服务器负载高?一篇文章教你全面排查与优化
服务器负载突然升高?CPU、内存、磁盘I/O飙升?别慌,本文为你提供一套完整的排查思路和实用命令,助你快速定位问题并解决。
预备知识:常用命令安装方法
在开始排查前,确保你已经安装了必要的工具。以下是常用命令的安装方法:
Debian/Ubuntu系统
apt update && apt install -y \ sysstat \ iotop \ htop \ smartmontools \ perf-tools \ dstat \ tcpdump
CentOS/RHEL系统
yum install -y \ sysstat \ iotop \ htop \ smartmontools \ perf \ dstat \ tcpdump
其他工具安装
valgrind:用于内存泄漏检测
# Debian/Ubuntuapt install valgrind# CentOS/RHELyum install valgrind
pmap:用于进程内存映射分析
# 通常已包含在procps包中# 若未安装apt install procps # Debian/Ubuntuyum install procps-ng # CentOS/RHEL
一、确认负载高的问题类型
查看当前负载
uptime # 显示1/5/15分钟负载平均值top # 查看实时负载(Load Average行)及CPU使用率
负载值的合理范围:
- 警告范围:5分钟负载 > CPU逻辑核心数但 < 2倍核心数
若持续高于核心数,需深入排查。
查看CPU整体使用率
top # 按`1`显示多核CPU详情,观察us(用户态)、sy(内核态)、wa(I/O等待)等指标vmstat 1 # 查看上下文切换(cs)、中断(in)等
关键指标解读:
定位高CPU进程
分析进程内线程
top -Hp [PID] # 查看指定进程的线程CPU占用printf"%x\n" [TID] # 将线程ID转为16进制(用于后续分析)
深入分析代码热点
perf top -p [PID] # 查看进程的函数级CPU消耗(需安装perf)strace -p [PID] # 跟踪系统调用(排查频繁调用)
检查I/O瓶颈
查看磁盘I/O负载
iostat -x 1 # 观察%util(设备利用率)、await(I/O等待时间)iotop # 按进程查看磁盘I/O使用
关键指标解读:
检查文件系统状态
df -h # 查看磁盘空间是否耗尽dmesg | grep -i error# 检查磁盘错误日志
内存与Swap分析
查看内存使用
free -h # 查看物理内存和Swap使用top # 按`M`排序内存占用进程
关键指标解读:
检查僵尸进程
ps -A -ostat,ppid,pid,cmd | grep -e '^[Zz]'# 列出僵尸进程
处理方法:僵尸进程需终止其父进程(通过kill -9 [PPID],大部分情况下僵尸进程事杀不掉的)。
检查异常进程
ps aux | grep [可疑进程名]lsof -p [PID] # 查看进程打开的文件和网络连接
网络瓶颈排查
查看网络流量
sar -n DEV 1 # 实时监控网络接口流量netstat -antp # 查看TCP连接状态tcpdump -i eth0 -n port 80 # 抓包分析网络流量(示例端口80)
网络指标正常范围:
其他工具
sar(历史数据分析)
sar -q # 查看历史负载趋势sar -u # 查看历史CPU使用率sar -d # 查看历史磁盘I/O
系统日志
journalctl -f # 实时查看系统日志cat /var/log/messages | grep -i errorcat /var/log/syslog | grep -i memory # 检查内存相关日志
二、磁盘I/O问题深度分析
查看磁盘状态
iostat -xd 2
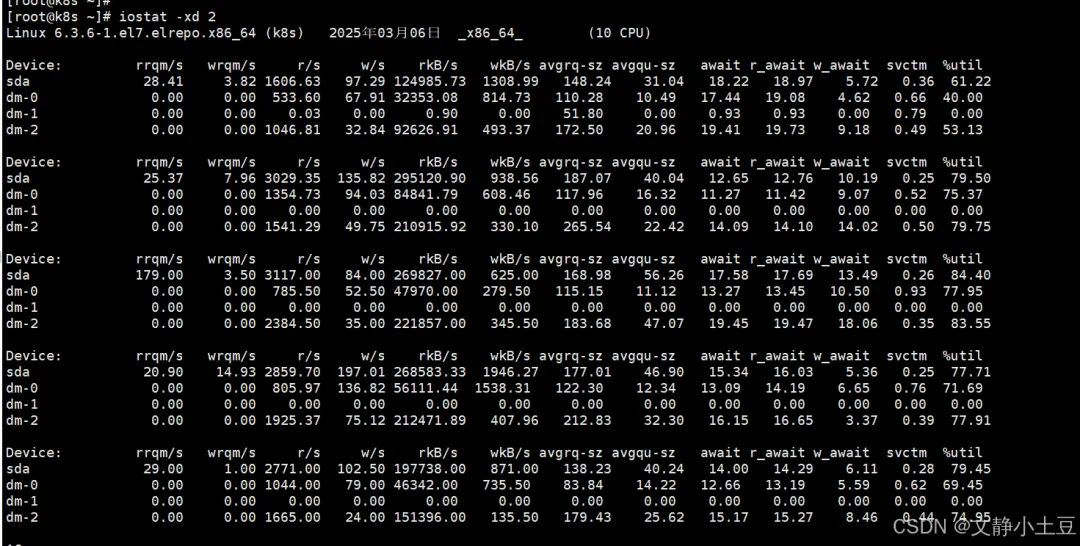
示例输出分析:
- sda 磁盘:%util 首次采样达 63.03%,后续波动在 12.45%~29.80%,但最后一次采样中 dm-0 的 %util 达 100%。
- 读写吞吐:首次采样 rkB/s=126,551.57(约 123.6 MB/s),说明大量读操作。
- 队列积压:avgqu-sz 首次采样为 31.26(高队列积压),await 首次达 18ms(I/O延迟较高)。
高I/O负载设备分析
