做过临床或流行病学研究的朋友都知道,“森林图(Forest Plot)”是展示回归分析结果(如 Hazard Ratio, Odds Ratio)的绝对霸主。它能在一张图里直观地把效应值、置信区间和显著性摆得清清楚楚。但痛点在于:当你需要在一个面板里同时展示多个疾病 outcome,每个 outcome 下又要对比 Model 1、Model 2、Model 3 的敏感性分析时,普通的绘图软件(SPSS/GraphPad)往往会把图画得像“乱炖”——间距失控、对齐困难、图例抢戏。
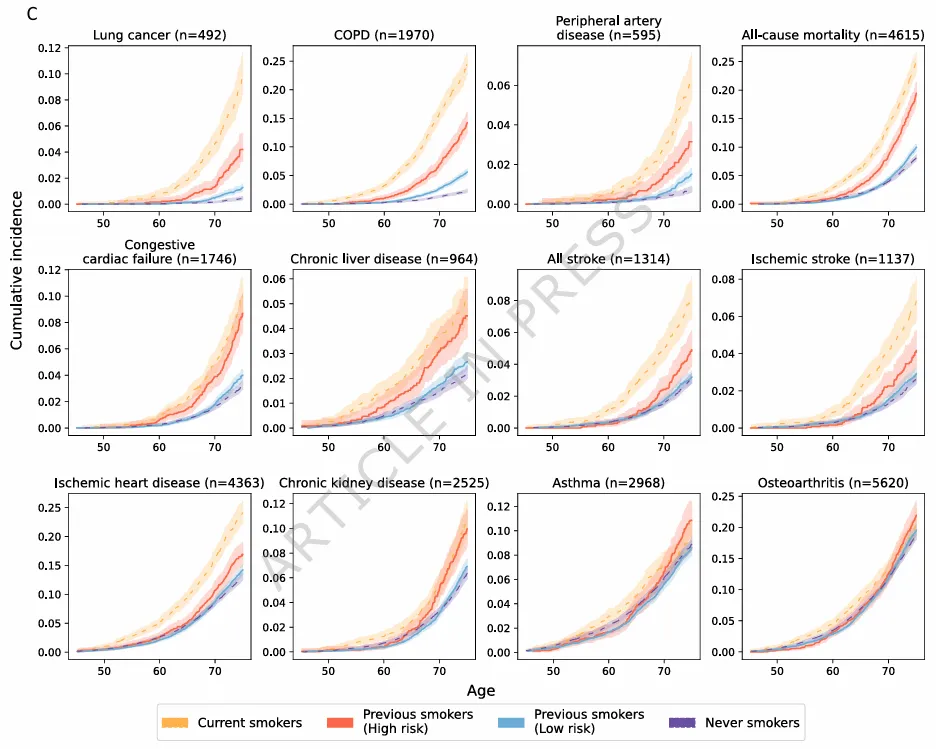
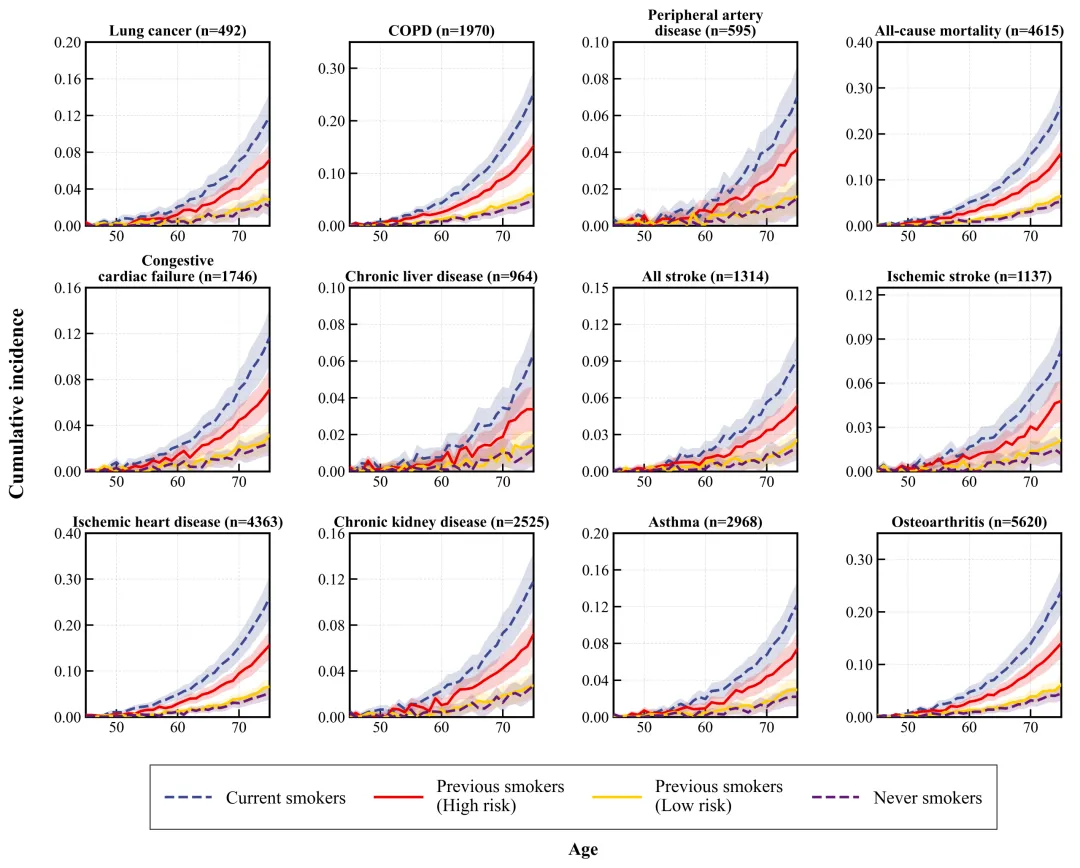
今天我们要复刻的这张来自 Nature Communications (2025) 的 Figure 4C,就是一张非常标准的多面板/分组森林图。它展示了吸烟相关的蛋白组学特征与多种疾病(肺癌、COPD、PAD等)发病风险的关联。作者非常聪明地利用了分面(Faceting)和颜色编码,清晰地展示了不同统计模型下的稳定性。
今天,我们就用 Python 的 Matplotlib,像搭积木一样,把这张图从底层逻辑到像素细节完整复现,并把每一步“为什么要这么画”讲得明明白白。拒绝手搓,我们要做的是一套“换个数据就能跑”的自动化代码。
3.1 视觉解剖 (The Anatomy)
🦴 骨架 (Structure):
这是一张水平分面(Horizontal Faceted)的图表。X轴代表 Hazard Ratio (HR) 值,Y轴虽然看起来没有刻度,但实际上隐藏了分类变量(不同的 Model)。每个子图代表一种疾病(Lung Cancer, COPD, etc.)。
🍰 核心技巧 (The Trick):
“三明治图层法”是关键。
底层:参考线(Reference Line,通常是 HR=1 的垂直虚线),必须放在最下面 (zorder=0)。
中层:误差棒(Error Bar),代表 95% CI。
顶层:散点(Scatter Point),代表 HR 点估计值。
如果顺序错了,参考线切过圆点,或者误差棒盖住了圆心,图就会显脏。
🎨 配色 (Palette):
原图使用了经典的红蓝冷暖对比色或离散分类色来区分不同的 Model。
论文原图
3.2 读懂神图 (Scientific Decoding)
别光顾着画,这图到底说了个啥?如果你看不懂图里的科学逻辑,画出来也是没有灵魂的躯壳。
这张图的核心逻辑是敏感性分析(Sensitivity Analysis)。
现象:你看每个疾病(如 Lung Cancer)下都有几行数据。通常 Model 1 只调整了年龄性别,Model 2 调整了更多混杂因素(如BMI、饮酒)。
趋势:如果从 Model 1 到 Model 3,点的位置(HR值)和误差范围(CI)没有剧烈跳变,说明结论很稳健(Robust)。
结论:作者想证明,哪怕排除掉以前吸过烟的人(Sensitivity analysis),这些蛋白标志物依然能预测疾病风险(HR 显著不为 1,且 CI 不跨过 1)。
Step 1: 全局配置
高手画图,都是先立规矩。在画任何具体图形前,先用 rcParams 统一字体和线条风格。这样可以避免在后面的绘图函数里重复写 fontsize=12 这种废话。
