Linux内核由哪些组成,这些你了解不?
- 2026-06-24 09:00:57
提到 Linux,很多人会想到它的开源、稳定,却少有人深究支撑这一切的 “灵魂”—— 内核。作为操作系统的核心,Linux 内核就像一台精密机器的 “中枢神经”,既要管理硬件资源,又要协调进程调度、内存分配,还要处理网络通信、文件系统交互,每一环都决定着系统的性能与稳定性。可对多数开发者来说,内核架构总带着 “高深莫测” 的滤镜:它的底层原理如何运作?进程、内存、文件这三大核心子系统是怎样协作的?不同模块间又存在怎样的逻辑关联?这些问题往往成为深入 Linux 开发的 “拦路虎”。
今天这篇目录导读文章,我们就抛开复杂的代码细节,从内核的核心原理入手,一步步拆解它的架构逻辑:先讲清内核如何充当硬件与应用的 “中间桥梁”,再聚焦进程管理、内存调度、文件系统、网络协议栈等核心模块,用通俗的比喻和清晰的逻辑,帮你看懂内核的 “五脏六腑”。无论你是刚接触 Linux 的新手,还是想夯实底层基础的开发者,读完这篇,都能对 Linux 内核架构建立起清晰的认知框架。
一,什么是Linux内核?
1.1 内核是什么
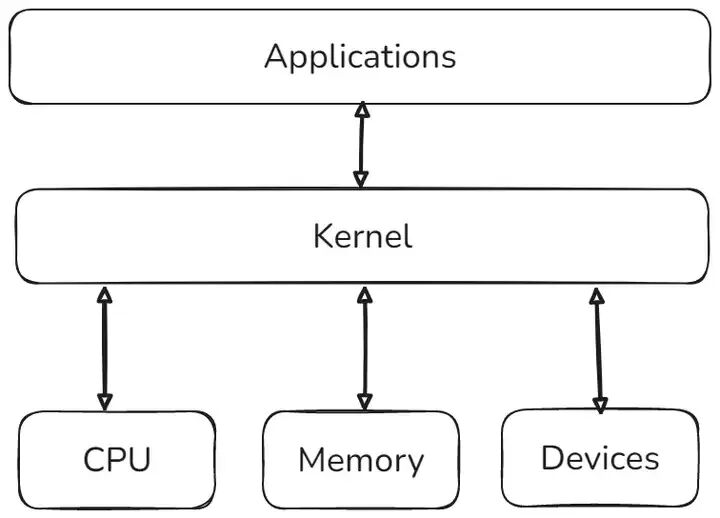
Linux内核是一个操作系统(OS)内核,本质上定义为类Unix。它用于不同的操作系统,主要是以不同的Linux发行版的形式。Linux内核是第一个真正完整且突出的免费和开源软件示例。Linux 内核是第一个真正完整且突出的免费和开源软件示例,促使其广泛采用并得到了数千名开发人员的贡献。在操作系统的世界里,Linux 内核堪称是最为关键的角色,它就像计算机系统的 “大管家”,处于硬件与软件的交汇点,肩负着多重重要使命 。从本质上来说,Linux 内核是一段运行在最高特权级别的特殊程序,它牢牢掌控着计算机的硬件资源,为上层的应用程序提供稳定、高效的运行环境。
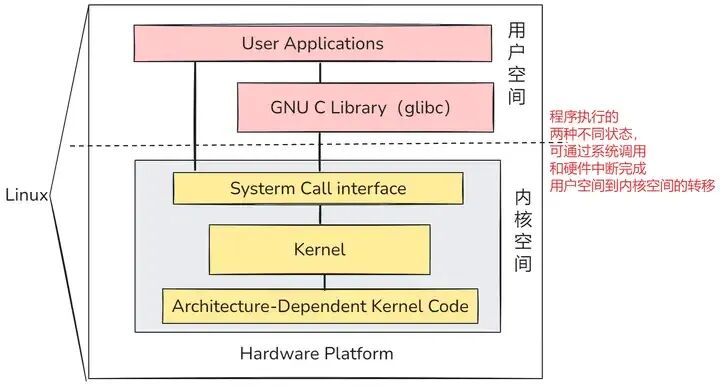
顶部是用户(或应用程序)空间。这是用户应用程序执行的地方。用户空间下面是内核空间,Linux内核就位于这里。GNU C库(glibc)也在这里。它为内核提供了一个系统调用接口,也为用户空间应用程序和内核之间的转换提供了一个机制。这非常重要,因为内核和用户空间应用程序使用不同的受保护地址空间。每个用户空间进程使用自己的虚拟地址空间,而内核占用一个单独的地址空间。
Linux内核可以进一步分为3层。最上面是系统调用接口,实现一些基本功能,比如读写。系统调用接口下面是内核代码,可以更准确的定义为独立于架构的内核代码。这些代码对于Linux支持的所有处理器架构都是通用的。在这些代码下面是依赖于架构的代码,它构成了通常称为BSP(板支持包)的部分。这些代码用作给定架构的处理器和平台特定代码。
Linux内核实现了许多重要的架构属性。在更高或更低的层次上,内核被分成几个子系统。Linux也可以看做一个整体,因为它会把这些基础服务都集成到内核中。这与微内核的架构不同,微内核提供一些基本的服务,比如通信、I/O、内存、进程管理等。更具体的服务被插入到微内核层中。每个内核都有自己的优点,但这里不讨论这个。随着时间的推移,Linux内核在内存和CPU使用上的效率很高,非常稳定。但对于Linux来说,最有意思的是,在这个规模和复杂度的前提下,它仍然具有良好的可移植性。经过编译后,Linux可以在大量具有不同架构约束和要求的处理器和平台上运行。例如,Linux可以运行在带有内存管理单元(MMU)的处理器上,也可以运行在不提供MMU的处理器上。linux内核的UClinux移植提供了对非MMU的支持。
简单来说,Linux 内核就是连接硬件与软件的桥梁,它不仅负责管理计算机的硬件资源,包括 CPU、内存、磁盘 I/O 等,还提供了一系列的系统服务,如进程管理、文件系统管理、网络通信等,是整个 Linux 操作系统的核心所在。
1.2 Linux内核源代码的目录结构
核心目录结构三个主要部分:
内核核心代码,包括第3章所描述的各个子系统和子模块,以及其它的支撑子系统,例如电源管理、Linux初始化等 其它非核心代码,例如库文件(因为Linux内核是一个自包含的内核,即内核不依赖其它的任何软件,自己就可以编译通过)、固件集合、KVM(虚拟机技术)等 编译脚本、配置文件、帮助文档、版权说明等辅助性文件使用ls命令看到的内核源代码的顶层目录结构,具体描述如下。include/ ---- 内核头文件,需要提供给外部模块(例如用户空间代码)使用。
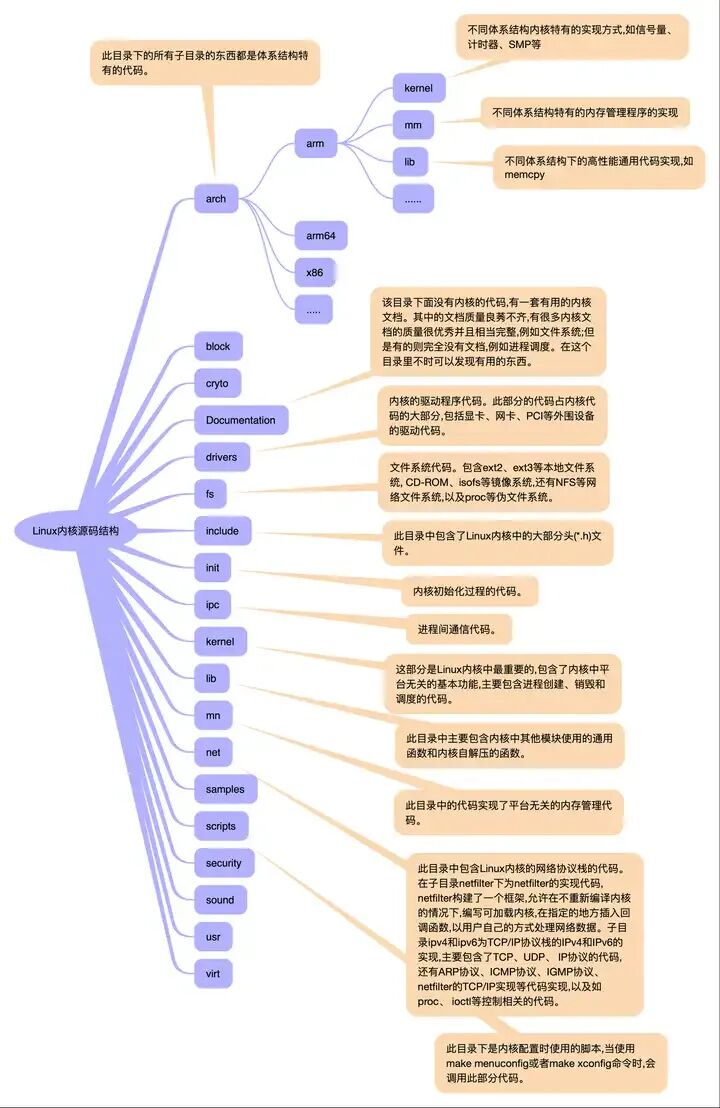
kernel/ ---- Linux内核的核心代码,包含了3.2小节所描述的进程调度子系统,以及和进程调度相关的模块 mm/ ---- 内存管理子系统(3.3小节)。 fs/ ---- VFS子系统(3.4小节)。 net/ ---- 不包括网络设备驱动的网络子系统(3.5小节)。 ipc/ ---- IPC(进程间通信)子系统。 arch// ---- 体系结构相关的代码,例如arm, x86等等。 arch//mach- ---- 具体的machine/board相关的代码。 arch//include/asm ---- 体系结构相关的头文件。 arch//boot/dts ---- 设备树(Device Tree)文件。 init/ ---- Linux系统启动初始化相关的代码。 block/ ---- 提供块设备的层次。 sound/ ---- 音频相关的驱动及子系统,可以看作“音频子系统”。 drivers/ ---- 设备驱动(在Linux kernel 3.10中,设备驱动占了49.4的代码量)。 lib/ ---- 实现需要在内核中使用的库函数,例如CRC、FIFO、list、MD5等。 crypto/ ----- 加密、解密相关的库函数。 security/ ---- 提供安全特性(SELinux)。 virt/ ---- 提供虚拟机技术(KVM等)的支持。 usr/ ---- 用于生成initramfs的代码。 firmware/ ---- 保存用于驱动第三方设备的固件。 samples/ ---- 一些示例代码。 tools/ ---- 一些常用工具,如性能剖析、自测试等。 Kconfig, Kbuild, Makefile, scripts/ ---- 用于内核编译的配置文件、脚本等。 COPYING ---- 版权声明。 MAINTAINERS ----维护者名单。 CREDITS ---- Linux主要的贡献者名单。 REPORTING-BUGS ---- Bug上报的指南。 Documentation, README ---- 帮助、说明文档。
