python开源项目-支持 YouTube, Bilibili, TikTok/抖音,快手 等多个平台的视频/音频/字幕下载,ai摘要
通过视频的链接url进行数据提取与处理
我的开源项目 video-link-pipeline 这是一个集成了视频下载、音频提取、字幕处理、语音转录和 AI 摘要生成的全流程工具集。旨在帮助用户快速从各大视频平台获取内容,并利用 AI 技术进行深度处理。
✨ 主要功能
全能下载: 支持 YouTube, Bilibili, TikTok/抖音,快手 等多个平台的视频/音频/字幕下载 (基于 yt-dlp)。
- 强力反爬: 内置 Selenium 移动端模拟与反检测机制,有效应对快手等平台的反爬虫策略,自动尝试直链下载。
- Cookies 支持: 支持自动调用浏览器 Cookies (Chrome, Edge, Firefox 等) 或加载 Netscape 格式 Cookies 文件,解决会员/登录限制。
- 仅音频模式
智能转录: 使用 faster-whisper (默认) 或 openai-whisper 进行本地语音转录。
- 多模型支持: 支持 tiny 到 large-v3 各个量级的模型。
- 高性能: 支持 GPU 加速 (CUDA) 和 INT8/Float16 量化推理。
- 自动环境: 内置 FFmpeg 环境自动配置功能,无需繁琐的手动安装。
AI 摘要: 集成多种主流大模型 API,一键生成视频内容的结构化智能摘要。
- 多模型支持: Claude 3.5, GPT-4o, Gemini 1.5, DeepSeek V3, Kimi, MiniMax, 智谱 GLM-4 等。
- 结构化输出: 生成包含一句话概括、核心要点、关键语段、标签的 Markdown 报告和 JSON 数据。
字幕工具: 提供 SRT 与 VTT 字幕格式的互转工具,支持批量处理。
高度可配: 通过 config.yaml 灵活配置各项参数。
视频链接获取的数据输出截图: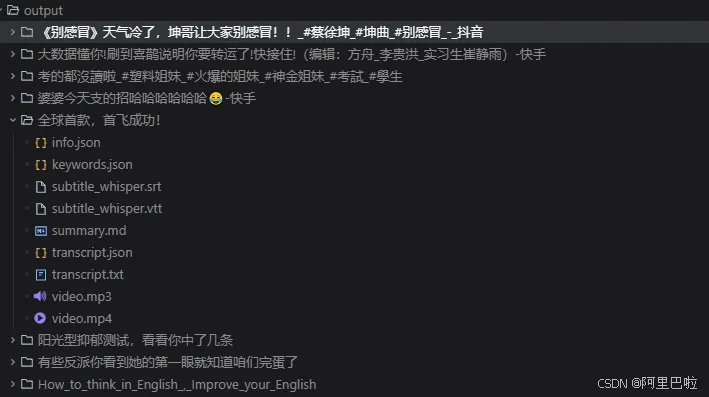
1. 攻克高难度反爬与下载限制
在数据采集层,单一的下载策略往往难以应对复杂的反爬机制。
- 混合采集策略:项目底层基于
yt-dlp,并在此之上构建了 fallback 机制。针对快手、抖音等强反爬平台,自动切换至 Selenium 驱动的无头浏览器模式。 - 设备指纹伪装:通过模拟移动端设备指纹 (User-Agent, Viewport),有效规避针对 PC 端的风控检测。
- Cookie 自动注入:实现了对本地浏览器 (Chrome, Edge) Cookie 的零配置读取,无缝解决会员鉴权与高画质下载限制。
# 移动端指纹模拟配置示例mobile_emulation ={"deviceName":"iPhone X"}chrome_options.add_experimental_option("mobileEmulation", mobile_emulation)
2. 基于 Whisper 的本地化并行转录架构
为解决隐私安全与传输效率问题,本项目采用了完全本地化的音频处理方案。
- 高性能推理引擎:整合
faster-whisper (基于 CTranslate2),支持 INT8/Float16 量化推理。在消费级显卡上,转录速度相比原版 Whisper 提升显著。 - 双引擎故障转移:设计了引擎降级机制,当
faster-whisper 初始化失败(如指令集不支持)时,自动回退至兼容性更强的 openai-whisper。 - 环境自愈能力:针对 Windows 环境下 FFmpeg 路径配置繁琐的问题,内置了环境检测与自动修复逻辑,支持动态加载
imageio-ffmpeg 二进制文件。
3. LLM 驱动的非结构化数据结构化
这是管线中最具价值的环节——将线性文本转化为结构化知识。
通过适配器模式 (Adapter Pattern) 统一接入 Claude 3.5、GPT-4o 以及 DeepSeek V3 等主流大模型,系统能够对长文本进行深层语义分析,输出标准化的 Markdown 报告:
4. 开发者友好的工程实践
在工程实现上,本项目遵循“配置即代码”与“高内聚低耦合”的原则:
- 格式互操作性:
convert_subtitle.py 模块实现了 SRT/VTT 字幕标准的双向转换,解决了不同非编软件的兼容性问题。 - 声明式配置:通过
config.yaml 集中管理模型参数、API 密钥与推理精度,支持热插拔式切换 LLM 提供商。 - 跨平台兼容:核心代码对 Windows/Linux/macOS 均做了适配处理。
快速部署
开源项目地址:https://github.com/xiexikang/video-link-pipeline
1. 环境准备
git clone https://github.com/your-repo/video-link-pipeline.gitpip install -r requirements.txt
2. 配置 (config.yaml)
whisper:model: smalldevice: cuda # 支持 cuda/cpu 自动探测summary:provider: deepseek # 灵活切换 LLM 后端api_keys:deepseek:"sk-your-api-key"
3. 执行管线
# 阶段一:数据采集 (自动处理重定向与鉴权)python download_video.py "https://www.bilibili.com/video/BVxxx"# 阶段二:音频转录 (ASR 推理)python parallel_transcribe.py -i "./output/video/video.mp4"# 阶段三:语义分析 (LLM 摘要生成)python generate_summary.py -t "./output/video/transcript.txt"

