—— 导读 ——
之前写过不少关于 awk 的笔记,但是基本上都是一个个关于需求/功能实现上的。隔段时间不用 awk ,再去翻过去的文章,知道使用以后能实现什么样的效果,但是为什么能达到这样的效果却是说不出来,甚至有些连语法都忘记了。于是打算出一个合集,系统性地介绍下 awk 的使用,减少后续重复学习的成本。本篇主要对 awk 做一个介绍,包括 awk 是什么、awk 应用场景、awk 语法、awk 程序的运行、awk 程序的执行流程等。Awk 这个名字源自其设计者姓名的首字母:Alfred V. Aho、Peter J. Weinberger 和 Brian W. Kernighan。awk 的基本功能是在文件(或其他文本单元)中搜索包含特定模式的行。当某一行匹配某个模式时,awk 就会对该行执行指定的动作。awk 会以这种方式持续处理输入行,直到到达输入文件的末尾。
Awk 的应用场景非常广泛,特别是在linux系统下,对执行命令后输出的结果做处理、在shell脚本中的应用或者直接用于处理数据文件等等。我这里随便列几个常用的示例:
du 命令 + awk 分析磁盘占用,查找占用磁盘空间比较大的目录等。
netstat 命令 + awk 分析TCP连接情况,分组统计不同状态连接的数量、不同IP的连接数量等。
shell 脚本中使用 awk 给变量批量赋值、格式化字段值、输出格式化等。
对nginx等标准格式的日志进行时间范围查找、关键字匹配、分组统计等分析场景。
对文件中指定列进行求和、将每几行合并为一行、基于多个文件中的相同字段实现数据合并等。
当你运行 awk 时,需要指定一个 awk 程序,告诉 awk 要做什么。该程序由一系列规则(rules)组成(也可能包含函数定义——这是一个高级特性,我们暂时忽略),规则之间通常用换行符分隔。每条规则指定一个要搜索的模式,以及在找到该模式后要执行的动作。
从语法上看,一条规则由一个模式(pattern)后跟一个动作(action)组成。动作用花括号{}括起来,以与模式分隔。模式和动作两者都是可选的,可以省略其中任意一个,但不能同时两个都省略。因此,一个 awk 程序看起来如下所示:
[pattern] [{ action }][pattern] [{ action }]...
模式(pattern)
模式用于控制动作的执行——当模式的规则和某一行内容相匹配时,才会执行后面的动作。常用的模式包括:
- /regular expression/:正则表达式。当输入行的文本内容符合该正则表达式时,即视为匹配。例如:/zcy/ 表示匹配包含zcy字符的行(数据)。
- expression:单个表达式(表达式的值为数字0或空字符串时也会被判定位不匹配)。例如:$2 > 20 匹配第二个字段的值大于20的行。
pat1, pat2:由逗号分隔的两个模式,用于指定一个范围。该范围从第一个匹配 pat1 的行开始,到第一个匹配 pat2 的行结束(包含这两个端点)。例如:$1 == "lisi" , $1 == "wangwu" 匹配从第一个字段内容为lisi的行到第一个字段内容为wangwu之间的行。
BEGIN、END:用于为 awk 程序提供启动初始化(BEGIN)或退出清理(END)操作的特殊模式。BEGIN 和 END 规则必须包含动作(action);因为当这些规则执行时,并不存在“当前记录”,所以它们没有默认动作。长期使用 awk 的程序员通常将 BEGIN 和 END 规则称为“BEGIN 块”和“END 块”。
empty:空模式(省略掉不写模式部分)会匹配每一个输入行。
动作(action)
动作由一个或多个 awk 语句组成,并用花括号 {} 括起来。每条语句指定一项要执行的操作。语句之间可以用换行符或分号分隔。常用的语句包括:
需要注意的是,如果省略了action部分,那么花括号也应一并省略。省略action等价于 { print $0 },例如:/zcy/ {} # 匹配包含zcy字符的行,但是不执行任何动作。/zcy/ # 匹配包含zcy字符的行,并打印当前行。
运行 awk 程序有两种方式。如果程序较短,最简便的方法是直接将程序写在运行 awk 的命令行中:
awk 选项 '程序' 待处理数据文件1 待处理数据文件2 ...
当程序较长时,更方便的做法是将其保存到一个文件中,然后使用 -f 选项加载awk程序运行(程序文件可以是任意合法的文件名,为了方便区分,可以在文件名后加上 .awk 扩展名)。
awk -f 程序文件 待处理数据文件1 待处理数据文件2 ...
