大家平时用Linux时,肯定都用过ps命令查看进程吧?屏幕上那些R、S、D、Z字母,看着简单,却藏着进程最真实的运行状态。但很多人只知道“R是运行、S是睡眠”,却很少深究:这些状态标识,内核是怎么记录和管理的?背后到底藏着怎样的实现逻辑?其实进程状态从来不是“表面符号”,而是内核调度资源的核心依据——系统里的CPU、内存就那么多,内核得靠状态判断“哪个进程该干活、哪个该等一等”。咱们可以把Linux系统比作一个有序的工厂,进程是厂里的工人,进程状态就决定了工人此刻是在全力干活、排队等任务,还是缺材料停工。
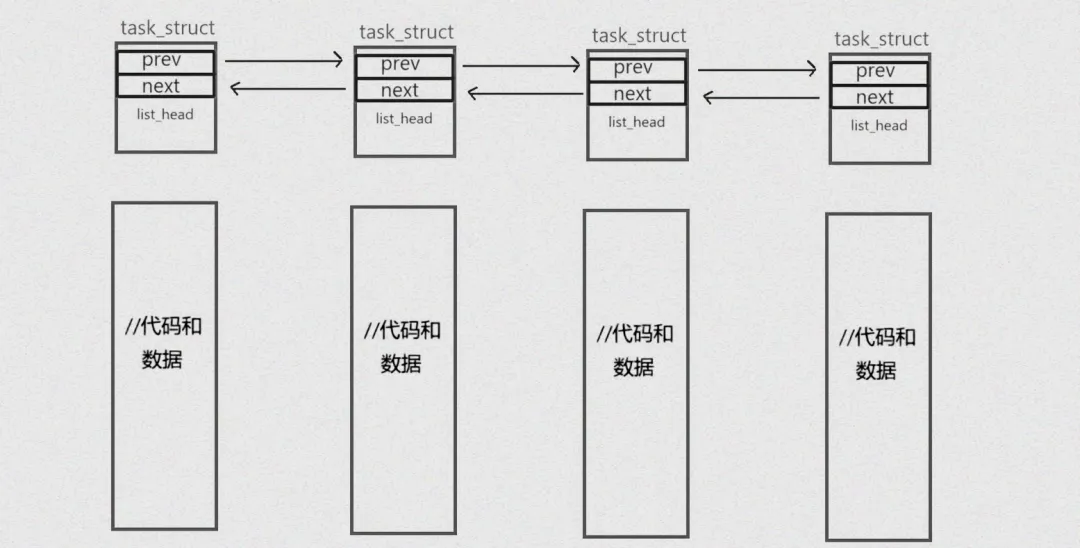
而管理这些“工人”状态的核心,就是task_struct双链表——它就像工厂的底层骨架,把所有进程紧紧连在一起,内核不管是创建、销毁进程,还是切换进程状态,都要靠它来操作。
今天咱们就跳出“表面认知”,深入内核底层,从task_struct双链表的数据结构的代码实现,到四大进程状态的切换逻辑,一步步拆解清楚,带你从“知其然”进阶到“知其所以然”,真正搞懂Linux进程管理的底层逻辑。
一、task_struct 双链表
1.1 task_struct 结构体本质
聊双链表之前,咱们先搞懂一个核心结构体——task_struct,它其实就是进程的“身份证+档案”,也就是内核里常说的进程控制块(PCB),内核能不能“感知”到一个进程,全看它有没有这个结构体。
只要有新进程创建(比如执行./a.out),内核就会分配一个task_struct,里面记录着进程的所有关键信息。咱们先看一段简化版的内核代码(真实内核代码更复杂,这里提炼核心字段,方便理解):
// 简化版task_struct结构体(内核源码路径:include/linux/sched.h)struct task_struct { pid_t pid; // 进程唯一ID,相当于身份证号 int prio; // 进程优先级,决定CPU调度顺序 volatile long state; // 进程状态,核心字段(R/S/D/Z对应的值就在这) struct list_head tasks; // 嵌入的list_head,用于双链表连接 struct list_head children; // 子进程链表,管理自己的子进程 struct list_head sibling; // 兄弟进程链表,挂靠在父进程下 // 省略其他字段(内存地址、文件描述符、信号掩码等)};
这段代码里,有两个关键点要注意:一是state字段,后面咱们讲的四大状态,本质就是修改这个字段的值;二是list_head类型的tasks、children等成员——这就是双链表的核心设计,task_struct本身不定义next/prev指针,而是靠嵌入list_head实现链表功能。
可能有粉丝会问:为什么不直接在task_struct里加next/prev指针?反而要多此一举嵌入list_head?
答案很简单:为了“通用性”和“多队列管理”。咱们可以把task_struct想象成一个豪华公寓,list_head就是公寓里的多个“通道入口”,每个入口对应一个不同的“链表队列”。这样一来,一个进程(公寓)就能同时挂靠在多个队列里,比如既在“全局进程队列”(所有进程都在),又在“就绪队列”(等待CPU),还在“父进程的子进程队列”,这就是多状态管理的基础。
而list_head的设计,更是把“通用性”做到了极致——它本身不包含任何进程相关的信息,只负责链表连接,咱们看它的内核代码:
// list_head结构体(内核源码路径:include/linux/list.h)struct list_head { struct list_head *next, *prev; // 仅两个指针,纯粹的链表节点};
就是这两个简单的指针,让list_head可以嵌入到任何结构体里,不管是task_struct,还是其他内核结构体,都能靠它实现双链表功能,这也是Linux内核设计的精妙之处。
1.2 双链表的实现精髓:list_head 与 container_of 宏
刚才咱们看了list_head的代码,它只有next/prev指针,没有任何和task_struct相关的信息——那内核遍历链表时,拿到list_head节点后,怎么找到对应的task_struct结构体呢?
