triton.language 简写为 tl,提供了 Python API 可以使用 Triton 编写 GPU kernel。定义了 data type, 编程模型原语kernel编写并行计算。
主要包括 类型系统,张量操作,语言构建:
编程模型 Programming Model
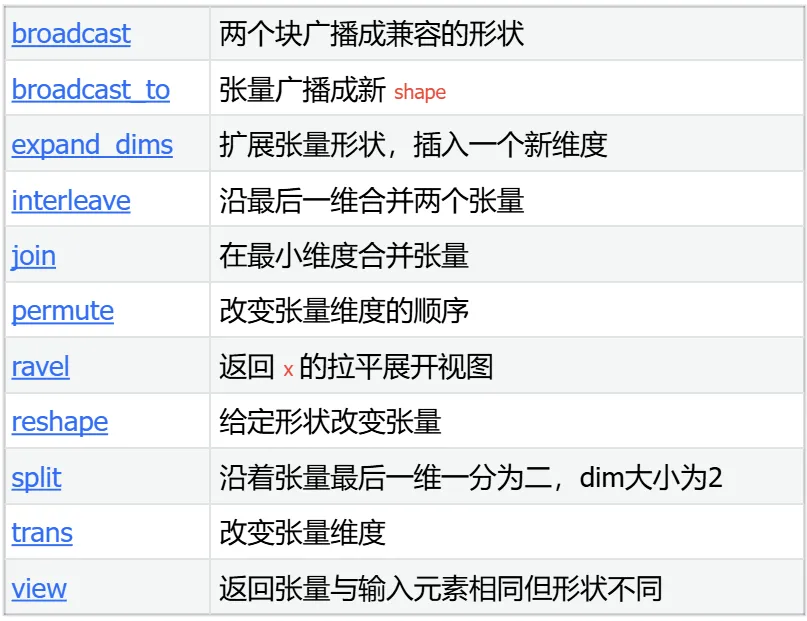
张量创建 Creation Ops
形状操作算子 Shape Manipulation Ops
线性代数 Linear Algebra Ops
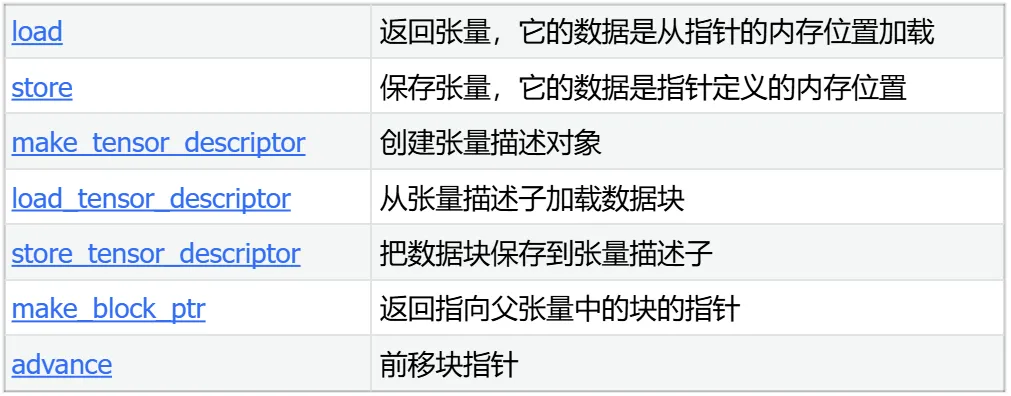
内存/指针操作 Memory/Pointer Ops
索引运算 Indexing Ops
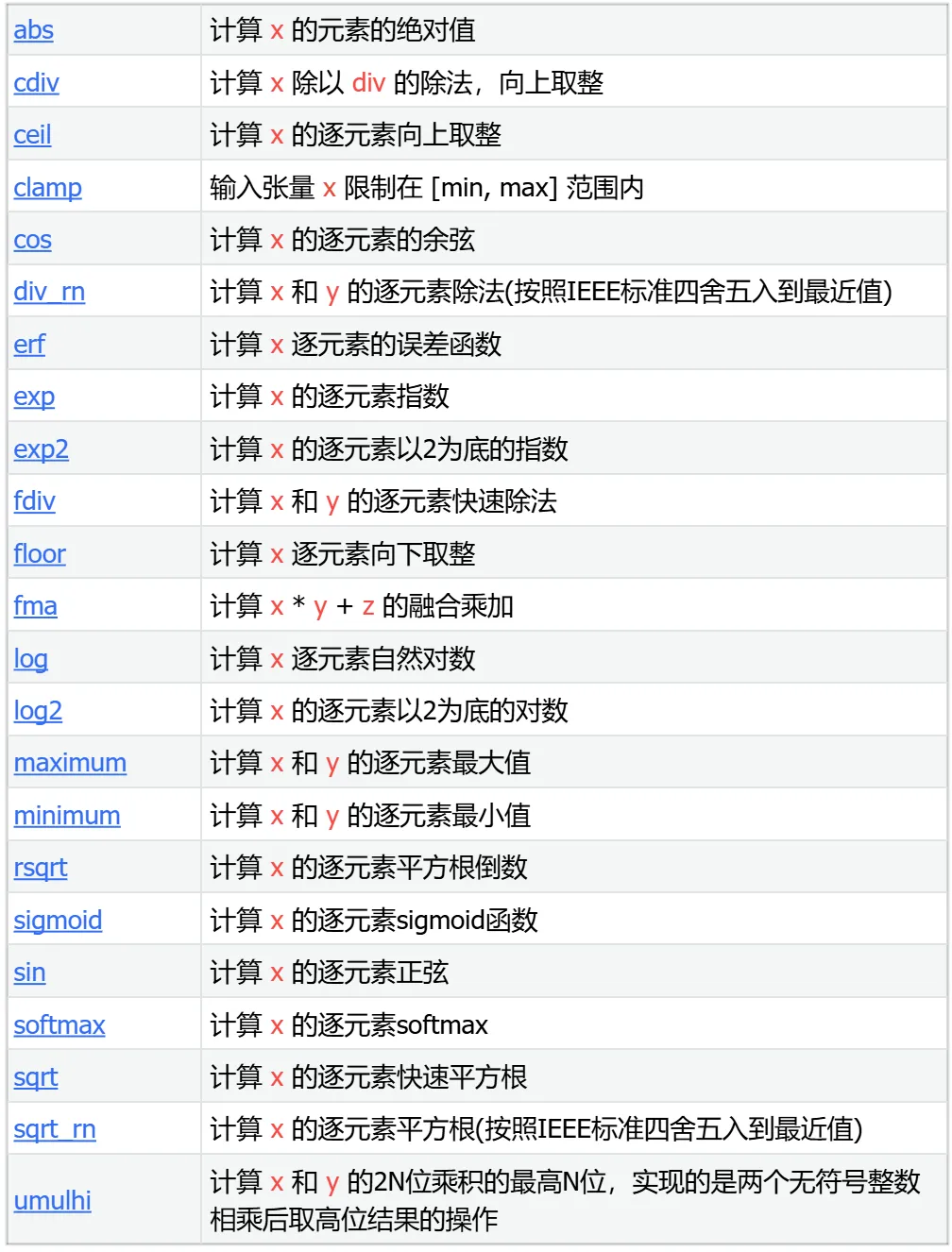
数学运算 Math Ops
归约运算 Reduction Ops
扫描/排序运算 Scan/Sort Ops
原子运算 Atomic Ops
随机数生成 Random Number Generation
迭代器 Iterators
内联汇编 Inline Assembly
编译器提示算子 Compiler Hint Ops
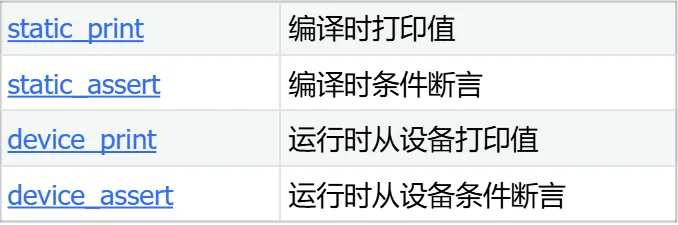
调试算子 Debug Ops
Grid 和 线程 序号
program_id 是 Triton并行编程模型中的核心概念,它用于标识在 并行执行网格中当前执行的program 实例 线程块的位置。
@builtindef program_id(axis, _semantic=None) -> tensor
返回当前 program 实例沿指定轴 axis (0、1、2)的索引。axis(int) 三维网格的轴,必须是 0, 1 或 2。
核心要点:
🥝并行执行网格:当Triton内核启动时,它会创建一个三维网格结构,每个网格单元运行一个程序实例。
🥝程序实例ID:program_id 返回当前实例在网格中的坐标位置。
