“在Linux内核中,跟踪(Tracing)和事件记录是调试、性能分析和安全审计的核心手段。然而,这些操作必须在不显著影响系统正常运行的前提下进行,尤其是在中断(IRQ)、不可屏蔽中断(NMI)等高优先级上下文中。环形缓冲区(Ring Buffer)正是为此而生的高性能、无锁、Per-CPU 存储引擎。它不仅是ftrace、perf等子系统的底层支柱,其精妙的设计思想也值得每一位内核开发者学习。本文将深入剖析Linux 6.6内核中环形缓冲区的实现原理。”
1.架构概览:为极致性能而生
1.1 设计目标
环形缓冲区的设计哲学围绕着几个核心目标: 零锁写入 (Lockless Write):这是最关键的特性。每个CPU核心只向自己专属的缓冲区写入数据,从根本上消除了多核写入时的竞争和锁开销。 无竞争读取 (Non-Contentious Read):读者(通常是用户空间进程)通过一个独立的“读者页”(reader page)来读取数据,与写入者路径分离,避免了读写冲突。 时间戳压缩 (Timestamp Compression):连续事件的时间戳通常非常接近。环形缓冲区采用 Delta 编码,只存储与上一个事件的时间差,大幅节省了存储空间。 Buffer Swap (缓冲区交换):支持在运行时将整个缓冲区的内容“快照”到另一个缓冲区,这对于捕获瞬时状态(如系统崩溃前一刻)至关重要。 NMI 安全 (NMI Safe):整个写入路径不依赖任何可能睡眠的锁或内存分配,因此可以在 NMI 这种最高优先级的上下文中安全使用。
1.2 核心文件
· kernel/trace/ring_buffer.c:环形缓冲区的核心逻辑实现,包含了所有关键的数据结构和操作函数。
· include/linux/ring_buffer.h:对外暴露的公共API接口定义。
· kernel/trace/trace_clock.c:提供高精度、低开销的时间戳获取接口。
1.3 内存布局图解
理解环形缓冲区的关键在于掌握其分层的内存结构。

图解说明:
· 一个全局的ring_buffer结构管理着整个缓冲池。
· 它为系统中的每个CPU分配一个独立的ring_buffer_per_cpu结构,实现了 Per-CPU 隔离。
· 每个ring_buffer_per_cpu拥有一个由buffer_page组成的循环链表,这些buffer_page是真正的数据容器。
· buffer_page的page成员指向一个标准的4KB内核页,其内容以buffer_data_page的格式组织。
· 最终,事件以紧凑的ring_buffer_event格式被序列化到data[]区域中。
2.核心数据结构剖析
2.1 ring_buffer(顶层管理者)
struct ring_buffer {
unsigned long pages; // 总页数
cpumask_var_t cpumask; // 参与的CPU掩码
struct ring_buffer_per_cpu **buffers; // Per-CPU缓冲区数组
u64 (*clock)(void); // 时间戳函数指针
// ... 其他辅助成员,如工作队列等
};
这个结构是全局视角的管理者,它不直接处理数据,而是协调各个 CPU 的缓冲区,并提供统一的时钟源。
2.2 ring_buffer_per_cpu(Per-CPU 工作单元)
struct ring_buffer_per_cpu {
int nr_pages; // 本CPU拥有的页数
struct list_head pages; // 页的循环链表
struct buffer_page *reader_page; // 独立的读者页
struct buffer_page *commit_page; // 当前提交页
unsigned long read, write; // 本CPU的读写指针
// 关键:无锁设计依赖原子变量
local_t commit_overrun; // 提交溢出计数(原子)
local_t overrun; // 覆盖计数(原子)
raw_spinlock_t lock; // 仅用于非热路径(如resize)
int cpu; // 所属CPU ID
int online; // CPU是否在线
};
这是并发处理的核心。local_t类型的原子变量是实现无锁写入的关键,它们保证了即使在多核并发写入时,对commit和entries的修改也是安全的。
2.3 buffer_page(页的元数据)
struct buffer_page {
struct list_head list; // 链入pages链表
void *page; // 指向4KB物理页
unsigned long real_end; // 页的真实结束位置
// 读者/写入者状态
local_t entries; // 本页的事件条目数(原子)
local_t commit; // 本页的提交指针(原子)
unsigned long read, write; // 本页的读写指针
};
buffer_page 是页的“控制块”,它将物理页与逻辑信息(如读写位置、条目数)关联起来。commit 原子变量尤为重要,它标记了哪些数据是已经安全提交、可供读者读取的。
2.4 ring_buffer_event(事件的紧凑表示)
struct ring_buffer_event {