这里就要用到内核里的“魔法宏”——container_of,它的作用就是“通过结构体的成员,反向找到整个结构体的地址”。咱们先看container_of的简化版代码(真实宏定义包含类型检查,这里简化核心逻辑):
// container_of宏简化版(内核源码路径:include/linux/kernel.h)#define container_of(ptr, type, member) ({ \ consttypeof(((type *)0)->member) * __mptr = (ptr); \ (type *)((char *)__mptr - offsetof(type, member)); \})
再搭配offsetof宏(计算成员在结构体中的偏移量):
#define offsetof(type, member) ((size_t)&((type *)0)->member)
可能有粉丝觉得这段宏有点绕,咱们用通俗的话解释一下,再举个实际用法。
但是问题来了,当内核通过list_head节点遍历链表时,如何才能从这个单纯的链表节点反向找到对应的完整task_struct结构体呢?这就轮到container_of宏闪亮登场了!container_of宏堪称 Linux 内核中的 “魔法钥匙”,它利用list_head结构体在task_struct结构体中的偏移量,通过一系列精妙的计算,能够反向推导出完整的task_struct结构体的地址 。
咱们还是用“大楼和房间”的比喻:task_struct是一座大楼,list_head tasks是大楼里的一个房间;offsetof宏就相当于“房间在大楼里的位置(偏移量)”,比如“3楼第5间”;container_of宏就相当于“知道房间位置,就能找到整座大楼的入口(地址)”。
举个实际的内核用法例子——内核遍历全局进程链表时,就是这么做的:
// 遍历全局进程链表(简化版,真实内核用for_each_process宏)struct list_head *pos;struct task_struct *p;// 全局进程链表头:init_task.tasks(init_task是第一个进程)list_for_each(pos, &init_task.tasks) { // 通过list_head节点pos,反向找到对应的task_struct p = container_of(pos, struct task_struct, tasks); printk("PID: %d\n", p->pid); // 打印每个进程的PID}
这段代码的核心就是container_of(pos, struct task_struct, tasks):pos是list_head节点地址,struct task_struct是目标结构体类型,tasks是list_head在task_struct里的成员名,执行后就能拿到完整的task_struct地址,从而获取进程的PID、状态等信息。
正是list_head的通用性,加上container_of宏的“反向定位”能力,才让双链表能高效管理进程——内核不用关心链表节点是什么类型,只要能拿到list_head,就能定位到进程,这也是双链表管理进程的核心精髓。
1.3 双链表的核心优势
搞懂了list_head和container_of,咱们再看双链表的核心优势——多队列协同管理。刚才咱们在task_struct的代码里看到,它有多个list_head成员,每个成员对应一个队列,这就相当于一个进程有“多个身份”,能同时加入多个队列。
咱们结合代码再梳理一下这几个关键队列,更直观:
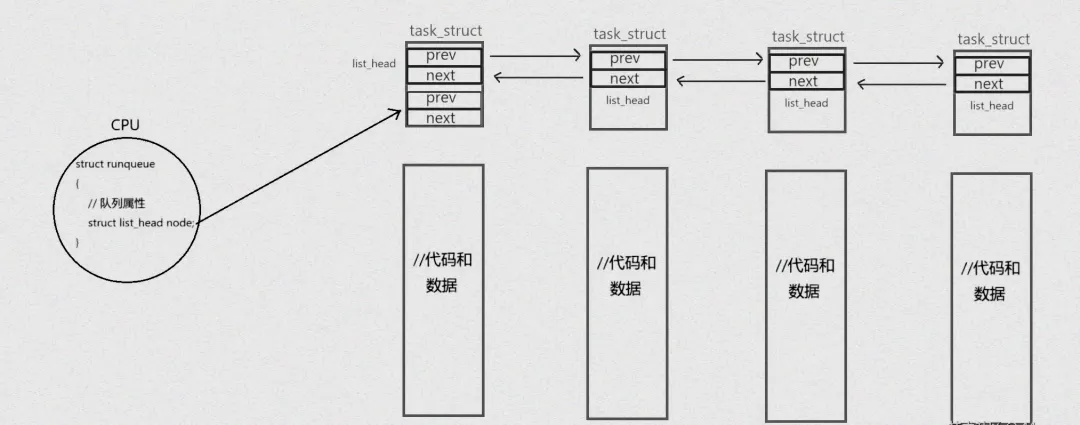
struct task_struct { // 1. 全局进程链表:所有进程都在这里,内核可全局遍历 struct list_head tasks; // 2. 运行队列:处于R态(就绪/执行)的进程在这里 struct list_head run_list; // 3. 子进程链表:当前进程的所有子进程 struct list_head children; // 4. 等待队列:处于S/D态(睡眠)的进程,挂靠在对应设备的等待队列 struct list_head wait_entry; // 其他字段...};
比如一个进程处于“就绪态”时,它的run_list会加入CPU的运行队列,tasks会加入全局进程队列,children(如果有子进程)会挂靠在父进程的子进程队列——一个进程同时存在于多个队列,却不用修改自身结构,这就是多队列管理的优势。
而内核操作这些队列,靠的就是list_add(添加节点)、list_del(删除节点)这两个核心函数,咱们看它们的简化版代码:
// 向双链表中添加节点(简化版)staticinlinevoidlist_add(struct list_head *new, struct list_head *head){ new->next = head->next; new->prev = head; head->next->prev = new; head->next = new;}// 从双链表中删除节点(简化版)staticinlinevoidlist_del(struct list_head *entry){ entry->prev->next = entry->next; entry->next->prev = entry->prev;}
