用代码。
- 后端改了接口?更新文档,前端 AI 自动感知并重构调用逻辑。
3. 开发 <-> 测试 (Dev AI 🤝 QA AI):
- 开发提供
Design_Spec.md 和 API_Spec.md。 - 测试人员的 AI 读取文档,自动生成
Test_Cases.json 和自动化测试脚本。 - 人类只做验收:人类不再去写每一行测试代码,而是审核测试用例覆盖了哪些业务场景。
这一模式的核心价值:
消除“翻译损耗”:传统模式下(人脑 -> 口述 -> 人脑),信息层层衰减。新模式下(AI -> 标准文档 -> AI),信息以数字精度无损传递。
各司其职的维护:每个人只负责维护自己领域的文档。当需求变更时,上游更新文档,下游让 AI 重新跑一遍 Diff,立刻就能完成全链路的对齐。
文档活化:文档不再是躺在 Wiki 里的死尸,它是连接产品思维、代码实现与测试验证的活性媒介。
| | |
|---|
| 上下文腐烂 | 持续保持在一个对话(session)中很久,导致上下文太长太宽泛,模型注意力丢失。 | 尝试多使用compact指令,并且在解决完一个问题后就使用clear指令清理上下文。 |
| 目标漂移 | | "只优化函数 calculateTotal,不做任何其他的变更,集中于此函数一点。" |
| 幻觉/瞎编接口 | 直接使用 AI 提到的 StringUtils.sanitize() 方法 | 先用 IDE 搜索确认项目里是否真有这个方法,不存在就反馈给大模型,要求它重新给方案。 |
| 过度信任 | 只看 AI 的文字解释:"我已经修复了空指针问题" | 每次都亲自看 Diff,检查是否真的加了空值判断,并运行相关测试验证。每次都让执行大模型和其他大模型进行汇总回报和review。 |
| 一次要求太多 | | 拆成多个小任务,每次只做一个功能模块,尤其是qwen3和GLM4.6等能力稍弱的模型。 |
| 规则过拟合 | 因为一次特殊情况骂了 AI,导致它在 SOP 里写死了一条极其严苛的规则(如“禁止使用任何第三方库”),导致后续任务卡死。 | 定期 Review 你的 Prompt/SOP 文件*。像重构代码一样重构 Prompt,删除过时或太死板的规则,保持指令的通用性。 |
核心原则:AI 是很厉害的实习生,不是无需审核的高级工程师。
5. 进阶防守:对抗“复杂度熵增”与“最后 10% 陷阱”
很多新手在使用 AI 编程时容易陷入一种线性的乐观:“既然 10 分钟能写完前 50%,那剩下 50% 肯定也很快。”
但真实的大模型开发曲线是非线性的。为了避免项目在收尾阶段崩盘,我们需要引入一套**“防守型开发策略”**。
在传统编程中,难度通常是渐进的。但在 AI 编程中,存在一个显著的**“最后 10% 陷阱”**:
警惕:往往最后的 10% 的功能完善,很有可能需要占用整个开发周期 20% 至 30% 的时间。
在这个阶段,代码的复杂度熵增极快。一个微小的改动(比如修个 UI)可能导致后端核心逻辑崩塌(Regression)。如果你此时还在盲目追求速度,大概率会陷入“修一个 Bug,生出三个新 Bug”的死循环。
5.2 核心策略:建立“文档-代码同步记录仪” (ChangeLog)
为了对抗混乱,我们不能只依赖 Git 的 commit,而需要建立一份由 AI 自动维护的 ChangeLog。更重要的是,这份日志必须追踪文档与代码的一致性。
它的核心价值在于:
1. 认知对齐:当开发了两天后,最早的需求约束会被遗忘。ChangeLog 帮你回忆“我们根据哪个版本的文档做了哪些改动”。
2. 法医级溯源:如果代码逻辑和文档不一致,ChangeLog 能帮你判断是“文档改了没同步代码”还是“AI 只有幻觉”。
关键原则:
Code follows Doc: 所有的 ChangeLog 必须注明依据的文档版本/文件名。
No Doc, No Code: 如果 ChangeLog 里出现了一条没有对应文档支撑的代码变更,这就是危险信号。
5.3 实战落地:用 Skill 强制执行 (Auto-Flight Recorder)
与其靠人工自律去写日志(这很难坚持),不如利用我们在 3.4 节提到的 Skill 技术,把这个动作变成强制执行的肌肉记忆。
我们只需做两步配置,就能让 AI 变成自带“黑匣子”的靠谱副手。
第一步:准备“手脚” (脚本)创建一个简单的 Python 脚本scripts/log_change.py,用于标准化追加日志。