🥝与CUDA类比:类似于CUDA中的 blockIdx.x、blockIdx.y、blockIdx.z。
基本用法
import tritonimport triton.language as tl@triton.jitdef kernel(input_ptr, output_ptr, N, BLOCK_SIZE: tl.constexpr): # 获取当前程序实例在X轴的位置 pid = tl.program_id(axis=0) # 计算数据偏移量 offset = pid * BLOCK_SIZE # 确保不越界 mask = offset + tl.arange(0, BLOCK_SIZE) < N # 加载数据 data = tl.load(input_ptr + offset, mask=mask) # 处理数据 processed = data * 2 # 存储结果 tl.store(output_ptr + offset, processed, mask=mask)
多维网格的使用
@triton.jitdef matrix_kernel(A_ptr, B_ptr, C_ptr, M, N, K, BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr): # 获取在网格中的位置 pid_m = tl.program_id(axis=0) # 行方向 pid_n = tl.program_id(axis=1) # 列方向 # 计算每个块处理的数据范围 row_offset = pid_m * BLOCK_M col_offset = pid_n * BLOCK_N # 创建范围向量 row_range = tl.arange(0, BLOCK_M) col_range = tl.arange(0, BLOCK_N) # 创建掩码(边界检查) row_mask = row_offset + row_range < M col_mask = col_offset + col_range < N # ... 矩阵乘法计算逻辑 ...