这两个函数的逻辑很简单,就是标准的双链表增删操作,和task_struct完全解耦——不管是进程队列,还是其他内核结构体的队列,都能复用这两个函数,极大提升了内核代码的复用性和效率。
举个实际场景:当一个进程从S态(睡眠)唤醒,转为R态(就绪)时,内核只需要做两步操作,用代码表示就是:
// 1. 从设备等待队列中删除(退出睡眠态)list_del(&p->wait_entry);// 2. 添加到CPU运行队列(进入就绪态)list_add(&p->run_list, &cpu_runqueue.head);// 3. 修改进程状态为R态p->state = TASK_RUNNING;
整个过程不用修改进程本身的代码,只需要操作链表节点和state字段,简洁又高效——这就是双链表多队列管理的核心价值,也是Linux内核能高效调度进程的关键。
二、 四大进程状态底层原理:内核视角下的 R/S/D/Z
2.1 运行态(R)
2.1.1 状态定义与内核逻辑
讲完双链表,咱们正式拆解四大进程状态。首先是最基础的运行态(R),很多粉丝都有一个误区:以为R态就是“正在CPU上执行”,其实不是——Linux里的R态,是“就绪态+执行态”的统一体。
咱们先看内核中R态对应的state字段值(内核源码定义):
// 进程状态定义(简化版,内核源码:include/linux/sched.h)#define TASK_RUNNING 0 // 运行态(就绪/执行)#define TASK_INTERRUPTIBLE 1 // 可中断睡眠态(S)#define TASK_UNINTERRUPTIBLE 2 // 不可中断睡眠态(D)#define EXIT_ZOMBIE 4 // 僵尸态(Z)
注意看:TASK_RUNNING的值是0,它不区分“就绪”和“执行”——内核认为,只要进程具备“运行条件”(不缺资源),就是R态;至于能不能拿到CPU执行,全看调度器的安排。
内核管理R态进程的核心,就是“运行队列(runqueue)”,每个CPU都有一个独立的runqueue,咱们看它的简化版代码:
// 运行队列简化版(内核源码:include/linux/sched.h)struct runqueue { struct list_head head; // 就绪进程链表头 struct task_struct *curr; // 当前正在CPU上执行的进程 int nr_running; // 就绪进程数量 // 其他调度相关字段...};
所有R态进程,都会把自己的run_list成员,加入到某个CPU的runqueue链表中——处于“就绪”状态的进程,挂在runqueue的head链表上;处于“执行”状态的进程,就是runqueue的curr指针指向的进程。
内核调度器(比如CFS调度器)的核心工作,就是从runqueue的head链表中,挑选一个最合适的进程,把curr指针指向它,让它在CPU上执行——这个过程,就是“进程调度”。
其中,时间片机制是 Linux 进程调度的核心机制之一 。每个处于运行态的进程在被调度到 CPU 上执行时,都会被分配一个固定时长的时间片,比如 10 毫秒。在这个时间片内,进程可以尽情地使用 CPU 资源,执行自己的代码。但当时间片耗尽时,即使进程的任务还未完成,它也必须暂时从 CPU 上 “下来”,重新回到运行队列的末尾,继续等待下一次被调度的机会。这种时间片轮转的调度方式,就像一场紧张刺激的接力赛跑,每个进程都在有限的时间内奋力奔跑,然后将 CPU 资源传递给下一个进程,从而实现了多个进程在 CPU 上的并发执行,极大地提高了系统资源的利用率。
2.1.2 典型场景与状态触发
实际场景中,哪些进程会长期处于R态呢?最典型的就是CPU密集型程序,比如while(1)死循环、大规模数据计算程序——它们不缺任何资源,只要有CPU时间,就能一直执行,所以大部分时间都处于R态。
咱们写一个简单的C程序,编译执行后,用ps命令就能看到它的R态:
// test_r.c:CPU密集型程序,会长期处于R态#include<stdio.h>intmain(){ while(1) { // 空循环,持续占用CPU } return 0;}
编译执行:gcc test_r.c -o test_r&,再用ps aux | grep test_r,就能看到STAT列显示为R——这就是典型的R态进程,它会一直占用CPU,直到被终止。
而进程切换(比如“就绪→执行”“执行→就绪”),本质就是task_struct在runqueue链表中的移动,咱们用代码简化一下这个过程:
// 进程切换简化逻辑(调度器核心操作)voidschedule(void) { struct runqueue *rq = ¤t_cpu_runqueue; struct task_struct *prev = rq->curr; // 当前执行的进程 struct task_struct *next; // 下一个要执行的进程 // 1. 挑选下一个进程(根据优先级、时间片等) next = pick_next_task(rq); // 2. 如果不是同一个进程,执行切换 if (prev != next) { // 把prev放回就绪队列(如果时间片耗尽) list_add(&prev->run_list, &rq->head); // 把next从就绪队列中取出,设为当前执行进程 list_del(&next->run_list); rq->curr = next; // 3. 上下文切换(保存prev的CPU状态,恢复next的CPU状态) context_switch(prev, next); }}