1.3为什么要学习 Linux 内核?
大部分程序员可能永远没有机会开发Linux内核或者驱动Linux,那么我们为什么还需要学习Linux内核呢?Linux的源代码和架构都是开放的,我们可以学到很多操作系统的概念和实现原理。Linux的设计哲学体系继承了UNIX,现在整个设计体系相当稳定和简化,这是大部分服务器使用Linux的重要原因。
学习Linux内核的原因在于深入理解其底层原理,能够帮助你更高效地使用命令和进行程序设计,从而在面试和开发中脱颖而出。然而,直接阅读源代码并不推荐,因为Linux代码规模庞大且复杂,容易让人迷失方向。最佳的学习路径是先掌握Linux内核的基本机制和核心原理,例如进程管理、内存管理、文件系统等关键模块的工作流程。不过需要注意的是,这些内核机制本身也相互关联、错综复杂,因此建议通过系统性的学习资料或课程逐步深入,避免陷入细节而忽略整体框架的构建。
Linux内核的核心运作流程:
进程创建 → 申请内存空间(fork()/exec()) 内存管理 → 建立文件映射(mmap()) 文件系统 → 转换为块设备I/O请求 块设备驱动 → 从磁盘读取可执行文件 代码加载 → 将程序载入内存开始执行
这种关联理解的益处:
调试能力提升:当进程崩溃时,能快速定位是内存、文件还是I/O问题 性能优化精准:知道在哪个环节进行调优最有效(比如调整页面大小或I/O调度器) 系统设计更合理:开发应用时能更好地利用内核提供的各种机制
在 Linux 系统中,进程运行的背后藏着一套环环相扣的逻辑:进程启动时需要先分配内存来承载数据与代码,而内存映射又会将进程空间与具体文件关联起来,后续文件的读写操作还得通过块设备(如硬盘)完成,最终也是从文件中加载代码,进程才能真正跑起来。这些知识点看似分散,实则彼此牵连,必须反复对照梳理它们的依赖关系,才能打通逻辑断点。可一旦攻克这部分内容,你会明显感觉到:原本像 “黑盒” 一样复杂的 Linux 系统,突然变得透明起来,每个环节的运行原理都能清晰串联,对系统的理解也会从 “表面使用” 深入到 “底层逻辑”。
二、拆解 Linux 内核核心模块
Linux 内核之所以能在复杂的系统环境中高效稳定地运行,离不开其精心设计的核心模块。这些核心模块就像一个精密机器中的各个关键部件,各自承担着独特而重要的职责,它们相互协作,共同支撑起整个 Linux 系统的运行。
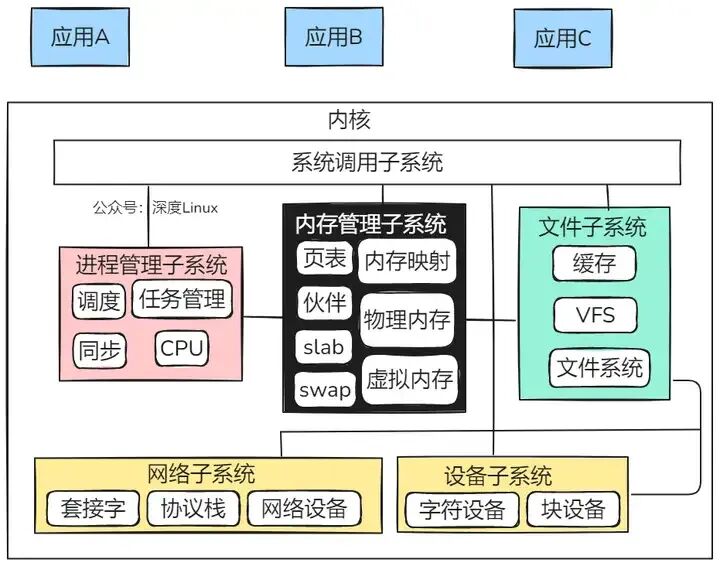
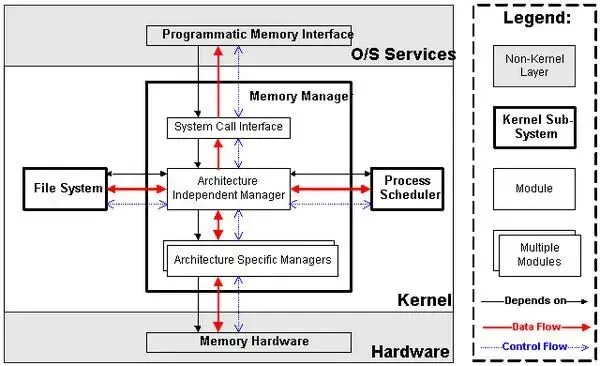
如上图所示,Linux内核的整体架构基于其核心功能被划分为五大子系统。首先,进程调度器负责管理CPU资源,确保各个进程能够以尽可能公平的方式访问CPU;其次,内存管理器负责管理内存资源,使多个进程能够安全共享内存,并通过虚拟内存机制支持进程使用超过物理内存容量的空间,未使用的数据通过文件系统存储于外部非易失存储器中,按需调回内存;第三,虚拟文件系统将各类外部设备(如硬盘、输入输出设备和显示设备等)抽象为统一的文件操作接口,体现了Linux“一切皆是文件”的设计哲学;第四,网络子系统负责管理系统中的网络设备并实现多种网络协议标准;最后,进程间通信机制不直接管理硬件,而是专注于协调系统中进程之间的通信。这些模块相互协作,构成了Linux内核高效、稳定且可扩展的核心架构。接下来,让我们深入到内核的内部世界,一探这些核心模块的究竟。
2.1 进程管理与调度模块
进程管理与调度模块是 Linux 内核的关键组成部分,它就像是一位精明能干的 “大管家”,全面负责进程的创建、终止以及调度等重要事务 。当我们在 Linux 系统中执行一个命令,比如运行一个 Python 脚本或者启动一个应用程序时,进程管理模块就会开始工作。它会通过 fork ()、vfork () 或 clone () 等系统调用创建一个新的进程,这个过程就像是为新的任务组建一个独立的 “工作团队”,为其分配独立的虚拟地址空间、文件描述符表、进程控制块(PCB,即 task_struct 结构体 )等资源,让这个 “工作团队” 能够独立地运行,互不干扰。
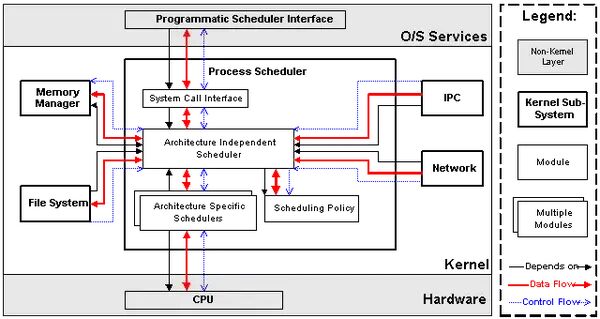
进程管理的重点是流程的实施。在内核中,这些进程称为线程,代表单个处理器虚拟化(线程代码、数据、堆栈和CPU寄存器)。在用户空间中,通常使用术语进程,但是Linux实现没有区分这两个概念(进程和线程)。内核SCI提供了一个应用程序编程接口(API)来创建一个新的进程(fork,exec或可移植操作系统接口[POSIX]函数),停止进程(kill,exit),并进行通信和同步(signal或POSIX机制)。
进程管理还包括处理活动进程之间共享CPU的需求。内核实现了新的调度算法,无论多少个线程争夺CPU,都可以在固定的时间内运行。这种算法被称为O(1) scheduler,这意味着它调度多个线程所用的时间与调度一个线程所用的时间相同。O(1)调度器也可以支持多处理器(称为对称多处理器或SMP)。您可以在中找到流程管理的源代码。/linux/kernel,以及。/linux/arch。
2.2 内存管理模块
在 Linux 系统中,内存管理模块是确保系统高效稳定运行的关键一环,它如同一位精打细算的 “内存管家”,精心管理着系统的物理内存和虚拟内存 。内核管理的另一个重要资源是内存。为了提高效率,如果虚拟内存由硬件管理,那么内存就按照所谓的内存分页法(大多数架构是4KB)来管理。Linux包括管理可用内存的方式和用于物理和虚拟映射的硬件机制。但是,内存管理需要管理4KB以上的缓冲区。
Linux提供了4KB缓冲区的抽象,比如slab分配器。这种内存管理模式以4KB缓冲区为基数,然后从中分配结构,并跟踪内存页面的使用情况,比如哪些页面已满,哪些页面未完全使用,哪些页面为空。这允许该模式根据系统需求动态调整内存使用。为了支持多个用户使用内存,有时会耗尽可用内存。因此,可以将页面移出内存,放入磁盘。这个过程称为交换,因为页面是从内存交换到硬盘的。内存管理的源代码可以在/linux/mm。
2.3 文件系统模块