triton.language.load
triton.language.load(pointer, mask=None, other=None, boundary_check=(), padding_option='', cache_modifier='', eviction_policy='', volatile=False, _semantic=None)
从内存中加载数据,返回一个张量,其值由 pointer 参数定义的内存位置加载得到。
加载行为的三种情况
🥝当 pointer 是一个单元素指针时,加载一个标量值
- mask 和 other 也必须是标量
- other 会被隐式转换为 pointer.dtype.element_ty 类型
- boundary_check 和 padding_option 必须为空
🥝当 pointer 是一个 N 维指针张量时,加载一个 N 维张量
- mask 和 other 会被隐式广播到 pointer.shape 形状
- other 会被隐式转换为 pointer.dtype.element_ty 类型
- boundary_check 和 padding_option 必须为空
🥝当 pointer 是由 make_block_ptr 定义的块指针时,加载一个张量
- mask 和 other 必须为 None
- boundary_check 和 padding_option 可以指定,用于控制越界访问的行为
参数说明
🥝pointer (triton.PointerType 或 dtype=triton.PointerType 的张量),指向待加载数据的指针
- 必需:是
🥝mask (triton.int1 类型的张量,可选),如果 mask[idx] 为 false,则不加载地址 pointer[idx] 处的数据。注意:与块指针一起使用时必须为 None。
- 默认:None
🥝other (张量,可选)
- 描述:如果 mask[idx] 为 false,则返回 other[idx] 的值
- 默认:None
🥝boundary_check (整数元组,可选),表示应进行边界检查的维度
- 默认:()
🥝padding_option (字符串),越界时使用的填充值,应为以下之一:
- "":未定义值
- "zero":零填充
- "nan":NaN 填充
🥝cache_modifier (字符串,可选),改变 NVIDIA PTX 中的缓存选项,应为以下之一:
- "":默认
- ".ca":在所有层级缓存(缓存到所有级别)
- ".cg":在全局层级缓存(缓存到 L2 及以下,不缓存到 L1)
- ".cv":不缓存并重新获取
🥝eviction_policy (字符串,可选),改变 NVIDIA PTX 中的回收策略
- 默认:""
🥝volatile (布尔值,可选),改变 NVIDIA PTX 中的 volatile 选项
- 默认:False
基本加载示例
import triton.language as tl# 标量指针加载scalar_ptr = tl.make_ptr()scalar_value = tl.load(scalar_ptr)# 张量指针加载tensor_ptrs = tl.make_tensor_of_pointers(...)tensor_values = tl.load(tensor_ptrs, mask=mask_tensor, other=default_tensor)
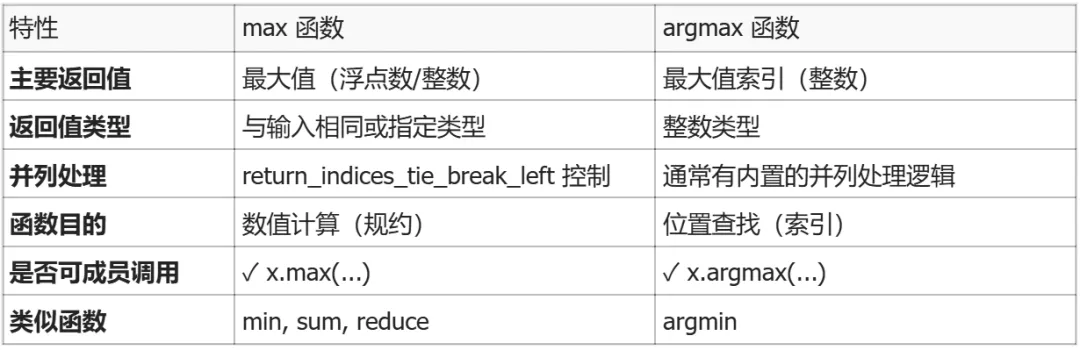
triton.language.max
核心功能: 计算张量沿指定轴的最大值。
特点: 可以可选地返回最大值的索引,但这不是主要目的。
本质: 一个规约操作,主要输出是数值结果。
triton.language.argmax
核心功能: 专门返回张量沿指定轴的最大值索引。
特点: 只返回索引,不返回具体的最大值。
本质: 一个索引查找操作,主要输出是位置信息。