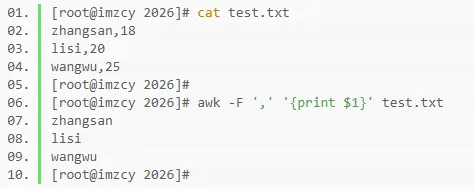
命令行形式运行示例
如下awk命令通过-F选项指定字段分隔符为英文逗号,空模式匹配所有行,动作为输出test.txt文件中匹配行数据中逗号分隔的第一个字段的内容。
文件形式运行示例
为了方便做测试,在上面的test.txt数据文件尾部新增了一行数据。
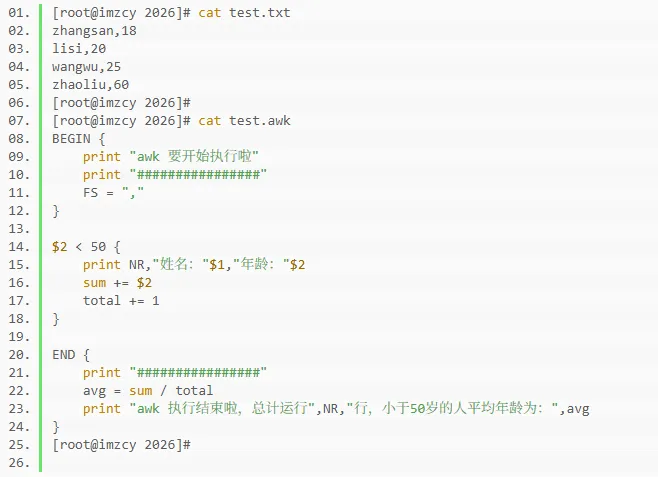
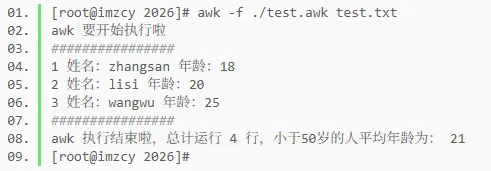
分析test.awk程序文件可以看出:
BEGIN块首先输出了一个开始运行的头,并通过重新给内置变量FS赋值来指定字段分隔符为英文逗号。
BODY块中只有一条规则,定义了一个单个表达式模式,匹配test.txt数据文件中逗号分隔的第二个字段值小于50的行,匹配成功的才会执行后续的动作。
动作中第一条语句打印当前处理的行号(NR)及格式化后的字符串内容。
动作中的第二条语句定义了一个自增变量sum,其值为匹配行的第二个字段值的和。
动作中的第三条语句定义了一个自增变量total,其值为匹配的行数的和。
END块首先输出了一个井号分隔行,然后定义了一个变量avg,值为BODY块中定义的sum变量除以total变量的结果。最后输出了一个格式化后的字符串行。
上面文件形式的程序也可以转换为awk命令行形式来执行,虽然运行结果是一样的,但是可以看出代码较长时通过命令方式来写会不利于阅读和修改。
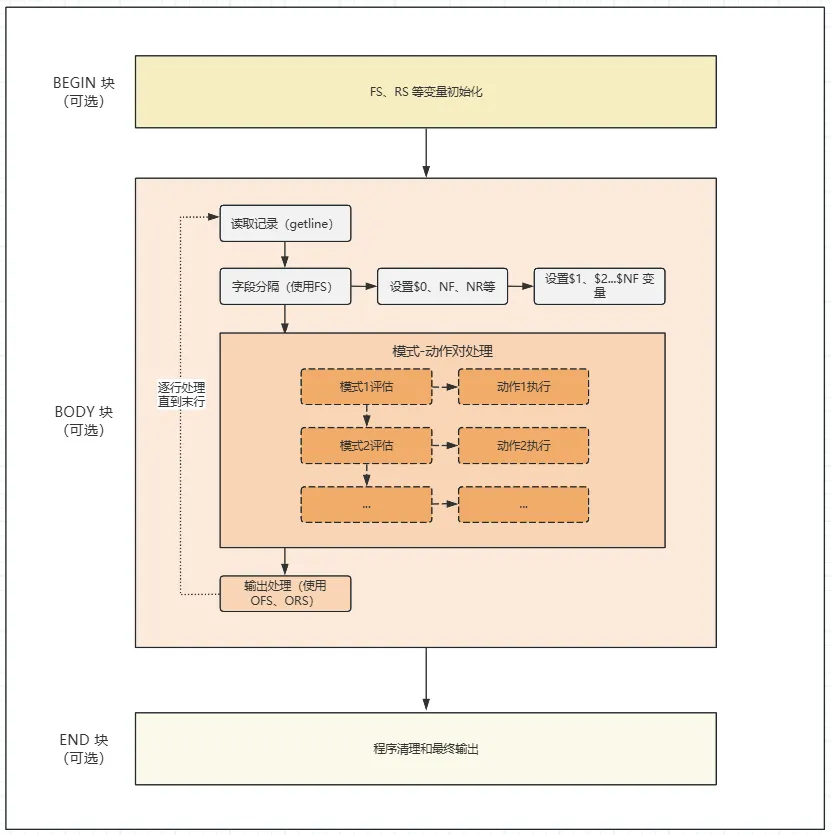
awk 执行流程大致如下图所示:
从程序执行流程的角度上,可以将awk分为三块:BEGIN、BODY 和 END。三个部分都是可选的,但是至少要有其中一个存在。一般情况下仅显式使用 BODY 块,也就是 [pattern] [{ action }] 语句。BEGIN 在第一个输入记录被读取之前执行,仅执行一次。BODY 对每一个输入记录依次执行(默认按行读取,每行执行一次)。END 在所有输入数据处理完毕之后执行,也仅执行一次。
BEGIN 部分介绍
awk 工具会自动将输入内容划分为记录(records)和字段(fields),供你的 awk 程序处理。记录之间通过一个称为“记录分隔符”(record separator)的字符进行分隔。默认情况下,记录分隔符是换行符(newline),因此默认的记录就是单行文本,也就是说awk默认每次从数据文件中读入一行数据进行处理。你可以通过将其他字符赋值给内置变量 RS 来使用不同的记录分隔符。