u32 type_len:5, time_delta:27;
u32 array[];
};
这是一个极其精巧的设计。一个32位的前导字节承载了两种信息: type_len (5 bits):编码了事件的类型(普通事件、时间扩展、填充等)和长度信息。time_delta(27 bits):存储了与上一个事件的时间戳差值。
这种设计将事件头压缩到最小,极大地提高了缓存效率和存储密度。当 time_delta超过27位能表示的范围时,会插入一个特殊的TIME_EXTEND事件来存储完整的增量。
3.初始化与分配:一次性预分配
为了保证在NMI等上下文中也能安全写入,环形缓冲区在初始化阶段就一次性预分配好所有需要的内存页。
流程:
1.__ring_buffer_alloc():分配全局ring_buffer结构。
2.遍历所有CPU:为每个CPU调用rb_allocate_cpu_buffer()。
3.rb_allocate_cpu_buffer():
·分配ring_buffer_per_cpu结构。
·初始化自旋锁(用于冷路径)。
·循环nr_pages次,调用rb_allocate_page()分配物理页并构建循环链表。
·额外分配一个独立的reader_page。
4.rb_allocate_page():
·使用alloc_pages_node()在指定CPU的NUMA节点上分配物理页,保证局部性。
·将物理页映射到内核虚拟地址。
·分配并初始化buffer_page控制块。
这种“启动时分配,运行时零分配”的策略是NMI安全的根本保障。
4.事件写入:无锁的快车道
写入是环形缓冲区最频繁的操作,其路径被精心优化为无锁的“快车道”。
写入流程图解:

关键点:
rb_move_tail_page():当一页写满时,需要移动到下一页。这里有一个巧妙的处理:如果下一页恰好是reader_page(意味着读者正在读这页),写入者会触发一次页交换(swap),将一个干净的备用页交给读者,从而避免了写入阻塞。
原子操作:local_inc(), local_add() 等原子操作确保了commit和entries 的更新是线程安全的,无需加锁。
5.事件读取:独立的读者通道
读取操作由用户空间通过trace_pipe或trace文件触发,其路径与写入完全分离。
读取流程图解:
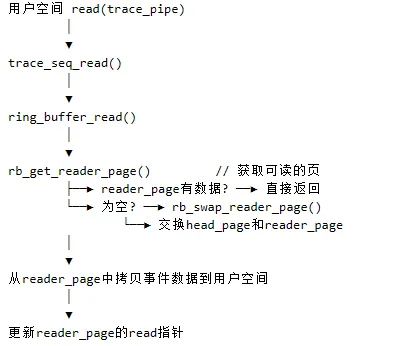
关键点: rb_swap_reader_page():这是读写解耦的核心。当 reader_page被读空后,读者会用当前缓冲区的头页(head_page)来交换它。头页是写入者最早写入、最可能已填满的页。交换后,读者可以安心地读取这个“快照”,而写入者则继续在新的尾页上工作,两者互不干扰。
6.时间戳管理:Delta编码的艺术
为了节省宝贵的缓冲区空间,环形缓冲区对时间戳进行了智能压缩。
ring_buffer_time_stamp():获取当前的绝对时间戳。
rb_add_time_stamp():计算与上一个事件的时间差 (delta)。
如果 delta <= 0x7FFFFFF (27位最大值),直接存入event->time_delta。
如果 delta 过大,则插入一个 RINGBUF_TYPE_TIME_EXTEND 类型的特殊事件,其 array[0] 存放高位部分。
这种 “常规事件存小delta,大delta用扩展事件” 的混合模式,在绝大多数情况下都能获得极高的压缩率。
7.Buffer Swap 机制:快照的魔法
ring_buffer_swap_cpu() 函数允许在两个ring_buffer实例之间交换指定 CPU的ring_buffer_per_cpu指针。
应用场景: tracing_snapshot:这是最经典的用例。系统维护一个主缓冲区和一个快照缓冲区。当用户触发快照时,内核瞬间交换两者的指针。此后,新的跟踪数据写入原来的快照区,而用户可以安全地读取原来主缓冲区中“冻结”的历史数据,实现了零停机的瞬时状态捕获。
8.性能优化总结
1.Per-CPU 隔离:彻底消除写入竞争。
2.无锁原子操作:使用local_t在快路径上避免锁。
3.预分配内存:启动时完成所有内存分配,保证运行时(尤其是NMI)的安全。
4.紧凑事件格式:5+27位的事件头极大提升缓存效率。
5.Delta时间戳:显著减少时间戳存储开销。
6.读写页分离:通过reader_page和swap机制,实现高效的无锁读取。
9.调试与观测
·内核提供了丰富的接口来观测环形缓冲区的状态:
l/sys/kernel/tracing/per_cpu/cpuX/ 目录下包含buffer_size_kb,entries,overrun等文件,可以直接查看每个CPU缓冲区的统计信息。
l启用CONFIG_RING_BUFFER_STARTUP_TEST可以在内核启动时自动运行环形缓冲区的压力测试。
l内核代码中的trace_printk等函数也可以用来在关键路径上输出调试信息。
10.总结
Linux6.6的环形缓冲区是一个集高性能、高可靠性和精巧设计于一体的杰作。它通过Per-CPU隔离、无锁原子操作、预分配、紧凑格式和读写分离 等一系列技术,成功地解决了在高并发、高实时性要求的内核环境中高效、安全地记录事件的难题。理解其内部机制,不仅有助于我们更好地使用ftrace等工具,更能从中汲取到宝贵的系统设计思想。