在 Linux 系统中,文件系统模块扮演着至关重要的角色,它是连接用户与存储设备的桥梁,负责管理和组织存储设备上的数据,让用户能够方便、高效地存储和访问文件 。而虚拟文件系统(Virtual File System,VFS)则是文件系统模块的核心,它就像一个万能的 “翻译官”,为各种不同类型的文件系统提供了统一的操作接口,使得用户和应用程序可以用相同的方式来操作不同的文件系统,而无需关心底层文件系统的具体实现细节 。
无论是常见的基于磁盘的文件系统,如 ext4、XFS、Btrfs 等,还是网络文件系统,如 NFS(Network File System)、CIFS(Common Internet File System)等,亦或是虚拟文件系统,如 procfs、sysfs 等,VFS 都能将它们纳入自己的管理范畴,为它们提供统一的抽象和访问接口 。当我们在 Linux 系统中使用命令行工具(如 ls、cd、cp、rm 等)或者调用系统调用函数(如 open、read、write、close 等)来操作文件时,实际上都是通过 VFS 来完成的。VFS 会根据文件的路径和类型,将用户的操作请求转发给对应的实际文件系统驱动程序,由驱动程序来完成具体的操作,并将结果返回给 VFS,最后 VFS 再将结果返回给用户或应用程序。
以打开一个文件为例,当我们调用 open 函数时,VFS 会首先根据文件的路径名在内存中的目录树结构中查找对应的目录项(dentry),目录项是 VFS 中用于表示文件或目录的一种数据结构,它包含了文件的名称、索引节点(inode)指针等信息 。通过目录项,VFS 可以找到文件对应的 inode,inode 则是存储文件元数据(如文件大小、权限、创建时间、修改时间等)和数据块指针的重要数据结构 。VFS 会根据 inode 中的信息,判断文件所在的文件系统类型,并调用相应文件系统的驱动程序来打开文件。在文件打开后,VFS 会返回一个文件描述符(File Descriptor),文件描述符是一个整数,它是应用程序在后续操作中用于标识和访问该文件的句柄 。
Linux 系统支持多种不同类型的文件系统,每种文件系统都有其独特的设计和特点,以满足不同的应用场景和需求 。ext4 是目前 Linux 系统中最常用的文件系统之一,它是 ext3 文件系统的升级版,在性能、可靠性和功能方面都有了显著的提升 。ext4 支持更大的文件和文件系统容量,采用了更高效的日志机制来保证数据的一致性和完整性,还引入了一些新的特性,如延迟分配、多块分配、在线碎片整理等,提高了文件系统的性能和可管理性。
XFS 是一种高性能的日志文件系统,它特别适合用于存储大容量的数据和高并发的应用场景 。XFS 采用了分布式的元数据管理方式,能够充分利用多核 CPU 的性能,实现高效的文件读写操作 。它还支持动态扩展文件系统的大小,无需停机即可对文件系统进行扩容,这对于需要不断增加存储容量的应用来说非常方便。
Btrfs 是一种新兴的文件系统,它具有许多先进的特性,如快照、克隆、校验和、透明压缩等 。Btrfs 的设计目标是提供一个功能强大、可靠且易于管理的文件系统,它在数据完整性保护、数据管理和系统管理方面都有出色的表现 。例如,Btrfs 的快照功能可以让用户在不占用额外存储空间的情况下,快速创建文件系统的备份,方便用户进行数据恢复和版本管理;克隆功能则可以快速创建一个与原文件或目录完全相同的副本,且副本与原文件共享数据块,只有在数据发生变化时才会分配新的空间,大大节省了存储空间。
文件描述符在 Linux 系统的文件操作中起着关键的作用 。当我们使用 open 函数打开一个文件时,系统会返回一个文件描述符,它是一个非负整数,就像是文件的 “身份证号码”,用于唯一标识一个打开的文件 。在后续的文件操作中,如读取文件(read 函数)、写入文件(write 函数)、关闭文件(close 函数)等,我们都需要使用这个文件描述符来指定要操作的文件 。文件描述符不仅可以用于操作普通文件,还可以用于操作设备文件、管道、套接字等,因为在 Linux 系统中,“一切皆文件”,这些设备和通信接口都被抽象成了文件,通过文件描述符进行统一的访问和管理 。
在一个进程中,文件描述符是有限的资源,系统会为每个进程分配一定数量的文件描述符,默认情况下,每个进程最多可以打开 1024 个文件描述符 。当一个进程打开的文件描述符数量超过了系统的限制时,就会出现 “Too many open files” 的错误 。因此,在编写应用程序时,我们需要合理地管理文件描述符,及时关闭不再使用的文件,以避免文件描述符的浪费和耗尽 。
2.4 网络协议栈模块
协议栈(英语:Protocol stack),又称协议堆叠,是计算机网络协议套件的一个具体的软件实现。协议套件中的一个协议通常是只为一个目的而设计的,这样可以使得设计更容易。因为每个协议模块通常都要和其他两个通信,它们通常可以想象成是协议栈中的层。最低级的协议总是描述与硬件的物理交互。每个高级的层次增加更多的特性。用户应用程序只是处理最上层的协议。使用最广泛的是英特网协议栈,由上到下的协议分别是:应用层(HTTP,TELNET,DNS,EMAIL等),运输层(TCP,UDP),网络层(IP),链路层(WI-FI,以太网,令牌环,FDDI等),物理层。
在实际中,协议栈通常分为三个主要部分:媒体,传输和应用。一个特定的操作系统或平台往往有两个定义良好的软件接口:一个在媒体层与传输层之间,另一个在传输层和应用程序之间。
媒体到传输接口定义了传输协议的软件怎样使用特定的媒体和硬件(“驱动程序”)。例如,此接口定义的TCP/IP传输软件怎么与以太网硬件对话。这些接口的例子包括Windows和DOS环境下的ODI和NDIS。
应用到传输接口定义了应用程序如何利用传输层。例如,此接口定义一个网页浏览器程序怎样和TCP/IP传输软件对话。这些接口的例子包括Unix世界中的伯克利套接字和微软的Winsock。
2.5 设备驱动模块
在 Linux 系统中,设备驱动模块是连接内核与硬件设备的桥梁,它就像是硬件设备的 “翻译官”,负责将内核的指令翻译成硬件设备能够理解的信号,同时将硬件设备的状态和数据反馈给内核 。Linux 系统支持各种各样的硬件设备,从常见的硬盘、网卡、显卡、声卡,到各种嵌入式设备和传感器,而设备驱动模块的存在,使得这些硬件设备能够在 Linux 系统中正常工作,为用户和应用程序提供服务 。