import matplotlib.pyplot as pltimport matplotlib.font_manager as fmimport warnings# 全局关闭非关键警告,保证绘图输出整洁,看着清爽warnings.filterwarnings('ignore')# --- 顶刊风格内核锁定 (Journal Aesthetics) ---# 字体设置:优先使用 Times New Roman,这是 SCI 的标配plt.rcParams['font.family'] = ['Times New Roman', 'Arial', 'SimHei']plt.rcParams['mathtext.fontset'] = 'stix' # 公式字体使用 STIX (类似 LaTeX)# 基础字号与线条定义:线条要粗,字要大,这就是“高级感”的来源plt.rcParams['font.size'] = 16 # 默认字号plt.rcParams['axes.linewidth'] = 1.5 # 坐标轴线宽 (Bold)plt.rcParams['lines.linewidth'] = 2.0 # 数据线宽plt.rcParams['xtick.direction'] = 'in' # 刻度朝内,更紧凑plt.rcParams['ytick.direction'] = 'in'plt.rcParams['savefig.bbox'] = 'tight' # 自动切除白边plt.rcParams['savefig.dpi'] = 600 # 印刷级分辨率
Step 2: 数据构造
为了让大家能运行,我构造了一组模拟数据,结构完全模仿原图:包含 Disease(子图分组)、Model(颜色分组)、HR(点位置)、Lower/Upper(误差棒范围)。
# --- 模拟数据生成 ---# 模拟 4 种疾病,每种疾病下有 3 个模型的结果diseases = ['Lung cancer', 'COPD', 'Peripheral artery\ndisease', 'All-cause\nmortality']models = ['Model 1', 'Model 2', 'Model 3']n_groups = len(diseases)n_models = len(models)data = []np.random.seed(42) # 固定随机种子for disease in diseases: base_hr = np.random.uniform(1.2, 2.0) # 基础风险 for i, model in enumerate(models): # 模拟不同模型的 HR 微小波动 hr = base_hr - (i * 0.1) + np.random.normal(0, 0.05) # 模拟置信区间 CI ci_width = np.random.uniform(0.1, 0.3) data.append({ 'Disease': disease, 'Model': model, 'HR': hr, 'Lower': hr - ci_width, 'Upper': hr + ci_width, 'P_val': np.random.uniform(0.001, 0.05) })df = pd.DataFrame(data)# 简单的查看数据结构,确保没有 NaNprint("📊 数据预览 (前 5 行):")print(df.head())print(f"\n总数据行数: {len(df)}")
Step 3: 画布构建与网格布局
这里我们使用 plt.subplots 来创建多面板。