- dm-0:首次采样 rkB/s=32,555.22(约 31.8 MB/s),%util=40.64%。
- dm-2:首次采样 rkB/s=93,990.45(约 91.8 MB/s),%util=54.94%,读写请求密集。
问题定位
- I/O瓶颈:%util 多次超过 70%(如 dm-0 达 100%),表明磁盘已饱和,请求排队严重。
- 高读操作:rkB/s 和 r/s 显著偏高,可能是频繁读取大文件或数据库全表扫描导致。
排查步骤
1. 定位高I/O进程
# 方法1:使用iotopiotop -o # 显示活跃I/O进程# 方法2:使用pidstatpidstat -d 1 # 按进程统计I/O# 方法3:使用ps结合IO统计ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu | head -20
重点观察:DISK READ 和 DISK WRITE 列,定位占用高的进程。
2. 检查文件系统和磁盘空间
# 检查磁盘空间df -h # 确认磁盘空间是否耗尽# 检查磁盘错误日志dmesg | grep -i error# 检查inode使用情况df -i # 确认inode是否耗尽
注意:若磁盘空间不足或存在坏道,会导致I/O性能骤降。
3. 分析文件访问模式
- 大文件读写:若进程频繁读写大文件(如日志、数据库文件),需优化文件切分或归档策略。
- 小文件频繁操作:大量小文件读写(如Web静态资源)需考虑合并或使用缓存(如Redis)。
4. 磁盘健康检查
# 使用smartctl检测磁盘健康smartctl -a /dev/sda# 检查磁盘坏道badblocks -v /dev/sda
5. 文件系统性能分析
# 查看文件系统类型df -T# 检查文件系统碎片e2fsck -n -f /dev/sda1 # 仅检查,不修复
三、CPU使用率异常分析
关键指标分析
- 运行队列(
r列):多次超过 50(如 r=88),远超CPU核心数(10核),说明进程排队严重。 - 等待I/O的进程(
b列):最高达 44,表明大量进程因I/O阻塞。
- 用户态(
us):较低(3%~15%),排除用户进程直接占用CPU的可能。 - 系统态(
sy):多次超过 70%(如 sy=74%),内核处理I/O或锁竞争导致。 - I/O等待(
wa):最高达 56%,确认磁盘是瓶颈。
- 块设备读(
bi):最高达 377,968 块/秒(约 147.5 MB/s),远超机械盘吞吐能力。 - 上下文切换(
cs):高达 28,553次/秒,频繁进程切换加剧CPU压力。
- 空闲内存(
free):波动大(最低 139 MB),但 cache 较高(约 800 MB~1 GB),系统利用缓存缓解I/O压力。 - 无Swap使用(
si/so=0):内存未耗尽,但缓存频繁刷写可能影响性能。
排查步骤
1. 定位高I/O进程
# 查看实时I/O读写进程iotop -o -P# 按进程统计I/Opidstat -d 1
示例关注:
- DISK READ 列高(如 MySQL、日志服务)。
- 进程状态:若多为
D(不可中断睡眠),表明等待磁盘I/O。
2. 检查磁盘健康
# 检查磁盘SMART状态smartctl -a /dev/sda# 查看磁盘错误日志dmesg | grep -i error
注意:若发现坏道或高延迟,需更换磁盘。
3. 分析文件访问
# 查看进程打开的文件lsof -p <PID># 跟踪文件操作strace -p <PID> -e trace=file# 查看进程文件描述符使用ls -la /proc/<PID>/fd | wc -l
确认:是否为 大文件顺序读 或 小文件随机读,优化访问模式。
4. 检查内存缓存
# 查看缓存和缓冲区使用free -m# 监控内存压力sar -r 1# 查看内存使用详情cat /proc/meminfo
注意:若 cache 频繁释放,表明内存不足,需优化应用内存或扩容。
四、内存使用异常分析
关键指标分析
- 已用内存(
used):14G,占比 **93%**,接近物理内存上限。 - 可用内存(
available):600MB,表明系统处于内存紧张状态,可能触发 OOM Killer。 - 缓存/缓冲区(
buff/cache):911MB,较低,说明系统未有效利用缓存缓解I/O压力。
- OOM Killer:若突发内存需求,内核会强制终止进程释放内存(参考
/var/log/messages 中的 Out of memory 日志)。 - 性能下降:频繁内存回收导致CPU占用升高(如