根据设备的类型和数据传输方式,设备驱动可以分为字符设备驱动、块设备驱动和网络设备驱动 。字符设备驱动主要用于管理那些以字节流方式进行数据传输的设备,如串口、键盘、鼠标、LED 灯等 。这些设备的数据传输通常是实时的,不需要经过缓存,字符设备驱动程序会直接与硬件设备进行交互,实现数据的读写操作 。例如,当我们在 Linux 系统中使用串口进行数据通信时,串口设备驱动程序会负责将用户发送的数据逐字节地发送到串口硬件设备上,并将串口接收到的数据逐字节地读取出来,传递给用户或应用程序 。
块设备驱动则用于管理那些以块为单位进行数据传输的设备,如硬盘、固态硬盘(SSD)、U 盘、SD 卡等存储设备 。块设备通常会有自己的缓存机制,数据的读写是以块为单位进行的,这样可以提高数据传输的效率 。块设备驱动程序不仅要负责与硬件设备进行数据传输,还要管理设备的缓存,确保数据的一致性和完整性 。例如,当我们向硬盘写入数据时,块设备驱动程序会将用户的数据先存储在缓存中,然后再根据一定的策略将缓存中的数据写入到硬盘的物理介质上;当从硬盘读取数据时,驱动程序会先检查缓存中是否有需要的数据,如果有,则直接从缓存中读取,以提高读取速度;如果没有,则从硬盘中读取数据,并将数据存储到缓存中,以便下次读取时能够更快地获取 。
网络设备驱动主要用于管理网络通信设备,如以太网网卡、无线网卡、蓝牙模块等 。网络设备驱动程序负责实现网络协议栈与硬件设备之间的接口,实现数据包的发送和接收 。在网络通信过程中,网络设备驱动程序会将来自网络协议栈的数据包封装成适合硬件设备传输的格式,然后通过硬件设备发送到网络上;同时,它也会接收来自网络的数据包,并将其解封装后。
2.6内核调试
你有没有过这样的经历?为了排查一个内核 bug,熬了几个通宵 —— 先是反复重启系统试错,再手动注释代码缩小范围,最后好不容易定位到问题,却发现只是一个简单的锁使用不当。如果懂内核调试,这一切可能只需要几小时。内核调试的核心,不是 “死磕代码”,而是 “用对工具”:printk 能帮你留下关键节点的运行痕迹,kgdb 支持像调试用户态程序一样设置断点、查看变量,ftrace 能跟踪函数调用耗时找出性能瓶颈。不管是驱动开发中的兼容性问题,还是源码学习时的逻辑困惑,掌握内核调试,就能让你从 “摸黑排查” 变成 “精准定位”。
三、Linux 内核模块的动态管理
3.1 内核模块的概念
内核模块是 Linux 内核实现动态扩展的重要机制,它允许在不重新编译和重启内核的情况下,向内核添加或移除特定功能 。这些模块通常以独立的.ko(Kernel Object)文件形式存在,就像是一个个可以随时插拔的 “小插件”,在需要时被动态加载到内核中运行,不需要时则可以被卸载,从而释放系统资源 。
内核模块的功能十分广泛,涵盖了设备驱动、文件系统、网络协议等多个方面 。例如,当我们在 Linux 系统中插入一个新的 USB 设备时,系统会自动加载对应的 USB 设备驱动模块,使得内核能够识别和管理这个设备;当我们需要使用 NFS 网络文件系统时,就可以加载 NFS 模块,实现对远程文件系统的挂载和访问 。通过这种方式,Linux 内核既保持了核心代码的简洁和稳定,又具备了强大的扩展性,能够灵活地适应各种不同的硬件环境和应用需求 。
从本质上来说,内核模块是一段内核代码,它运行在内核空间,具有与内核其他部分相同的权限 。但与编译进内核的静态代码不同,内核模块是在运行时被动态加载的,这使得内核的功能可以根据实际需求进行定制和扩展,大大提高了系统的灵活性和可维护性 。例如,对于一些不常用的设备驱动或功能模块,如果将它们静态编译进内核,会导致内核体积增大,启动时间变长,并且在不需要这些功能时,还会占用系统资源 。而使用内核模块,我们可以在需要时才加载它们,不需要时则卸载,从而有效地减少了内核的体积和资源占用,提高了系统的运行效率 。
3.2 模块的操作命令
在 Linux 系统中,我们可以使用一系列命令来对内核模块进行动态管理,这些命令就像是操作内核模块的 “魔法工具”,让我们能够方便地加载、卸载、查看和了解内核模块的相关信息 。
lsmod命令用于列出当前系统中已加载的内核模块及其相关信息,包括模块名称、大小、被哪些模块依赖等 。执行lsmod命令后,系统会以表格的形式展示各个模块的详细信息,例如:
Module Size Used byxt_recent 12681 2iptable_filter 12421 1ip_tables 24212 1 iptable_filterx_tables 32442 2 ip_tables,iptable_filter通过这个命令,我们可以清楚地了解到当前系统中已经加载了哪些模块,以及它们之间的依赖关系,这对于系统管理员来说非常重要,有助于他们监控系统的运行状态,排查潜在的问题 。
insmod命令用于将指定的内核模块文件(.ko 文件)加载到内核中 。例如,如果我们有一个名为my_module.ko的内核模块文件,想要将其加载到内核中,可以使用以下命令:
sudo insmod my_module.ko执行该命令后,内核会将my_module.ko模块加载到内存中,并执行模块中的初始化函数(通常由module_init宏指定),完成模块的初始化工作 。需要注意的是,insmod命令不会自动处理模块的依赖关系,如果模块依赖其他模块,需要手动先加载依赖模块 。
rmmod命令用于从内核中卸载已加载的内核模块 。使用该命令时,需要指定要卸载的模块名称,而不是模块文件的完整路径 。例如,要卸载名为my_module的模块,可以执行以下命令:
sudo rmmod my_module在卸载模块之前,系统会检查模块是否正在被使用,如果模块正在被其他部分使用,卸载操作将会失败,以防止系统出现错误或不稳定的情况 。这就好比在拆卸一个机器部件时,需要先确保这个部件不再被其他部件依赖,否则可能会导致整个机器无法正常运行 。
modinfo命令用于查看内核模块的详细信息,包括模块的作者、描述、版本、许可证、依赖关系等 。通过执行modinfo命令,我们可以获取到模块的各种元数据,这对于了解模块的功能和特性非常有帮助 。例如,要查看my_module.ko模块的详细信息,可以使用以下命令:
modinfo my_module.ko命令执行后,会输出类似以下的信息:
filename: /path/to/my_module.koauthor: Your Namedescription: This is a sample kernel modulelicense: GPLdepends: module1,module2version: 1.0从这些信息中,我们可以了解到模块的基本情况,如作者是谁、模块的功能是什么、遵循的许可证是什么,以及它依赖哪些其他模块等 。这些信息对于评估模块的安全性、可靠性以及与系统的兼容性都非常重要 。
