明明代码逻辑没有问题,网站却总是返回反爬虫页面,你可能已经暴露在了网站的浏览器指纹检测之下。
当你用 Python 写爬虫时,是否遇到过这样的困境:设置了正确的请求头、管理了 Cookies、甚至使用了代理,目标网站依然返回“请验证你不是机器人”的页面?这很可能是因为你的请求暴露了一个关键信息——TLS 指纹。
使用普通的 Python HTTP 客户端(如 requests 或 httpx)发送请求时,即使伪装了用户代理(User-Agent),其底层的 TLS 握手特征仍与真实浏览器有明显差异,这使得反爬系统能够轻易识别出自动化程序。
一、什么是浏览器指纹?
当你的浏览器访问一个网站时,它会主动或被动地透露大量信息:用户代理字符串、接受的语言、屏幕分辨率、安装的字体、时区等。
这些信息组合起来,形成了一个几乎唯一的“指纹”,就像你的网络身份证。网站利用这个指纹来识别和跟踪用户,即使你不登录账号,也能被辨认出来。
TLS(传输层安全)指纹是浏览器指纹中较为专业的一部分。它产生于 HTTPS 连接建立时的 TLS 握手过程,包含了客户端支持的加密套件、扩展列表等信息。
不同的 HTTP 客户端和浏览器在这方面的表现各不相同,因此 TLS 指纹成为了识别自动化工具的有效手段。
二、什么是curl_cffi?
面对日益严格的反爬措施,传统的伪装手段已经不够用。这时,curl_cffi 应运而生,它是一个 Python 库,能让你发出的 HTTPS 请求看起来完全像来自指定的真实浏览器。
与 requests 或 httpx 这类纯 Python HTTP 客户端不同,curl_cffi 的核心在于它能够精确模拟浏览器的 TLS 签名和 JA3 指纹。这得益于其底层基于 curl-impersonate,这是一个专门修改了 TLS 握手行为以匹配真实浏览器的 libcurl 分支。
简单来说,curl_cffi 不只是“看起来像”浏览器,它在加密通信层面也做到了“行为像”浏览器,从而更有效地绕过基于 TLS 指纹的检测。
三、怎么安装curl_cffi?
安装 curl_cffi 非常简单,只需要一条命令。确保你的 Python 版本在 3.8 或以上,然后在终端中执行:
pip install curl_cffi --upgrade
库提供了预编译的二进制文件,在 Linux、macOS 和 Windows 上通常可以直接运行,无需手动编译复杂的底层依赖。
如果安装后导入库失败,最常见的原因是系统缺少 libcurl 的开发文件。在 Ubuntu 或 Debian 系统上,你可以通过以下命令解决:
sudo apt-get install libcurl4-openssl-dev
四、如何使用curl_cffi模仿Chrome?
curl_cffi 设计得非常易于使用,它的 API 刻意模仿了广受欢迎的 requests 库,降低了学习成本。
下面是一个最基础的使用示例,目标是访问一个能检测 TLS 指纹的测试网站:
from curl_cffi import requests# 关键:在请求时指定要模拟的浏览器response = requests.get("https://tls.browserleaks.com/json", impersonate="chrome110"# 模拟 Chrome 110 浏览器)print(response.json())
执行这段代码后,网站返回的 JSON 数据中会包含一个 ja3n_hash 字段。如果模拟成功,这个哈希值将与真实的 Chrome 110 浏览器完全一致。
impersonate 参数是 curl_cffi 的灵魂。除了具体的版本(如 chrome110),你也可以直接使用 "chrome" 来模拟最新版本的 Chrome 浏览器。
五、如何使用curl_cffi应对复杂场景?