这段代码虽然简化,但核心逻辑和内核一致:进程切换不是“凭空切换”,而是task_struct在runqueue链表中的“移动”,配合上下文切换,完成CPU使用权的交接。
高优先级进程的出现往往会触发运行态内部的 “就绪 - 执行” 切换 。例如,在一个实时系统中,可能会有一些对时间要求非常严格的实时任务,如航空航天系统中的飞行控制程序、医疗设备中的实时监测程序等。这些实时任务通常被赋予较高的优先级,当它们进入就绪队列时,调度器会优先将它们调度到 CPU 上执行,即使此时有其他低优先级的进程正在执行,也会被立即抢占,从而保障了高优先级任务的及时响应和执行,确保系统的稳定性和可靠性。
2.2 可中断睡眠态(S)
2.2.1 状态定义与内核逻辑
讲完R态,咱们再看最常见的状态——可中断睡眠态(S)。平时用ps命令看到的进程,大部分都是S态,比如后台运行的服务、等待用户输入的程序——它们之所以睡眠,是因为“缺资源”,主动放弃CPU,进入“浅眠”模式。
S态对应的内核状态是TASK_INTERRUPTIBLE(值为1),当进程需要等待资源时,会主动调用schedule()调度器,把自己的state设为TASK_INTERRUPTIBLE,然后加入对应设备的等待队列。咱们看简化版代码:
// 进程进入可中断睡眠态的简化逻辑voidsleep_interruptible(void) { struct task_struct *p = current; // current是当前进程指针(内核全局变量) struct wait_queue_head wait_q; // 设备等待队列头(比如键盘等待队列) // 1. 初始化等待队列(如果未初始化) init_waitqueue_head(&wait_q); // 2. 把当前进程加入等待队列 add_wait_queue(&wait_q, &p->wait_entry); // 3. 设置进程状态为S态(可中断睡眠) set_current_state(TASK_INTERRUPTIBLE); // 4. 调用调度器,放弃CPU,切换到其他进程 schedule(); // 5. 被唤醒后,从等待队列中删除 remove_wait_queue(&wait_q, &p->wait_entry);}
关键在于:S态进程会被加入“设备等待队列”(而非runqueue),同时放弃CPU,直到等待的资源就绪,或者收到外部信号,才能被唤醒。
S态的核心特点是“可中断”——哪怕资源还没就绪,只要收到外部信号(比如SIGKILL、SIGINT),进程也会被唤醒,处理信号后再决定下一步操作。
比如咱们用kill -9 PID终止一个S态进程,内核的处理逻辑简化如下:
// 信号唤醒S态进程的简化逻辑void signal_wake_up(struct task_struct *p) { // 如果进程处于可中断睡眠态,唤醒它 if (p->state == TASK_INTERRUPTIBLE) { // 1. 修改进程状态为R态 set_current_state(TASK_RUNNING); // 2. 把进程加入runqueue,等待调度 list_add(&p->run_list, ¤t_cpu_runqueue.head); // 3. 触发调度,让进程有机会执行 schedule(); }}
这也是为什么S态进程能被kill命令终止,而后面要讲的D态进程不行——因为D态进程对任何信号都不响应。
一旦进程等待的资源就绪,内核会将其task_struct从等待队列中移除,并重新加入到运行队列中,此时进程的状态也会从可中断睡眠态转为运行态,等待调度器再次将其调度到 CPU 上执行 。例如,当用户在键盘上输入数据后,键盘设备会产生一个中断信号通知内核,内核收到信号后,会将等待键盘输入的进程从键盘设备的等待队列中唤醒,使其进入运行队列,等待执行。
2.2.2 典型场景与状态触发
日常使用中,S态的场景比比皆是,最典型的就是“等待用户输入”。咱们写一个简单的程序,就能复现S态:
// 信号唤醒S态进程的简化逻辑void signal_wake_up(struct task_struct *p) { // 如果进程处于可中断睡眠态,唤醒它 if (p->state == TASK_INTERRUPTIBLE) { // 1. 修改进程状态为R态 set_current_state(TASK_RUNNING); // 2. 把进程加入runqueue,等待调度 list_add(&p->run_list, ¤t_cpu_runqueue.head); // 3. 触发调度,让进程有机会执行 schedule(); }}
编译执行:gcc test_s.c -o test_s,程序会打印“请输入内容:”,然后暂停——此时我们另开一个终端,用ps aux | grep test_s,就能看到STAT列显示为S+(+表示前台进程),这就是典型的可中断睡眠态。
又比如,当一个网络应用程序调用recv函数等待接收网络数据时,如果网络数据还未到达,进程也会进入可中断睡眠态 。在这个状态下,进程会一直等待,直到网络数据到达,或者接收到一个可以中断它的信号。
在使用ping命令测试网络连通性时,ping进程会发送 ICMP 数据包,并等待目标主机的回应 。在等待回应的过程中,ping进程就处于可中断睡眠态。如果目标主机正常响应,ping进程会收到回应数据包,从而被唤醒并继续执行;如果在等待过程中,用户按下Ctrl+C组合键发送 SIGINT 信号给ping进程,ping进程也会被唤醒,并根据信号的处理逻辑终止运行。