3.3 模块开发示例
为了更直观地了解 Linux 内核模块的开发过程,下面我们来看一个简单的内核模块代码示例 。这个示例代码实现了一个最基本的内核模块,它在加载时会打印一条信息,在卸载时也会打印一条信息 。
#include <linux/module.h> // 包含模块相关的宏和函数定义#include <linux/kernel.h> // 包含内核常用的函数和数据结构#include <linux/init.h> // 包含模块初始化和清理的宏// 模块加载时执行的初始化函数static int __init my_module_init(void) { printk(KERN_INFO "My module is loaded.\n"); return 0; // 返回0表示初始化成功}// 模块卸载时执行的清理函数static void __exit my_module_exit(void) { printk(KERN_INFO "My module is unloaded.\n");}// 使用module_init宏注册模块的初始化函数module_init(my_module_init);// 使用module_exit宏注册模块的卸载函数module_exit(my_module_exit);// 声明模块的许可证,这里使用GPL许可证MODULE_LICENSE("GPL");// 可以添加模块的其他描述信息,如作者、版本等MODULE_AUTHOR("Your Name");MODULE_DESCRIPTION("A simple Linux kernel module");MODULE_VERSION("1.0");在这个示例中,module_init宏指定了模块加载时要执行的初始化函数my_module_init,当使用insmod命令加载模块时,内核会调用这个函数 。在my_module_init函数中,我们使用printk函数打印了一条信息,表示模块已经被加载 。printk是内核中的打印函数,类似于用户空间的printf函数,但它会将信息输出到内核日志缓冲区,我们可以使用dmesg命令查看这些日志信息 。
module_exit宏指定了模块卸载时要执行的清理函数my_module_exit,当使用rmmod命令卸载模块时,内核会调用这个函数 。在my_module_exit函数中,同样使用printk函数打印了一条信息,表示模块已经被卸载 。
接下来,我们需要编写一个Makefile来编译这个内核模块 。下面是一个简单的Makefile示例:
obj-m += my_module.oKDIR := /lib/modules/$(shell uname -r)/buildPWD := $(shell pwd)all: $(MAKE) -C $(KDIR) M=$(PWD) modulesclean: $(MAKE) -C $(KDIR) M=$(PWD) clean在这个Makefile中,obj-m += my_module.o表示将my_module.c文件编译成一个可加载的内核模块(.ko 文件) 。KDIR变量指定了当前运行内核的源代码目录,通过$(shell uname -r)获取当前内核版本,然后拼接成内核源代码目录的路径 。PWD变量表示当前工作目录 。
all目标用于编译模块,它通过$(MAKE) -C $(KDIR) M=$(PWD) modules命令,切换到内核源代码目录下,使用内核的编译规则来编译当前目录下的模块 。clean目标用于清理编译生成的文件,通过$(MAKE) -C $(KDIR) M=$(PWD) clean命令,清除编译过程中产生的中间文件和目标文件 。
编译内核模块时,在终端中进入包含my_module.c和Makefile的目录,执行make命令即可开始编译 。编译完成后,会生成一个my_module.ko文件,这就是我们编译好的内核模块 。
要加载这个模块,可以使用insmod命令:
sudo insmod my_module.ko加载成功后,可以使用dmesg命令查看内核日志,确认模块是否加载成功,是否打印了预期的信息 。
要卸载这个模块,可以使用rmmod命令:
sudo rmmod my_module卸载成功后,再次使用dmesg命令查看内核日志,确认模块是否已经被卸载,是否打印了卸载信息 。
通过这个简单的示例,我们可以初步了解 Linux 内核模块的开发、编译和加载过程,为进一步深入学习和开发内核模块奠定基础 。
四、怎么学习linx内核?
Linux庞大而复杂,其核心包括进程管理、内存管理、网络、文件系统和arch-entity="2 " >驱动,这些都依赖于内核提供的各种库和接口、各种内核机制以及arch下可能对应的汇编。没有这些基础,要流畅的阅读代码就有点困难了;Linux的代码量很大,而且是在gcc的基础上开发的,针对各种场景做了大量的优化。所以第二件事就是要熟悉gcc下C的扩展用法,要有一个好的代码查看工具。推荐源洞察。
内核运行在特定的硬件平台上,所以对于底层涉及的部分有不同的arch实现,包括大量的汇编操作,所以以arm为例。如果想研究内核相应部分的代码,就必须多读,熟悉arm的官方文档。而且代码和资料基本都是英文的,一般词汇和专业词汇都有,所以英语基础好很重要。这个没有捷径,就是多读书,当然也有积累的方法,后面会讲到。
每个模块都有很多细节。可能你年轻的时候记性好吧。你开发一个模块的时候,都读了好几遍了,所有的细节都不是很清楚。可能3、5年后再看就很难记住了,所以需要想办法形成积累。否则可能会忘记看,辛苦又低效。内核编程有自己的风格和一些公认的规则,尤其是命名、排版、代码文件分类等。有些可能不符合规则,也可能很好,但如果大家都这样用,那自然就是所谓的艺术了,熟悉这些艺术有助于举一反三的学习其他模块的代码。
内核的代码量与日俱增,模块也越来越复杂,所以可维护性对于内核来说也是非常重要的。所以在如何更有利于以后的维护上做了很多努力。内核是操作系统的核心部分,其稳定性和性能自然非常重要。它用了很多技巧来应对。研究这些,积累起来,有利于进一步理解其原理。
边看代码边写注释和笔记。看了多少模块就注释多少模块,慢慢形成一个积累。这样的方式有什么好处呢?
