大家好,我是大华!
你曾经是不是也想过,那些电商网站的价格对比网站是怎么获取数据的?招聘网站怎么整合全网的职位信息的?新闻聚合APP又是怎样抓取各大媒体的最新资讯?
答案就是——爬虫!
一、什么是爬虫?为什么要学它?
简单来说,网络爬虫(Web Scraping)就是一个自动化程序,它可以像人类一样访问网页,获取页面中的信息,并把这些信息保存下来供后续分析和使用。
假设你需要收集100家电商平台上某款手机的价格信息。如果手动一个个网站打开、复制、粘贴到Excel表格,可能需要一整天的时间。但如果用Python爬虫,可能只需要几分钟!
学习爬虫的几大理由:
- 1. 数据获取能力:互联网上有海量的公开数据,爬虫能帮你快速获取
- 3. 就业竞争力:数据分析、AI工程师等岗位都需要爬虫技能
- 4. 个人项目:做价格监控、舆情分析、内容聚合等各种有趣的项目
二、爬虫的工作原理:分为三步
爬虫的核心工作流程可以概括为三个步骤:
1. 发送请求(Request)
就像你在浏览器地址栏输入网址按下回车,爬虫程序会向目标服务器发送HTTP请求,告诉服务器"嘿,我要访问这个页面"。
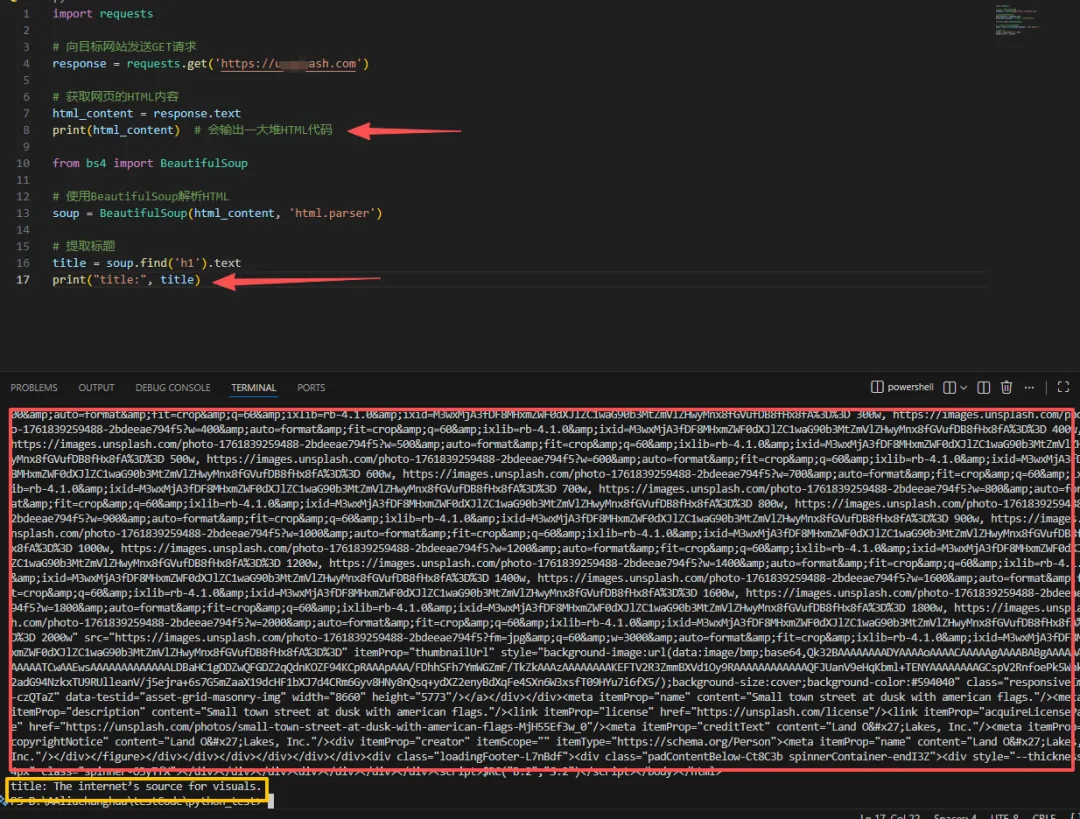
import requests# 向目标网站发送GET请求response = requests.get('https://example.com')
2. 获取响应(Response)
服务器收到请求后,会返回HTML页面内容(就是你在浏览器中看到的网页源代码)。
# 获取网页的HTML内容html_content = response.textprint(html_content) # 会输出一大堆HTML代码
3. 解析数据(Parse)
拿到HTML后,我们需要从中提取有用的信息。这就像从一本厚厚的书里找到你需要的那一段话。
from bs4 import BeautifulSoup# 使用BeautifulSoup解析HTMLsoup = BeautifulSoup(html_content, 'html.parser')# 提取标题title = soup.find('h1').textprint(title)
下面是我输出的结果
三、爬虫三剑客:必备工具库
在Python爬虫的世界里,有三个最核心的工具库,大家喜欢称它们为"爬虫三剑客":
1️⃣ Requests:HTTP请求
Requests 是Python中最流行的HTTP库,使用起来超级简单。
安装:
pip install requests
基础用法:
import requests# GET请求response = requests.get('https://api.github.com')# POST请求(比如提交表单)data = {'username': 'test', 'password': '123456'}response = requests.post('https://example.com/login', data=data)# 带参数的请求params = {'q': 'Python爬虫', 'page': 1}response = requests.get('https://example.com/search', params=params)# 查看响应状态码print(response.status_code) # 200表示成功# 获取JSON格式的响应json_data = response.json()
2️⃣ BeautifulSoup:HTML解析
BeautifulSoup 能把混乱的HTML代码变成结构化的对象,让你轻松提取想要的数据。
安装:
pip install beautifulsoup4
基础用法:
from bs4 import BeautifulSoupimport requests# 获取网页response = requests.get('https://news.ycombinator.com')soup = BeautifulSoup(response.text, 'html.parser')# 查找所有的<a>标签links = soup.find_all('a')# 查找第一个class为"title"的元素title = soup.find('span', class_='titleline')# 通过CSS选择器查找items = soup.select('.athing')# 提取文本内容text = soup.get_text()# 获取标签的属性link_url = soup.find('a')['href']
3️⃣ Selenium:动态网页
对于使用JavaScript动态加载内容的网站(比如无限滚动的页面),传统的Requests就无能为力了。这时候就需要 Selenium 出场!