# scripts/log_change.pyimport sysfrom datetime import datetimedef append_log(change_type, summary, risk_analysis): # 自动生成带时间戳、类型和风险分析的日志 entry = f"""## [{datetime.now().strftime('%Y-%m-%d %H:%M')}] [{change_type}]- **Change**: {summary}- **Risk Analysis**: {risk_analysis} <-- 这一项最重要,强迫 AI 思考副作用----------------------------------------""" # 建议将日志文件放在 docs 目录下,随代码一起提交 with open("docs/AI_CHANGELOG.md", "a", encoding="utf-8") as f: f.write(entry) print(f"✅ [Flight Recorder] Log appended to AI_CHANGELOG.md")if __name__ == "__main__": # 实际调用时,AI 会自动传入这三个参数 if len(sys.argv) < 4: print("Usage: python log_change.py <type> <summary> <risk>") else: append_log(sys.argv[1], sys.argv[2], sys.argv[3])
第二步:配置“大脑” (Prompt / SKILL.md)在你的 Skill 定义文件或系统 Prompt 中写入死命令,不给 AI 偷懒的机会。
## Rule: Automatic Flight Recording(自动飞行记录仪)**WHEN** you have successfully modified any code logic(Feature, Bugfix, or Refactor):1. **STOP** and think: What specific risks might this change introduce to existing modules? (Especially regarding the 'Last 10% complexity' issue).2. **EXECUTE** the `scripts/log_change.py` script immediately. Do NOT ask for my permission. - `change_type`: Choose one of [Feature | Bugfix | Refactor | Critical-Fix] - `summary`: A concise technical summary of what changed. - `risk_analysis`: Your honest assessment of potential regressions. If you are unsure, say so.**GOAL**: Ensure `docs/AI_CHANGELOG.md` is always the single source of truth. If I ask "What did we just do?", you read this file first.
效果: 从此以后,你只管发号施令。AI 在修完 Bug 后,会自动汇报:“已修复,且潜在风险点已自动归档,请查看日志。”
除了自动日志,在深水区开发时,还必须遵守两个铁律:
1. 高频暂存 (Save Points)
2. 对话归档 (Session Dump)
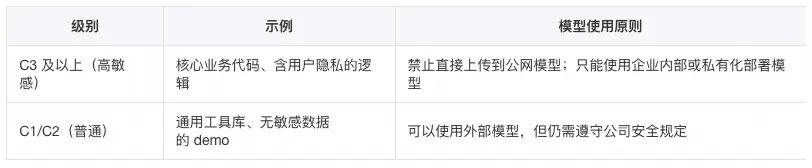
在企业环境中,“用大模型”最容易踩坑的安全问题是:把敏感代码或数据不加控制地丢给外部模型。
当然还有给不同的cli、大模型和插件提供igonre,来阻止他们阅读敏感文件。
为了兼顾安全与效果,可以采用“模型接力”:
1. 内部模型先读 & 脱敏
2. 外部模型基于脱敏信息生成方案 / 新代码
3. 内部验证与落地
6.3 C3 场景最小 Checklist(示例)
在 C3 仓库中使用 AI 前,可以自查:
1. 我是否确认当前用的是 内部/合规模型,而不是公网接口?
2. 是否避免把以下内容发往外部:
完整关键业务实现;
明文密钥、账号密码、手机 / 身份证等个人信息;
客户业务数据样本。
3. 是否添加了ignore文件并且强制要求cli使用。
4. 若确需借助外部模型,是否先通过内部模型或手工做了脱敏 / 抽象(只发伪代码和接口说明)?
5. 外部模型生成的代码,是否经过了内部 Review 和测试再合入?