记录你看代码过程中不熟悉或者不清晰的地方,或者你看明白了但是怕忘记的地方,这样等你下次再来看你能很快回忆起来,且不断刺激你的记忆神经能让你记忆的更牢固。 记录内核中用法的好处或者有疑问的地方,这样你再次来看的话可能会有新的体会,能在之前看代码的基础上形成一个不断积累的过程,理解会更加深刻。 当你将内核代码模块看的越来越多时,你会越看越轻松,当然是不是也会惊讶一下。轻松的是这个模块我看过,用法我熟悉,惊讶的是这个我虽然看过好多次,理解竟然有点不对。反反复复不断进行下去。
4.1查看代码的工具
Linux 内核源码规模庞大(最新版本超千万行代码),直接用记事本或普通文本编辑器打开,不仅加载慢,还没法快速跳转函数、查看依赖关系 —— 这时候专门的源码查看工具就像 “导航仪”,能帮你在代码海洋里精准定位,效率翻倍。下面推荐 5 款覆盖不同场景的工具,从本地到在线、从图形化到命令行,总有一款适合你。
(1)本地图形化工具——可视化操作,新手友好
【1】VS Code + 插件:轻量又能打,习惯用VS Code写代码,想一站式完成 “查看源码 + 编辑注释” 的需求。
C/C++:提供语法高亮、代码补全; C/C++ Extension Pack:增强版插件集,支持函数跳转、定义查找; CodeLLDB:若需要调试源码,可搭配此插件。
③ 查看源码时,按住Ctrl键点击函数名,就能跳转到定义;右键 “查找所有引用”,可看函数被调用的位置,新手也能快速上手。
【2】Qt Creator:专为 C/C++ 打造,跳转更精准,深度阅读 Linux 内核(纯 C 语言),追求更精准的代码分析能力。对 C 语言的语法解析更深入,支持 “类 / 函数继承关系图”,适合梳理复杂模块(如进程管理、内存管理)的逻辑。
注意点:打开源码前,需先在 Qt Creator 中创建 “非 Qt 项目”(选择 “Plain C Project”),再将源码文件夹添加到项目中,否则可能无法识别内核源码的目录结构。
(2)本地命令行工具——服务器环境必备,无界面也高效
【1】ctags + cscope:经典组合,轻量不占资源,在 Linux 服务器(无图形界面)上查看源码,或喜欢用 Vim/Neovim 编辑的开发者;纯命令行操作,占用内存少,支持快速索引和跳转,是内核开发者的 “老搭档”。
① 安装工具:sudo apt install ctags cscope(Debian/Ubuntu)或sudo yum install ctags cscope(CentOS); ② 进入源码根目录,生成索引文件:
# 生成ctags索引(支持函数、宏定义跳转)ctags -R * # 生成cscope索引(支持查找引用、依赖关系)cscope -Rbq ③ 用 Vim 打开源码文件(如vim kernel/sched/core.c),操作示例:
按Ctrl + ]:跳转到光标所在函数的定义; 按Ctrl + T:返回上一级跳转位置; 输入:cs find c func_name:查找函数func_name被调用的位置(“c” 代表 “callers”)。
【2】grep:简单直接,快速搜索关键词,临时查找某个宏定义、函数名或字符串,不需要复杂跳转。无需生成索引,直接搜索,适合 “快速定位某个知识点”(如查找PAGE_SIZE的定义)。
常用命令:
# 在源码中搜索“PAGE_SIZE”,显示行号和文件路径grep -rn "PAGE_SIZE" ./linux-6.6.3/ # 只搜索.c文件中的“schedule”函数grep -rn "schedule" ./linux-6.6.3/ --include="*.c" 注:-r表示递归搜索子目录,-n显示行号,--include指定文件类型,避免搜索无关文件(如文档、配置文件)。
(3)在线工具——无需下载源码,打开浏览器就能看
【1】LXR Cross Referencer:内核源码专属 “百科”,不想本地下载源码(节省存储空间),或需要对比不同版本内核代码差异。在线索引,支持版本切换(从 2.6 到最新版本),能直接查看函数的 “调用树”“被调用树”,还能对比同一文件在不同版本的修改。
直接访问官网 lxr.linux.no ,在搜索框输入函数名(如sys_open),选择对应内核版本,即可看到函数定义、所在文件,以及所有调用它的位置 —— 甚至能看到代码的提交历史(谁修改的、为什么修改),对理解 “代码演进” 很有帮助。
【2】GitHub + 浏览器插件:看源码 + 查提交记录,习惯用 GitHub,想结合源码的 Git 提交历史(如查看某个功能是哪个版本新增的)。
① 访问 Linux 内核的 GitHub 镜像仓库: torvalds/linuxhttps://github.com/torvalds/linux; ② 切换到需要查看的分支(如master是最新开发版,v6.6是稳定版); ③ 安装浏览器插件(如 Chrome 的 “GitHub Code Navigation”),可实现函数跳转、定义查找;若想对比版本差异,直接在仓库页面点击 “Compare”,输入两个版本号(如v6.5..v6.6),就能看到所有修改文件。
小技巧:查看源码更高效的 3 个习惯
先看目录结构,再钻细节:Linux 源码目录(如kernel/是进程管理,mm/是内存管理,fs/是文件系统)有明确分工,先理清模块划分,再看具体文件; 用 “关键词联想” 搜索:比如想了解 “进程调度”,除了搜sched,还可以搜CFS(Linux 默认调度器)、task_struct(进程结构体); 搭配文档看源码:内核源码自带Documentation/文件夹(如Documentation/scheduler/sched-design-CFS.rst是 CFS 调度器的设计文档),先看文档理解逻辑,再看代码会更轻松。
4.2学习Linux内核方法
学习linux内核不像学习语言。一个月或者三月就能掌握C或者java。学习linux内核需要循序渐进,掌握正确的linux内核学习路线非常重要。本文将分享一些学习linux内核的建议。
学习Linux内核开发前需要做好充分的准备工作:首先必须熟练掌握C语言,这是最基础的要求;其次要深入理解编译链接过程,如果实际编写过ld、lcf等链接脚本更佳,这样才能真正理解Linux内核中percpu变量等底层机制的实现原理;同时需要系统学习计算机组成原理或微机原理,掌握SMP多处理器架构、CPU工作模式、Cache缓存机制、RAM内存管理、硬盘存储结构以及总线通信等硬件知识,并深刻理解中断处理、DMA传输和寄存器操作等核心概念——这些硬核知识是理解内核中上下文切换(context)、内存屏障(barrier)等关键机制的必要前提。
Linux内核的特点:结合了unix操作系统的一些基础概念
很多同学接触Linux不多,对Linux平台的开发更是一无所知。而现在的趋势越来越表明,作为一 个优秀的软件开发人员,或计算机IT行业从业人员,掌握Linux是一种很重要的谋生资源与手段。下来我将会结合自己的几年的个人开发经验,及对 Linux,更是类UNIX系统,及开源软件文化,谈谈Linux的学习方法与学习中应该注意的一些事。就如同刚才说的,很多同学以前可能连Linux是什么都不知道,对UNIX更是一无所知。所以我们从最基础的讲起,对于Linux及UNIX的历史我们不做多谈,直接进入入门的学习。
Linux入门是很简单的,问题是你是否有耐心,是否爱折腾,是否不排斥重装一类的大修。没折腾可以说是学不好Linux的,鸟哥说过,要真正了解Linux的分区机制,对LVM使用相当熟练,没有20次以上的Linux装机经验是积累不起来的,所以一定不要怕折腾。