# --- 画布布局 ---# 1 行 4 列,共享 Y 轴(虽然我们可能隐藏 Y 轴标签)fig, axes = plt.subplots(nrows=1, ncols=4, figsize=(14, 4), sharey=True)# 调整子图间距,避免太挤plt.subplots_adjust(wspace=0.1)# 定义配色方案 (字典映射,保证稳健)color_map = { 'Model 1': '#8DA0CB', # 浅蓝 'Model 2': '#FC8D62', # 橙红 'Model 3': '#66C2A5' # 绿}# Y轴的位置:我们手动指定位置,比如 0, 1, 2y_positions = np.arange(len(models))# 稍微倒序一下,让 Model 1 在最上面通常符合阅读习惯,或者按原图逻辑# 原图 Model 1 在上,Model 3 在下y_positions = y_positions[::-1] print("🎨 画布准备就绪,颜色映射已定义。")
Step 4: 核心绘图循环 (The Core Loop)
这是最关键的一步。我们需要遍历每个 Disease,在对应的 ax 上画线、画点。
Code Highlight: 注意 errorbar 函数的用法。
x: HR 值
y: 这里的 y 只是为了排版用的纵坐标(0, 1, 2)。
xerr: 误差棒长度。注意 Matplotlib 接受的是 [left_err, right_err] 数组,即 [HR - Lower, Upper - HR]。
# --- 循环绘图 ---for ax, disease_name in zip(axes, diseases): # 筛选当前疾病的数据 sub_df = df[df['Disease'] == disease_name] # 遍历该疾病下的每个模型 for idx, model_name in enumerate(models): row = sub_df[sub_df['Model'] == model_name].iloc[0] y_pos = y_positions[idx] # 1. 计算误差棒长度 (左臂, 右臂) xerr = [[row['HR'] - row['Lower']], [row['Upper'] - row['HR']]] # 2. 绘制误差棒 + 散点 # zorder=10 确保点在参考线上方 ax.errorbar(x=row['HR'], y=y_pos, xerr=xerr, fmt='o', # 点的形状 color=color_map[model_name], # 颜色 ecolor=color_map[model_name], # 误差棒颜色 elinewidth=2, # 误差棒线宽 capsize=4, # 误差棒帽子大小 markersize=8, # 点的大小 zorder=10, label=model_name if disease_name == diseases[0] else"") # 只在第一个子图加 Label,防止图例重复 # 3. 添加参考线 (HR=1) ax.axvline(x=1.0, color='gray', linestyle='--', linewidth=1, zorder=0) # 4. 设置标题 ax.set_title(disease_name, fontsize=11, fontweight='bold', pad=12) # 5. 设置 X 轴标签(只在底部) ax.set_xlabel('Hazard Ratio (95% CI)')print("🖊️ 核心图形绘制完成。正在进行细节修饰...")