除了简单的 GET 请求,curl_cffi 也能处理复杂的网络交互场景。
管理会话和Cookies:与 requests 库一样,你可以使用 Session 对象来保持跨请求的 Cookies 和某些设置。
from curl_cffi import requestssession = requests.Session()# 第一个请求设置 Cookiesession.get("https://httpbin.org/cookies/set/session_id/abc123", impersonate="chrome")# 第二个请求会自动携带上 Cookier = session.get("https://httpbin.org/cookies", impersonate="chrome")print(r.json()) # 输出:{'cookies': {'session_id': 'abc123'}}
发送POST请求与自定义头:处理登录表单或 API 交互时,你可能需要发送 POST 请求。
payload = {'username': 'test', 'password': 'secret'}headers = {'X-Custom-Header': 'MyValue'}response = requests.post("https://httpbin.org/post", data=payload, headers=headers, impersonate="chrome")
异步请求提升效率:当需要大量抓取时,同步请求会成为瓶颈。curl_cffi 支持异步操作,能显著提高效率。
import asynciofrom curl_cffi.requests import AsyncSessionasyncdefmain(): urls = ["https://example.com/1", "https://example.com/2"]asyncwith AsyncSession() as session: tasks = [session.get(url, impersonate="chrome") for url in urls] results = await asyncio.gather(*tasks) # 并发执行所有请求for r in results:print(r.status_code)asyncio.run(main())
六、使用curl_cffi突破Walmart反爬
理论需要实践验证。以抓取 Walmart(沃尔玛)商品搜索页面为例,使用普通 requests 库通常会立即触发反爬机制,返回验证页面。
而使用 curl_cffi,配合 HTML 解析库 BeautifulSoup,可以轻松获取真实数据:
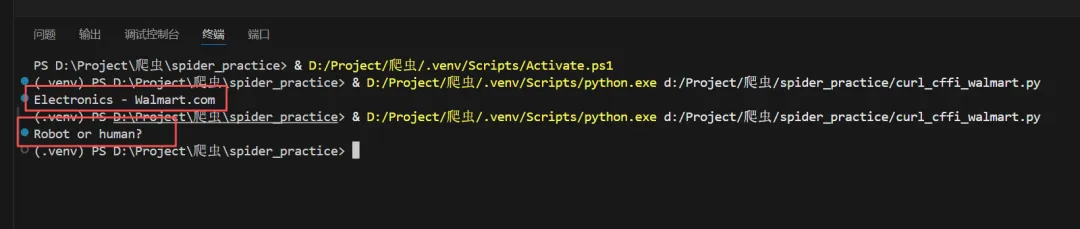
from curl_cffi import requestsfrom bs4 import BeautifulSoup# 关键步骤:请求时模拟 Chrome 浏览器response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome"# 模拟最新版Chrome)# 如果此处移除 impersonate 参数,通常会得到反爬页面soup = BeautifulSoup(response.text, "html.parser")title = soup.find("title").textprint(title) # 成功输出:Electronics - Walmart.com
这个案例清晰地展示了 impersonate 参数的决定性作用。同样的代码,不加该参数,返回的标题很可能是 “Robot or human?” 这类反爬提示。
curl_cffi 支持模拟多种浏览器和版本,包括不同版本的 Chrome、Edge、Safari 及其移动端变体。例如 safari15_5、edge101、chrome99_android 等都是有效的参数值。
在网站技术检测手段不断升级的今天,curl_cffi 让 Python 自动化脚本在网络世界中更隐蔽、更高效地运行,它模拟的不仅是浏览器的外表,更是其与网站服务器进行加密对话的“声音”和“习惯”。
学习资源与代码库
掌握 curl_cffi 的最佳方式是结合文档与实战。以下是精心整理的学习资源,助你从入门到精通:
官方核心资源
- 项目主页与文档:访问 curl-cffi GitHub[1] 获取最权威的安装说明、API文档和更新动态。PyPI页面有版本历史。
- 底层依赖:了解其强大能力的根源 curl-impersonate[2],它修改了curl的TLS行为以精确匹配浏览器。
- 指纹测试工具:在 tls.browserleaks.com/json[3] 上验证你的请求TLS指纹是否模拟成功。
引用链接
[1]curl-cffi GitHub: https://github.com/yifeikong/curl-cffi
[2]curl-impersonate: https://github.com/lwthiker/curl-impersonate
[3]tls.browserleaks.com/json: https://tls.browserleaks.com/json
[4]python_spider: https://gitee.com/fengde_jijie/python_spider