Selenium能够控制真实的浏览器,模拟人类的操作。
安装:
pip install selenium
基础用法:
from selenium import webdriverfrom selenium.webdriver.common.by import By# 创建浏览器实例driver = webdriver.Chrome()# 访问网页driver.get('https://www.google.com')# 查找元素search_box = driver.find_element(By.NAME, 'q')# 输入文字search_box.send_keys('Python爬虫')# 点击按钮search_button = driver.find_element(By.NAME, 'btnK')search_button.click()# 获取页面源代码html = driver.page_source# 关闭浏览器driver.quit()
四、案例:爬取新闻标题
让我们来实现一个完整的案例,爬取Hacker News首页的新闻标题。
import requestsfrom bs4 import BeautifulSoupdef scrape_hacker_news(): """爬取Hacker News首页的新闻标题""" # 1. 发送请求 url = 'https://news.ycombinator.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36' } response = requests.get(url, headers=headers) # 2. 检查请求是否成功 if response.status_code != 200: print(f"请求失败,状态码:{response.status_code}") return # 3. 解析HTML soup = BeautifulSoup(response.text, 'html.parser') # 4. 提取新闻标题 news_items = soup.select('.titleline > a') # 5. 打印结果 print(f"成功抓取到 {len(news_items)} 条新闻:\n") for i, item in enumerate(news_items[:10], 1): title = item.get_text() link = item.get('href') print(f"{i}. {title}") print(f" 链接:{link}\n")# 运行爬虫if __name__ == '__main__': scrape_hacker_news()
输出示例:
成功抓取到 30 条新闻:1. Show HN: I built an open-source tool for web scraping 链接:https://example.com/tool2. Python 3.13 released with performance improvements 链接:https://python.org/news3. ...
五、反爬虫和应对策略
网站为了保护自己的数据,会设置各种反爬虫机制。作为爬虫工程师,我们需要了解这些机制并合理应对。
常见的反爬虫手段:
- 1. User-Agent检测:服务器检查请求头,拒绝非浏览器的请求
- 4. 动态加载:使用JavaScript动态生成内容
- 5. Cookie/Session验证:需要登录才能访问
应对策略(合法前提下):
1. 设置User-Agent
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}response = requests.get(url, headers=headers)
2. 使用代理IP
proxies = { 'http': 'http://10.10.10.10:8000', 'https': 'http://10.10.10.10:8000',}response = requests.get(url, proxies=proxies)
3. 降低请求频率
import timefor page in range(1, 11): response = requests.get(f'https://example.com/page/{page}') # 处理数据... # 每次请求后休眠2-5秒(随机时间更自然) time.sleep(random.uniform(2, 5))
4. 处理Cookie和Session
# 使用Session保持会话session = requests.Session()session.get('https://example.com/login') # 登录response = session.get('https://example.com/protected') # 访问需要登录的页面
六、爬虫的道德和法律边界
⚠️ 重要提醒: 爬虫技术本身是中性的,但使用不当可能触犯法律。
合法爬虫的黄金准则:
- 1. 遵守robots.txt协议:访问网站的
/robots.txt文件,查看哪些内容允许爬取 - 2. 控制访问频率:不要给服务器造成过大压力(DDoS攻击是违法的)
- 3. 尊重版权:爬取的数据仅供个人学习使用,不要商业化或公开发布
- 4. 不爬取敏感信息:不要爬取个人隐私、商业机密等
- 5. 遵守法律法规:了解《网络安全法》《数据安全法》等相关法律
查看robots.txt示例:
https://www.zhihu.com/robots.txthttps://www.taobao.com/robots.txt
七、进阶学习
当你掌握了基础爬虫技术后,可以继续学习:
🚀 进阶技术:
- 1. Scrapy框架:专业的爬虫框架,适合大规模爬取
- 3. 分布式爬虫:用
Scrapy-Redis实现分布式爬取 - 4. 数据存储:学习MySQL、MongoDB存储爬取的数据
- 6. 反反爬虫:学习更高级的绕过技术(如浏览器指纹、字体反爬等)
📚 学习资源推荐:
- • Requests: https://requests.readthedocs.io
- • BeautifulSoup: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- • Selenium: https://selenium-python.readthedocs.io
- • http://quotes.toscrape.com
- • http://books.toscrape.com
八、总结
通过这篇文章,我们学习了:
✅ 爬虫的基本概念和工作原理✅ Requests、BeautifulSoup、Selenium三大核心工具✅ 完整的实战案例:从请求到数据提取✅ 反爬虫机制与应对策略✅ 爬虫的法律和道德边界✅ 进阶学习的方向
记住这个学习路线:
基础语法 → Requests获取网页 → BeautifulSoup解析数据 → 处理反爬虫 → Selenium处理动态网页 → Scrapy框架 → 分布式爬虫 → 数据分析与应用
本文仅供学习交流使用,请读者在使用爬虫技术时遵守相关法律法规和网站使用协议。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