Step 5: 注入灵魂 (Fine-tuning)
只有数据还不够,我们需要去除非数据墨水(Data-Ink Ratio),让图表“呼吸”。
Why? 默认的 matplotlib 边框是封闭的盒子。我们要把上方和右侧的脊柱(spines)去掉,这叫“Despine”,瞬间提升高级感。同时,我们要美化 Y 轴的 tick labels。
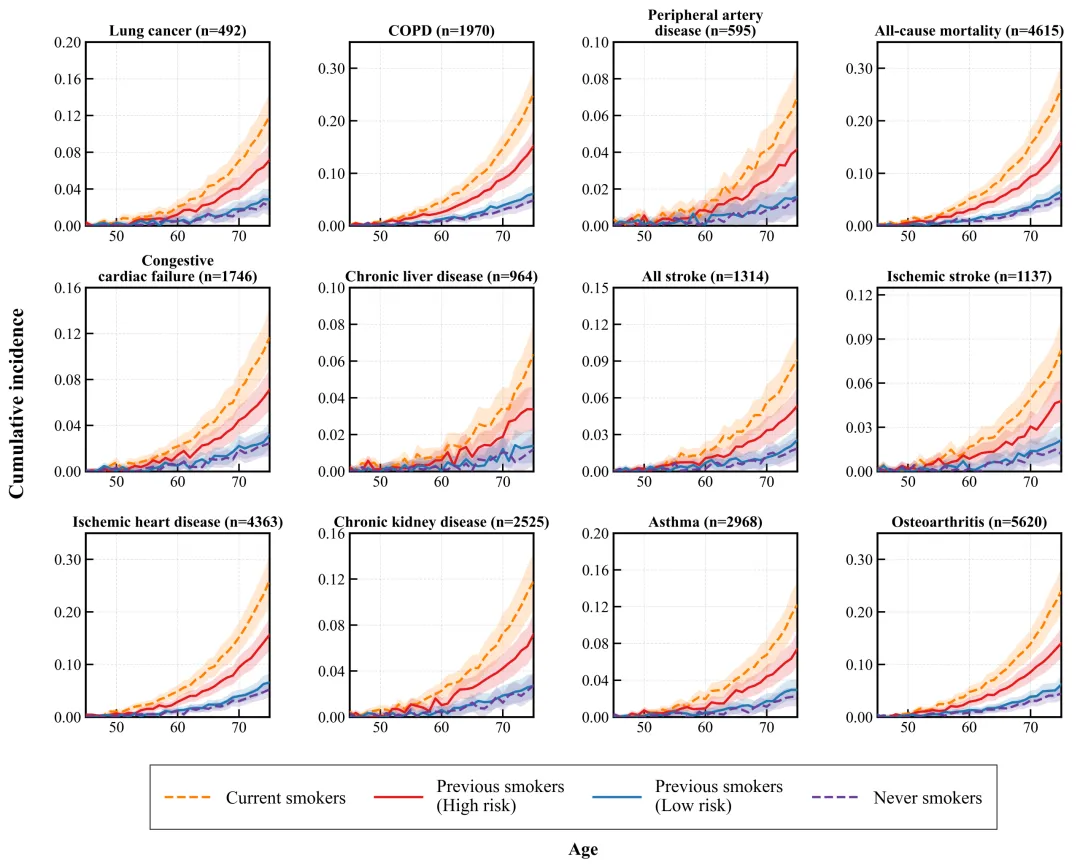
# --- 细节美化 ---for ax in axes: # 1. 去除上、右边框 ax.spines['top'].set_visible(False) ax.spines['right'].set_visible(False) # 2. Y 轴处理 # 设置 Y 刻度位置 ax.set_yticks(y_positions) # 设置 Y 刻度标签 (Model 名称) ax.set_yticklabels(models) # 3. 去除 Y 轴的刻度线 (Ticks),只保留文字 ax.tick_params(axis='y', length=0) # 4. 统一 X 轴范围 (可选,根据数据调整) # 如果数据差异大,可以不共享 X 轴;这里演示自动适应 ax.set_xlim(0.5, 2.5) # 添加图例 (只在第一个图或者单独放上面)# 这里的技巧是把图例放在整张图的上面,而不是某个子图里handles, labels = axes[0].get_legend_handles_labels()fig.legend(handles, labels, loc='upper center', bbox_to_anchor=(0.5, 1.05), ncol=3, frameon=False, fontsize=11)plt.tight_layout()# 再次调整,给图例留出空间plt.subplots_adjust(top=0.85) # 最终展示(实际运行时可保存)# plt.savefig('forest_plot_replica.png', dpi=300, bbox_inches='tight')plt.show()print("✨ 绘图完成!一张顶刊风格的森林图诞生了。")
看一眼生成的图,是不是比 SPSS 默认输出的清爽多了?
复刻图
多配色参考
👇 关注公众号【嗡嗡的Python日常】
🚫 关于源码: 本文核心代码为原创定制,暂不免费公开。
✅ 如果你需要:
购买本项目完整源码 + 数据
定制类似的科研绘图
咨询代码运行报错问题
请直接添加号主微信沟通(有偿分享☕️): Wjtaiztt0406







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