由于大家之前都使用Windows,所以我也尽可能照顾这些“菜鸟”。我的推荐,如果你第一次接触Linux,那么首先在虚拟机中尝试它。虚拟机我推荐Virtual Box,我并不主张使用VM,原因是VM是闭源的,并且是收费的,我不希望推动盗版。当然如果你的Money足够多,可以尝试VM,但我要说的是即使是VM,不一定就一定好。付费的软件不一定好。首先,Virtual Box很小巧,Windows平台下安装包在80MB左右,而VM动辄600MB,虽然功能强大,但资源消耗也多,何况你的需求Virtual Box完全能够满足。所以,还是自己选。如何使用虚拟机,是你的事,这个我不教你,因为很简单,不会的话Google或Baidu都可以,英文好的可以直接看官方文档。
现在介绍Linux发行版的知识。正如你所见,Linux发行版并非Linux,Linux仅是指操作系统的内核,作为科班出生的你不要让我解释,我也没时间。我推荐的发行版如下:
UBUNTU适合纯菜鸟,追求稳定的官方支持,对系统稳定性要求较弱,喜欢最新应用,相对来说不太喜欢折腾的开发者。 Debian,相对UBUNTU难很多的发行版,突出特点是稳定与容易使用的包管理系统,缺点是企业支持不足,为社区开发驱动。 Arch,追逐时尚的开发者的首选,优点是包更新相当快,无缝升级,一次安装基本可以一直运作下去,没有如UBUNTU那样的版本概念,说的专业点叫滚动升级,保持你的系统一定是最新的。缺点显然易见,不稳定。同时安装配置相对Debian再麻烦点。 Gentoo,相对Arch再难点,考验使用者的综合水平,从系统安装到微调,内核编译都亲历亲为,是高手及黑客显示自己技术手段,按需配置符合自己要求的系统的首选。
Slackware与Gentoo类似:
CentOS,社区维护的RedHat的复刻版本,完全使用RedHat的源码重新编译生成,与RedHat的兼容性在理论上来说是最好的。如果你专注于Linux服务器,如网络管理,架站,那么CentOS是你的选择。
LFS,终极黑客显摆工具,完全从源代码安装,编译系统。安装前你得到的只有一份文档,你要做的就是照文档你的说明,一步步,一条条命令,一个个软件包的去构建你的Linux,完全由你自己控制,想要什么就是什么。如果你做出了LFS,证明你的Linux功底已经相当不错,如果你能拿LFS文档活学活用,再将Linux从源代码开始移植到嵌入式系统,我敢说中国的企业你可以混的很好。
你得挑一个适合你的系统,然后在虚拟机安装它,开始使用它。如果你想快速学会Linux,我有一个建议就是忘记图形界面,不要想图形界面能不能提供你问题的答案,而是满世界的去找,去问,如何用命令行解决你的问题。在这个过程中,你最好能将Linux的命令掌握的不错,起码常用的命令得知道,同时建立了自己的知识库,里面是你积累的各项知识。
再下个阶段,你需要学习的是Linux平台的C++/C++开发,同时还有Bash脚本编程,如果你对Java兴趣很深还有Java。同样,建议你抛弃掉图形界面的IDE,从VIM开始,为什么是VIM,而不是Emacs,我无意挑起编辑器大战,但我觉得VIM适合初学者,适合手比较笨,脑袋比较慢的开发者。Emacs的键位太多,太复杂,我很畏惧。然后是GCC,Make,Eclipse(Java,C++或者)。虽然将C++列在了Eclipse中,但我并不推荐用IDE开发C++,因为这不是Linux的文化,容易让你忽略一些你应该注意的问题。IDE让你变懒,懒得跟猪一样。如果你对程序调试,测试工作很感兴趣,GDB也得学的很好,如果不是GDB也是必修课。这是开发的第一步,注意我并没有提过一句Linux系统API的内容,这个阶段也不要关心这个。你要做的就是积累经验,在Linux平台的开发经验。我推荐的书如下:C语言程序设计,谭浩强的也可以。C语言,白皮书当然更好。C++推荐C++ Primer Plus,Java我不喜欢,就不推荐了。工具方面推荐VIM的官方手册,GCC中文文档,GDB中文文档,GNU开源软件开发指导(电子书),汇编语言程序设计(让你对库,链接,内嵌汇编,编译器优化选项有初步了解,不必深度)。
如果你这个阶段过不了就不必往下做了,这是底线,最基础的基础,否则离开,不要霍霍Linux开发。不专业的Linux开发者作出的程序是与Linux文化或UNIX文化相背的,程序是走不远的,不可能像Bash,VIM这些神品一样。所以做不好干脆离开。
接下来进入Linux系统编程,不二选择,APUE,UNIX环境高级编程,一遍一遍的看,看10遍都嫌少,如果你可以在大学将这本书翻烂,里面的内容都实践过,有作品,你口头表达能力够强,你可以在面试时说服所有的考官。(可能有点夸张,但APUE绝对是圣经一般的读物,即使是Windows程序员也从其中汲取养分,Google创始人的案头书籍,扎尔伯克的床头读物。)
这本书看完后你会对Linux系统编程有相当的了解,知道Linux与Windows平台间开发的差异在哪?它们的优缺点在哪?我的总结如下:做Windows平台开发,很苦,微软的系统API总在扩容,想使用最新潮,最高效的功能,最适合当前流行系统的功能你必须时刻学习。Linux不是,Linux系统的核心API就100来个,记忆力好完全可以背下来。而且经久不变,为什么不变,因为要同UNIX兼容,符合POSIX标准。所以Linux平台的开发大多是专注于底层的或服务器编程。这是其优点,当然图形是Linux的软肋,但我站在一个开发者的角度,我无所谓,因为命令行我也可以适应,如果有更好的图形界面我就当作恩赐吧。另外,Windows闭源,系统做了什么你更本不知道,永远被微软牵着鼻子跑,想想如果微软说Win8不支持QQ,那腾讯不得哭死。而Linux完全开源,你不喜欢,可以自己改,只要你技术够。另外,Windows虽然使用的人多,但使用场合单一,专注与桌面。而Linux在各个方面都有发展,尤其在云计算,服务器软件,嵌入式领域,企业级应用上有广大前景,而且兼容性一流,由于支持POSIX可以无缝的运行在UNIX系统之上,不管是苹果的Mac还是IBM的AS400系列,都是完全支持的。另外,Linux的开发环境支持也绝对是一流的,不管是C/C++,Java,Bash,Python,PHP,Javascript,。。。。。。就连C#也支持。而微软除Visual Stdio套件以外,都不怎么友好,不是吗?
如果你看完APUE的感触有很多,希望验证你的某些想法或经验,推荐UNIX程序设计艺术,世界顶级黑客将同你分享他的看法。现在是时候做分流了。大体上我分为四个方向:网络,图形,嵌入式,设备驱动。
如果选择网络,再细分,我对其他的不是他熟悉,只说服务器软件编写及高性能的并发程序编写吧。相对来说这是网络编程中技术含量最高的,也是底层的。需要很多的经验,看很多的书,做很多的项目。
我的看法是以下面的顺序来看书:
APUE再深读 – 尤其是进程,线程,IPC,套接字 多核程序设计 - Pthread一定得吃透了,你很NB UNIX网络编程 – 卷一,卷二 TCP/IP网络详解 – 卷一 再看上面两本书时就该看了 TCP/IP 网络详解 – 卷二 我觉得看到卷二就差不多了,当然卷三看了更好,努力,争取看了 Lighttpd源代码 - 这个服务器也很有名了 Nginx源代码 – 相较于Apache,Nginx的源码较少,如果能看个大致,很NB。看源代码主要是要学习里面的套接字编程及并发控制,想想都激动。如果你有这些本事,可以试着往暴雪投简历,为他们写服务器后台,想一想全球的魔兽都运行在你的服务器软件上。 Linux内核TCP/IP协议栈 – 深入了解TCP/IP的实现
如果你还喜欢驱动程序设计,可以看看更底层的协议,如链路层的,写什么路由器,网卡,网络设备的驱动及嵌入式系统软件应该也不成问题了。当然一般的网络公司,就算百度级别的也该毫不犹豫的雇用你。只是看后面这些书需要时间与经验,所以35岁以前办到吧!跳槽到给你未来的地方!