此外,在ps命令的输出结果中,我们经常会看到一些后台进程的状态显示为 S 。这些后台进程可能正在等待各种资源,如数据库连接、文件锁的释放等,它们都处于可中断睡眠态,随时等待资源就绪后被唤醒继续执行。
2.3 不可中断睡眠态(D):硬件交互的 “深度锁死”
2.3.1 状态定义与内核逻辑
接下来是最“特殊”的状态——不可中断睡眠态(D),也叫磁盘睡眠态。它和S态一样,都是“缺资源睡眠”,但核心区别是:D态进程对任何外部信号都不响应,相当于“深度锁死”,无法被终止。
D态对应的内核状态是TASK_UNINTERRUPTIBLE(值为2),它的核心用途是“等待硬件操作完成”,比如磁盘I/O、NFS数据读写——这些操作要求“原子性”,不能被中断,否则会导致数据损坏。
咱们看D态进程进入睡眠的简化代码,和S态很像,但有一个关键区别:
// 进程进入不可中断睡眠态的简化逻辑voidsleep_uninterruptible(void) { struct task_struct *p = current; struct wait_queue_head disk_wait_q; // 磁盘等待队列 init_waitqueue_head(&disk_wait_q); add_wait_queue(&disk_wait_q, &p->wait_entry); // 关键区别:设置为TASK_UNINTERRUPTIBLE(D态) set_current_state(TASK_UNINTERRUPTIBLE); schedule(); // 放弃CPU,进入深度睡眠 remove_wait_queue(&disk_wait_q, &p->wait_entry);}
这个代码和S态的唯一区别,就是state字段设为了TASK_UNINTERRUPTIBLE——但就是这一个区别,决定了它“不可中断”的特性。
为什么D态不能被中断?核心是为了“数据安全”。比如磁盘写入操作:进程要把100MB数据写入磁盘,写入到50MB时,如果被信号中断,磁盘上的数据就会“不完整”,导致文件损坏、文件系统出错。
所以内核规定:处于TASK_UNINTERRUPTIBLE状态的进程,即使收到SIGKILL信号(强制终止),也不会被唤醒——咱们看内核的信号处理逻辑简化版:
// 信号处理逻辑简化版voidhandle_signal(int sig) { struct task_struct *p = current; // 只有R态、S态(可中断睡眠)进程会处理信号 if (p->state == TASK_RUNNING || p->state == TASK_INTERRUPTIBLE) { // 处理信号(终止、暂停等) do_signal(sig); } else if (p->state == TASK_UNINTERRUPTIBLE) { // D态进程,忽略信号,不处理 return; }}
这就是为什么“kill -9 无法杀死D态进程”——不是kill命令没用,而是内核故意忽略了D态进程的信号,直到硬件操作完成,进程才能被唤醒。
只有当硬件设备的操作完成后,或者系统发生重启等特殊情况时,处于不可中断睡眠态的进程才会被唤醒,其task_struct会从硬件设备的等待队列中移除,进程状态也会相应地发生改变 。在等待过程中,即使使用kill -9这样的强制终止信号,也无法终止处于不可中断睡眠态的进程,因为这可能会对正在进行的硬件操作造成严重的破坏。
2.3.2 典型场景与危害
D态的场景虽然不常见,但只要涉及“底层硬件交互”,就有可能出现。最典型的就是“磁盘I/O密集型操作”,比如数据库写入、大文件拷贝。
比如我们用dd命令拷贝一个大文件(模拟大量磁盘I/O):
# 拷贝大文件,模拟磁盘I/O,可能会出现D态dd if=/dev/sda1 of=/tmp/bigfile bs=1G count=10
执行这个命令时,用ps aux | grep dd,大概率会看到STAT列显示为D——此时dd进程正在等待磁盘I/O完成,处于不可中断睡眠态,哪怕用kill -9,也无法终止它,只能等待拷贝完成,或者磁盘操作结束。
另外,数据库(比如MySQL)执行“flush logs”“sync”命令时,会把内存中的数据同步到磁盘,此时MySQL进程也可能短暂进入D态,确保数据写入完整。
然而,如果系统中出现大量进程长时间处于不可中断睡眠态,这通常是一个非常危险的信号,预示着系统可能存在严重的问题 。最常见的原因是磁盘故障,比如磁盘出现坏道、磁盘控制器故障等,导致磁盘 I/O 操作无法正常完成,进程就会一直卡在不可中断睡眠态。此外,当 NFS 服务器出现故障或者网络连接异常时,进行 NFS 数据读写的进程也会陷入不可中断睡眠态。
这种情况如果不及时处理,可能会导致整个系统的性能急剧下降,甚至出现系统挂起无法响应的情况 。因为大量进程占用着系统资源,但又无法继续执行,其他正常的进程也无法获得足够的资源来运行。而且,由于不可中断睡眠态的进程对信号不响应,常规的进程终止手段无法生效,此时往往需要优先排查硬件设备的故障,而不是从应用层去寻找问题。如果问题得不到及时解决,可能会进一步引发数据丢失等严重后果,给系统的稳定性和数据安全性带来极大的威胁。
2.4 僵尸态(Z)
2.4.1 状态定义与内核逻辑
最后一个状态,也是最“诡异”的——僵尸态(Z)。僵尸进程就像“幽灵”:进程本身已经执行完毕(代码、数据都被释放),但task_struct结构体还留在系统中,占用着PID和少量内存,无法被回收。