当 awk 读取一行数据时,解释器会自动将该行数据解析(或分割)成若干称为“字段”(fields)的片段。默认情况下,字段以空白字符(whitespace)作为分隔符,就像一行中的单词那样。在 awk 中,所谓空白字符指的是一个或多个空格、制表符(tab)或换行符(newline)组成的字符串;引入字段的目的,是为了让你更方便地引用一行数据中的各个部分,有点像excel表格通过列和行(例如A1)快速引用单元格内容一样。你可以通过将其他字符赋值给内置变量 FS 来使用不同的字段分隔符。通常修改分隔符最合适的时机是在程序刚开始执行、尚未读取任何输入之前,这样第一行数据就能使用正确的分隔符进行读取。因此,对记录分隔符(RS)和字段分隔符(FS)包括输出记录分隔符(ORS)和输出字段分隔符(OFS)的定义一般都放在BEGIN块中。
BEGIN { print "awk 要开始执行啦" print "################" FS = ","}
BODY 部分介绍
在awk程序中,使用美元符号 $ 后跟字段编号来引用某个字段,1表示第一个字段,2表示第二个字段,依此类推 $9 表示第9个字段。如果要引用完整记录(整行),则需要使用$0表示。
NF 是一个内置变量,其值为当前行数据中解析出来的字段的总数。每当 awk 读取新的一行数据时,都会自动更新 NF 的值。无论一行中包含多少字段,最后一个字段都可以用 $NF 来表示。
awk 会跟踪当前输入文件中已读取的行数量,该值存储在一个名为 FNR 的内置变量中。每当开始处理一个新文件时,FNR 会被重置为零。另一个内置变量 NR 表示从所有数据文件中已读取的数据行总数。它从零开始计数,但不会在处理新文件时自动重置为零。
前面介绍的这些都是awk内部在读取一行数据后自动进行的的一些操作,更主要的,也就是我们awk程序的核心是数据进来以后基于用户自定义的一系列规则对匹配的行要执行什么样的操作。比如定义变量、进行算数运算、打印信息等。$2 < 50 { print NR,"姓名:"$1,"年龄:"$2 sum += $2 total += 1}
文件中每行数据都会被依次处理,直到到达输入文件的末尾,才会进入到END部分。END 部分介绍
END 部分通常用来定义程序清理和最终报告输出相关的语句。如果一个 awk 程序仅包含 BEGIN 规则而没有其他规则,则程序在执行完 BEGIN 规则后会立即退出。然而,如果程序中存在 END 规则,即使没有其他规则,awk 仍会读取全部输入(直至文件结束)。这是为了确保 END 规则能够检查 FNR 和 NR 等变量的值。
END { print "################" avg = sum / total print "awk 执行结束啦,文件总计",NR,"行,成功匹配",total,"行,小于50岁的人平均年龄为:",avg}



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