kswapd 进程活跃)。
排查步骤
1. 定位高内存进程
# 方法1:使用top.top -o %MEM # 按内存占用排序# 方法2:使用psps aux --sort=-%mem | head -n 10 # 列出前10内存消耗进程# 方法3:使用pmappmap -x [PID] # 查看进程内存映射
重点关注:
- %MEM 列:持续高占比的进程(如 MySQL、Java 应用)。
- 进程状态:若为
D(不可中断睡眠)或 Z(僵尸进程),可能关联资源泄漏。
2. 检查内存泄漏
# 方法1:使用valgrind检测特定程序内存泄漏valgrind --leak-check=full -v [应用程序路径]# 方法2:监控进程内存增长趋势watch -n 1 "cat /proc/[PID]/status | grep VmRSS"# 方法3:使用memleak工具perf memleak -p [PID]
注意:若进程内存持续增长且无释放,需重启服务或修复代码。
3. 分析内存使用详情
# 查看进程内存使用详情cat /proc/[PID]/smaps | grep -A 10 -B 2 "Rss"# 查看系统内存使用详情vmstat -s
五、优化建议
系统层调优
1. I/O调度器优化
# 查看当前调度器tcat /sys/block/sda/queue/scheduler# 改为deadline(适用于机械盘)echo deadline > /sys/block/sda/queue/scheduler# 改为noop(适用于SSD)echo noop > /sys/block/sda/queue/scheduler
2. 内核参数调优
# 增大磁盘队列深度echo 1024 > /sys/block/sda/queue/nr_requests# 调整内存回收策略sysctl -w vm.swappiness=10 # 减少Swap使用sysctl -w vm.dirty_background_ratio=5 # 脏页背景刷写比例sysctl -w vm.dirty_ratio=10 # 脏页最大比例
3. 文件系统优化
# 对于ext4文件系统,启用丢弃功能(SSD适用)mount -o discard /dev/sda1 /mnt# 优化inode大小和块大小mkfs.ext4 -i 8192 -b 4096 /dev/sda1
应用层调优
1. MySQL优化
# 调整缓冲区大小innodb_buffer_pool_size = 8G # 根据内存情况调整# 优化查询缓存query_cache_size = 64M# 调整日志缓冲区innodb_log_buffer_size = 16M# 优化连接数max_connections = 200
2. 应用内存优化
- Java应用:调整JVM参数,如
-Xmx、-Xms、-XX:MaxMetaspaceSize 等。 - Python应用:使用内存分析工具如
memory_profiler 检测内存使用情况。 - PHP应用:调整
php-fpm 的 pm.max_children、pm.start_servers 等参数。
监控与告警
1. 建立监控系统
# 安装Prometheus和Grafanawget https://github.com/prometheus/prometheus/releases/download/v2.40.0/prometheus-2.40.0.linux-amd64.tar.gztar -xzf prometheus-2.40.0.linux-amd64.tar.gz# 安装Node Exporterwget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gztar -xzf node_exporter-1.3.1.linux-amd64.tar.gz
2. 设置告警规则
六、案例总结
负载高的原因
- I/O密集型负载:大量读操作(
bi高)导致磁盘饱和,进程因等待I/O堆积(b列高),引发高负载和系统态CPU占用。 - 可能的场景:数据库全表扫描、日志文件未轮转、文件系统元数据操作频繁(如小文件读写)。
- 内存不足:物理内存耗尽(15G中已用14G),主要嫌疑为 MySQL配置不当或 应用内存泄漏。
解决思路
- 代码优化:修复内存泄漏、优化查询语句、减少I/O操作。
CSDN 账号:https://blog.csdn.net/qq_39965541