Z态对应的内核状态是EXIT_ZOMBIE(值为4),它的出现只有一个原因:wait()waitpid()**子进程先于父进程退出,而父进程没有调用或函数,回收子进程的资源**。
咱们先看子进程退出的简化流程,结合代码更易理解:
// 子进程退出简化流程(调用exit()函数)voidexit(int status) { struct task_struct *p = current; struct task_struct *parent = p->parent; // 父进程指针 // 1. 释放进程的代码段、数据段、堆、栈等资源 release_resources(p); // 2. 设置进程状态为僵尸态(Z) p->state = EXIT_ZOMBIE; // 3. 保存退出状态(供父进程获取) p->exit_status = status; // 4. 给父进程发送SIGCHLD信号,通知子进程退出 send_signal(parent, SIGCHLD); // 5. 调用调度器,放弃CPU(僵尸进程不再执行) schedule();}
子进程退出后,资源被释放,但task_struct没有被删除——因为它要保存“退出状态”,等待父进程来获取。
而父进程如果没有处理SIGCHLD信号,也没有调用wait()/waitpid(),子进程的task_struct就会一直保留,成为僵尸进程。咱们看父进程正确回收子进程的代码:
// 父进程回收子进程(正确写法)#include<stdio.h>#include<unistd.h>#include<sys/wait.h>intmain(){ pid_t pid = fork(); // 创建子进程 if (pid == 0) { // 子进程:执行完毕后退出 printf("子进程退出\n"); exit(0); } else if (pid > 0) { // 父进程:调用waitpid(),等待子进程退出,回收资源 int status; waitpid(pid, &status, 0); // 阻塞等待子进程退出 printf("子进程退出状态:%d\n", WEXITSTATUS(status)); } return 0;}
如果父进程删除waitpid()这一行,子进程退出后,就会变成僵尸进程——因为父进程没有回收它的task_struct。
僵尸进程只占用task_struct的内存(几十字节),少量僵尸进程影响不大,但大量僵尸进程会耗尽PID资源(系统PID是有限的,通常1-32768),导致无法创建新进程。
2.4.2 典型场景与清理方案
咱们写一个“会产生僵尸进程”的代码,方便大家实际测试:
// test_z.c:产生僵尸进程(父进程不回收子进程)#include<stdio.h>#include<unistd.h>intmain(){ pid_t pid = fork(); if (pid == 0) { // 子进程:立即退出 exit(0); } else if (pid > 0) { // 父进程:死循环,不处理子进程退出,不调用waitpid() while(1) { sleep(1); // 父进程睡眠,不做任何操作 } } return 0;}
编译执行:gcc test_z.c -o test_z&,然后用ps aux | grep test_z,就能看到子进程的STAT列显示为Z——这就是僵尸进程。此时父进程还在运行,子进程已经变成僵尸,直到父进程被终止,子进程才会被1号进程(systemd)领养并回收。
少量的僵尸进程对系统的影响通常不大,但如果系统中出现大量的僵尸进程,就会带来严重的问题 。因为每个进程在系统中都需要占用一个进程 ID(PID),而系统的 PID 资源是有限的(通常在 1 到 32768 之间)。当大量的 PID 被僵尸进程占用而无法释放时,新的进程就无法获得有效的 PID,从而导致系统无法创建新的进程,这会严重影响系统的正常运行。
清理僵尸进程的核心,就是“让父进程回收子进程资源”,常见的3种方法,结合实操命令和代码,整理如下:
# 方法1:让父进程调用wait()/waitpid()(代码层面,最根本)# 如前面的正确代码,父进程添加waitpid()调用# 方法2:杀死父进程(父进程异常时使用)kill -9 父进程PID # 杀死父进程后,僵尸子进程会被1号进程领养并回收# 方法3:重启系统(极端情况,万不得已)reboot # 重启会初始化进程表,清理所有僵尸进程
这里提醒大家:不要试图直接杀死僵尸进程(kill -9 僵尸进程PID)——僵尸进程已经没有“运行实体”,只有task_struct,kill命令对它无效,只能通过回收父进程来清理。
三、 双链表如何驱动进程状态切换?
3.1 状态切换的本质
讲完了双链表和四大状态,咱们把它们串起来——进程状态切换的底层核心,到底是什么?答案很简单:statetask_struct**不是单纯修改字段,而是在不同链表间的“队列迁徙”**。
很多粉丝误以为“状态切换就是改个state值”,其实不然——state字段只是“状态标识”,真正的切换,是内核通过链表操作,把task_struct从一个队列,移动到另一个队列,再修改state值。
咱们用一个完整的代码流程,演示“R态→S态→R态”的完整切换,把前面的知识点串起来:
// R态→S态→R态 完整切换流程(简化版)voidstate_switch_demo(void) { struct task_struct *p = current; struct wait_queue_head wait_q; // 初始状态:R态(p->state = TASK_RUNNING,在runqueue中) printk("初始状态:R态\n"); // 1. R态 → S态(可中断睡眠) init_waitqueue_head(&wait_q); add_wait_queue(&wait_q, &p->wait_entry); p->state = TASK_INTERRUPTIBLE; // 修改状态标识 list_del(&p->run_list); // 从runqueue中删除(退出R态) schedule(); // 放弃CPU,进入睡眠 // 2. S态 → R态(被唤醒后) p->state = TASK_RUNNING; // 修改状态标识 list_del(&p->wait_entry); // 从等待队列中删除(退出S态) list_add(&p->run_list, ¤t_cpu_runqueue.head); // 加入runqueue(进入R态) printk("唤醒后状态:R态\n");}
这段代码清晰地展示了状态切换的核心:链表移动(队列迁徙)+ state字段修改,两者缺一不可——没有链表移动,进程无法进入对应的调度队列;没有state字段修改,内核无法识别进程当前状态。
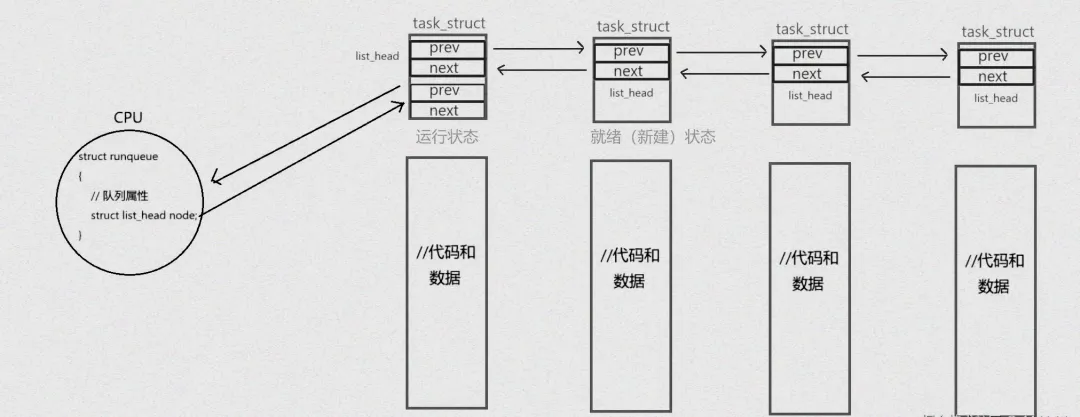
以从运行态(R)切换到可中断睡眠态(S)为例,当一个进程正在运行时,它的task_struct结构体位于 CPU 的运行队列中,就像一位舞者正在舞台上尽情表演 。但当进程需要等待某些外部资源,如等待用户从键盘输入数据时,它就会主动放弃 CPU 使用权,此时内核会将其task_struct从运行队列中移除,并将其加入到键盘设备对应的等待队列中 。这个过程就如同舞者从当前表演的舞台退下,进入到后台的等待区域,等待再次上台的机会。在这个等待队列中,进程处于可中断睡眠态,它会一直等待,直到所需的资源就绪。
反之,当进程等待的资源就绪时,比如用户在键盘上输入了数据,内核会将其task_struct从等待队列中移除,并重新加入到运行队列中 。这就像是后台等待的舞者收到了上台的信号,再次登上舞台,从可中断睡眠态切换回运行态,等待调度器将其调度到 CPU 上继续执行。
这种在不同链表间的移动,配合task_struct结构体中状态字段的更新,共同构成了进程状态切换的底层实现机制 。每一次的队列迁徙都有着明确的目的和严格的规则,确保了进程在不同状态之间的平稳过渡,使得 Linux 系统能够高效、稳定地管理众多进程的运行。
3.2 内核调度器的 “指挥棒”:时间片与优先级
内核调度器就像是Linux系统的“指挥家”,而task_struct双链表,就是它手中的“指挥棒”——调度器的所有调度操作,本质都是“操作双链表,挑选合适的进程”。
调度器的核心逻辑,就是“结合时间片和优先级,从runqueue中挑选进程”,咱们看它的核心函数简化版代码,结合前面的知识点,更容易理解:
// 调度器核心函数:挑选下一个要执行的进程struct task_struct *pick_next_task(struct runqueue *rq) { struct list_head *pos; struct task_struct *best = NULL; int highest_prio = -1; // 遍历runqueue中的所有就绪进程(R态,就绪状态) list_for_each(pos, &rq->head) { struct task_struct *p = container_of(pos, struct task_struct, run_list); // 1. 优先挑选优先级最高的进程 if (p->prio > highest_prio) { highest_prio = p->prio; best = p; } // 2. 优先级相同时,挑选时间片剩余最多的进程 else if (p->prio == highest_prio && p->time_slice > best->time_slice) { best = p; } } // 如果没有就绪进程,调度idle进程(空闲进程,PID=0) if (!best) { best = &idle_task; } return best;}
这段代码的逻辑,和Linux实际的CFS调度器(完全公平调度器)核心一致:优先级优先,时间片补充,确保高优先级进程先执行,同优先级进程公平分配CPU时间。
时间片,就像是一场接力赛跑中每个运动员的 “跑步时间配额” 。在 Linux 系统中,每个处于运行态的进程在被调度到 CPU 上执行时,都会被分配一个固定时长的时间片,例如 10 毫秒 。在这个时间片内,进程可以充分利用 CPU 资源,执行自己的代码。当时间片耗尽时,即使进程的任务还未完成,它也必须暂时从 CPU 上 “下来”,重新回到运行队列的末尾,等待下一次被调度的机会。这种时间片轮转的调度方式,确保了多个进程能够在 CPU 上实现并发执行,就像接力赛跑中每个运动员都有机会在赛道上奔跑一样。
优先级则像是运动员的 “比赛等级”,决定了他们在比赛中的起跑顺序和被关注程度 。在 Linux 系统中,每个进程都被赋予了一个优先级,优先级高的进程就像比赛中的种子选手,在竞争 CPU 资源时享有优先权 。内核调度器会优先将 CPU 资源分配给优先级高的进程,让它们先执行。例如,在一个实时系统中,一些对时间要求非常严格的实时任务,如航空航天系统中的飞行控制程序、医疗设备中的实时监测程序等,通常会被赋予较高的优先级 。这些高优先级的进程在进入就绪队列后,调度器会优先将它们调度到 CPU 上执行,即使此时有其他低优先级的进程正在执行,也会被立即抢占,从而保障了高优先级任务的及时响应和执行,确保系统的稳定性和可靠性。