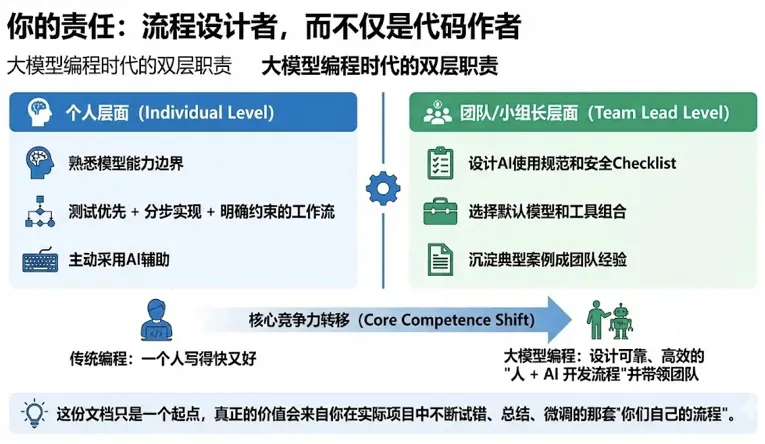
结合前面的内容,可以把"大模型编程"理解为两层职责:
1. 个人层面
2. 团队层面
如果说传统编程时代,你的核心资产是“你脑子里的经验”和“你写下的代码”;那么在大模型编程时代,你最宝贵的核心资产将变成:**这一整套“文档驱动的开发体系”——包括精细的需求文档、架构设计、Review 标准,以及那份会自我进化的 Prompt/SOP 库。**即使哪天换了模型,换了新人,只要流程和SOP 还在,团队的战斗力就能在几分钟内恢复 80%。
这份文档只是一个起点,真正的价值会来自你在实际项目中不断试错、总结、微调的那套"你们自己的流程"。
Q1: 用 AI 写的代码出 Bug,责任算谁的?
A: 算你的。AI 是工具,你是使用者和最终 Review 者,就像用 Stack Overflow 复制的代码出问题,责任也在你。最终上线的代码质量由你负责。
Q2: 学习 AI 编程会不会让我的编码能力退化?
A:类比思考:用 IDE 自动补全不会让你忘记语法,但会让你不再记忆 API 细节。关键是理解原理而非记忆语法。AI 编程会让你:
更少关注"怎么写一个循环"
更多关注"系统架构是否合理"
编码能力不会退化,但能力重心会上移
Q3: 我的代码会不会被模型拿去训练,泄露给别人?
Q4: AI 总是给出错误答案,是不是不可用?
A:需要调整使用方式:
1. 明确约束:不要问"帮我写个登录功能",而要说"用 Spring Security + JWT 实现登录,Token 有效期 2 小时"
2. 分步验证:不要一次生成整个模块,而是先让 AI 给方案,你确认后再分步实现
3. 主动纠错:发现错误立即反馈给 AI:"这个方法不存在,请使用项目里已有的 XxxUtils"
Q5: 用了 AI 之后,我还需要学习新技术吗?
A:必须学,而且可能要学得更快。AI 可以帮你:
反而因为 AI 降低了"实现成本",你会有更多精力去探索新技术。
Q6: AI 能完全取代程序员吗?
A:不能,至少在可预见的未来不行。AI 在很多重复性、模式化、实现层面的工作上确实已经可以做到比普通工程师更稳定、更高效,但它有几个天然短板:
很难真正理解那些含糊、暧昧、不断变化的产品需求,只能根据你给的描述去“猜”;
无法主动协调多个子系统、多个 Sub AI 以及跨团队沟通,它只能在你设计好的流程里执行;
最关键的一点:它没法为线上事故和业务决策背锅,也承担不了合规和安全责任。
所以更现实的图景是:能熟练驾驭 AI 的工程师会替代不会用 AI 的工程师,而不是“AI 整体替代所有程序员”。你的不可替代之处在于理解业务、拆解问题、设计流程,以及为结果负责——AI 帮你干活,但短期内还抢不走你的饭碗。
Q7: 使用大模型效率提升了,团队是不是应该承担双倍的需求吞吐量?
A: 这是一个需要高度警惕的“效率陷阱”。
虽然 AI 加快了“编码(Coding)”的速度,但它并没有缩短“思考(Thinking)”、“审查(Reviewing)”和“验证(Testing)”的时间。相反,AI 生成代码的速度越快,代码审查的密度要求就越高。
如果因为 AI 写得快,就盲目将需求吞吐量翻倍,会导致两个严重的后果:
1. “泡沫代码”堆积:AI 极易生成“看起来能跑但逻辑脆弱”的代码。如果没有足够的人工 Review 时间,这些代码会迅速变成难以维护的“技术债”。
2. 风控防线失效:当排期被压缩到只能“由 AI 生成并直接提交”时,工程师实际上失去了对系统的掌控力。一旦发生线上故障,修复成本将指数级上升。
结论:AI 节省下来的时间,不应被全部转化为“更多的功能数量”,而应被重新投资到“更高的代码质量”和“更完备的测试覆盖”上。这才是实现降本增效(降低维护成本,增加开发效率)的正确路径。
注:以上图片均由Gemini3制作,内容由GP5.1、Gemini3、Qwen生成。
开源项目由Claude4.5和GPT5.1操作。