内核调度器以task_struct双链表为基础,通过对时间片和优先级的精准把控,实现了对进程的高效调度 。双链表的高效遍历能力,使得调度器能够快速地在众多进程中找到优先级最高的进程,将 CPU 资源分配给它,保障了调度器的实时性和公平性。在这个过程中,时间片和优先级相互配合,就像指挥大师手中的两根指挥棒,协调着每个进程的执行顺序和执行时间,让整个 Linux 系统这个庞大的 “交响乐” 演奏得和谐有序。
四、 查看进程状态与内核痕迹的 3 个技巧
4.1 用 ps 命令快速识别四大状态
前面讲了这么多底层逻辑和代码,接下来咱们落地实操——3个最实用的技巧,帮你快速查看进程状态、定位内核痕迹,都是日常运维和学习中能直接用到的,结合命令和实际场景讲解。
第一个技巧,就是用ps命令快速识别四大状态——这是最基础、最常用的方法,咱们结合实操命令和状态解读,整理成表格,一目了然:
例如,当我们在终端中输入ps -aux命令后,会得到一个包含众多进程信息的列表,每个进程的状态标识一目了然 。如果我们看到某个进程的状态标识为R,那就意味着这个进程此刻正在运行态,它要么正在 CPU 上忙碌地执行指令,要么在就绪队列中跃跃欲试,等待着被调度到 CPU 上一展身手;若状态标识为S,则表示该进程处于可中断睡眠态,正在耐心地等待某些外部资源,如用户输入、网络数据的到来等;当状态标识为D时,说明进程正处于不可中断睡眠态,通常是在等待硬件设备的操作完成,比如磁盘 I/O 操作、NFS 数据的读写等;而Z状态则代表着进程已经进入了僵尸态,它的大部分资源已经被回收,但task_struct结构体还未被释放,需要父进程及时进行善后处理。
在实际的系统运维和故障排查中,熟练运用ps命令查看进程状态,能够帮助我们快速定位系统运行过程中出现的问题 。如果我们发现系统中有大量进程的状态为D,那就需要高度警惕,这可能是磁盘出现故障的信号,我们需要立即排查磁盘的健康状况,检查是否存在磁盘坏道、磁盘控制器故障等问题;而当系统中出现大量Z态进程时,这往往意味着程序在处理子进程退出时存在漏洞,我们需要深入检查程序代码,确保父进程能够及时调用wait或waitpid函数来回收子进程的资源,避免僵尸进程大量堆积,耗尽系统的进程表资源。
4.2 从 /proc 目录窥探 task_struct 细节
/proc目录就像是 Linux 系统中进程信息的 “宝库”,它为我们提供了一个直接窥探进程内部细节的窗口 。在这个目录下,每个进程都对应着一个以其 PID 命名的子目录,例如/proc/1234,其中1234就是进程的 PID 。在这些子目录中,status文件堪称是task_struct结构体信息的 “浓缩版”,它包含了进程的众多关键信息。
打开status文件,我们可以看到其中的State字段,它清晰地记录了进程当前的状态,与我们在ps命令中看到的STAT列的状态标识一一对应 。通过这个字段,我们可以确认进程是处于运行态、可中断睡眠态、不可中断睡眠态还是僵尸态。此外,status文件中还包含了进程的 PID、父进程 ID(PPID)、进程的优先级(Priority)等重要信息,这些信息都直接来源于task_struct结构体,是我们深入了解进程运行情况的重要依据。
除了status文件,/proc/PID目录下的stack文件也十分关键 。这个文件记录了进程当前的内核栈信息,通过分析stack文件,我们可以判断处于 S 态或 D 态的进程正在等待的资源类型。例如,如果在stack文件中发现大量与磁盘 I/O 相关的函数调用栈,那就很有可能说明该进程正在等待磁盘操作的完成,处于不可中断睡眠态;而如果调用栈中出现大量与网络套接字相关的函数,那么进程很可能是在等待网络数据的到来,处于可中断睡眠态。
4.3 用 perf 工具追踪状态切换过程
perf工具是 Linux 系统中一款强大的性能分析工具,它就像是一位技艺精湛的侦探,能够帮助我们深入追踪进程状态的切换过程 。通过perf record -e sched:sched_switch -g命令,我们可以精确地记录进程调度切换事件,从而获取进程状态切换的详细信息。
在执行上述命令后,perf工具会生成一个包含丰富信息的perf.data文件 。我们可以通过perf report命令来分析这个文件,查看进程状态切换的具体情况。在分析结果中,我们可以清晰地看到 R 态进程的 CPU 占用情况,以及进程在不同状态之间的切换频率 。这对于我们定位进程调度异常的瓶颈有着极大的帮助。
例如,如果我们发现某个进程频繁地在 R 态和 S 态之间切换,这很可能意味着该进程是一个 I/O 密集型程序,它在执行过程中需要频繁地等待 I/O 操作的完成,从而导致状态频繁切换 。在这种情况下,我们可以进一步优化程序的 I/O 操作,比如采用异步 I/O、缓存技术等,以减少状态切换的频率,提高程序的运行效率。又比如,如果某个进程在 R 态的 CPU 占用率过高,且长时间处于 R 态,这可能表明该进程存在 CPU 资源竞争的问题,我们需要检查系统中是否有其他进程与它争夺 CPU 资源,或者优化该进程的算法,降低其对 CPU 资源的消耗。
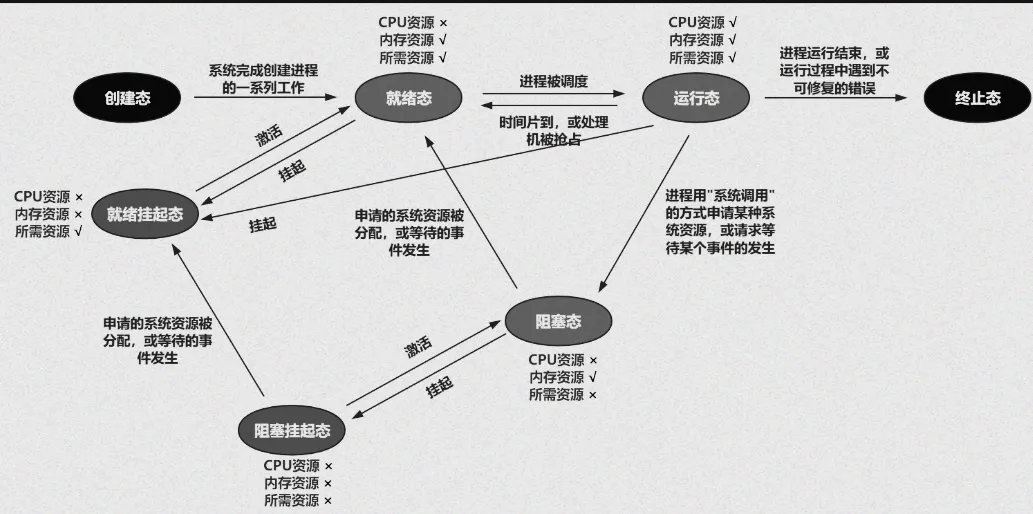
最后,附上整体流程图