嵌入式方向:嵌入式方向没说的,Linux很重要
掌握多个架构,不仅X86的,ARM的,单片机什么的也必须得懂。硬件不懂我预见你会死在半路上,我也想走嵌入式方向,但我觉得就学校教授嵌入式的方法,我连学电子的那帮学生都竞争不过。奉劝大家,一定得懂硬件再去做,如果走到嵌入式应用开发,只能祝你好运,不要碰上像Nokia,Hp这样的公司,否则你会很惨的。
驱动程序设计:软件开发周期是很长的,硬件不同,很快。每个月诞生那么多的新硬件,如何让他们在Linux上工作起来,这是你的工作。由于Linux的兼容性很好,如果不是太低层的驱动,基本C语言就可以搞定,系统架构的影响不大,因为有系统支持,你可能做些许更改就可以在ARM上使用PC的硬件了,所以做硬件驱动开发不像嵌入式,对硬件知识的要求很高。可以从事的方向也很多,如家电啊,特别是如索尼,日立,希捷,富士康这样的厂子,很稀缺的。
内核是IT开发人员的加分项,一个计算机系统是一个硬件和软件的共生体,它们互相依赖,不可分割。计算机的硬件,含有外围设备、处理器、内存、硬盘和其他的电子设备组成计算机的发动机。但是没有软件来操作和控制它,自身是不能工作的。完成这个控制工作的软件就称为操作系统,在Linux的术语中被称为“内核”,也可以称为“核心”。Linux内核的主要模块(或组件)分以下几个部分:存储管理、CPU和进程管理、文件系统、设备管理和驱动、网络通信,以及系统的初始化(引导)、系统调用等。
Linux 内核实现了很多重要的体系结构属性。在或高或低的层次上,内核被划分为多个子系统。Linux 也可以看作是一个整体,因为它会将所有这些基本服务都集成到内核中。这与微内核的体系结构不同,后者会提供一些基本的服务,例如通信、I/O、内存和进程管理,更具体的服务都是插入到微内核层中的。
随着时间的流逝,Linux 内核在内存和 CPU 使用方面具有较高的效率,并且非常稳定。但是对于 Linux 来说,最为有趣的是在这种大小和复杂性的前提下,依然具有良好的可移植性。Linux 编译后可在大量处理器和具有不同体系结构约束和需求的平台上运行。一个例子是 Linux 可以在一个具有内存管理单元(MMU)的处理器上运行,也可以在那些不提供MMU的处理器上运行。Linux 内核的uClinux移植提供了对非 MMU 的支持。
在IT行业 如:嵌入式开发,驱动开发,Android开发,c++开发,Java开发如果接触到底层方面 那么 懂得内核:会使自己的开发工作产生对应的效益。懂得内核:会让自己更加了解底层的原理与开发源码。内核是面试的加分项 内核是走向专家的必经之路 不管你是不是做内核开发,内核技术是储备技能,开阔视野,扩展技术面的不二选择。
4.3相关Linux内核书籍
(1)入门级——建立内核基础认知,告别 “看不懂”
《Linux 内核设计与实现》(第3版/第4版)由前Google工程师、Linux内核贡献者Robert Love撰写,适合零基础想入门内核或有一定Linux使用经验但希望理解底层逻辑的开发者。该书完全避开复杂源码,以通俗语言讲解内核核心概念,如进程管理、内存管理和文件系统等模块的“工作逻辑”,而非直接贴代码;结构清晰,每章聚焦一个模块,例如“进程调度”章节会先阐述调度原理,再分析CFS调度器的设计思路,帮助新手快速掌握“内核是如何做事的”。第4版内容已更新至Linux 5.x版本,涵盖控制组v2等新特性,确保内容不过时。阅读建议是无需纠结源码细节,先理解内核各模块的功能和协作方式,为后续深入学习源码打下坚实基础。
《深入理解Linux内核》(第3版/第4版)由Daniel P. Bovet等Linux内核深度研究者编写,适合具备C语言基础、希望深入了解内核底层实现细节的学习者(相较于《Linux内核设计与实现》难度稍高)。该书比入门教材更深入,系统讲解内核的“数据结构”和“关键算法”,例如内存管理中的伙伴系统和slab分配器会通过伪代码与文字解析相结合的方式拆解实现逻辑,帮助读者理解“内核为什么这样设计”;内容覆盖进程、内存、文件、网络、中断等核心子系统,每个子系统均按“原理→实现→实例”的逻辑展开,比如文件系统章节会详解VFS如何统一不同文件系统的接口。需注意的是,第3版基于Linux 2.6内核,而第4版已更新至Linux 4.x版本,建议优先选择新版以避免内容过时。阅读时可搭配内核源码目录同步学习(例如学习“内存管理”章节时参考源码mm/文件夹),但无需逐行阅读代码,重点应放在理解书中阐述的设计思路与实现逻辑上。
(2)进阶级——结合源码学习,打通 “理论→实践”
《Linux 内核源码情景分析》(上下册)由国内 Linux 内核领域权威专家毛德操、胡希明编写,是一套面向具备 C 语言和基础内核知识的开发者的经典著作。该书以“情景化”方式解析源码,围绕具体场景展开分析,例如在讲解进程创建时,从 fork() 系统调用入手,逐步跟踪 do_fork()、copy_process() 等关键函数的执行流程,清晰揭示进程创建的完整实现路径。书中基于 Linux 2.4/2.6 版本源码,虽版本稍旧,但核心架构与设计思想至今仍具重要参考价值;其代码分析极为深入细致,如在中断处理部分详细阐释了中断上下半部的实现机制以及 softirq、tasklet 的区别与适用场景。作为中文原创技术书籍,它在术语解释和原理阐述上更符合国内读者的思维习惯,对“页高速缓存”“虚拟内存”等核心概念的解读比外文译著更为清晰易懂。建议读者先通过入门教材建立内核整体框架,再结合本书针对特定模块进行专项突破——例如学习完进程调度章节后,可同步查阅内核源码 kernel/sched/ 目录下 schedule() 等函数的实际实现,以达到理论分析与代码实践深度融合的效果。
《Professional Linux Kernel Architecture》由Linux内核专家Wolfgang Mauerer编写,面向希望系统学习现代Linux内核(3.x及以后版本)且具备英语阅读能力的开发者。该书全面覆盖了控制组(cgroups)、命名空间(namespaces)、RCU锁机制等新特性,这些正是理解Docker、Kubernetes等容器技术的基础。书中源码分析与实际应用紧密结合,例如在内存管理章节会探讨内存泄漏和OOM杀手机制,帮助读者深入理解内核设计对系统性能的影响。全书结构严谨,每个章节遵循“理论→实现→示例”的逻辑框架,如网络子系统部分从TCP/IP协议栈逐步解析到net/目录的源码架构。建议将此书作为进阶阶段的核心参考资料,搭配5.x/6.x等最新内核源码进行对照学习,重点关注书中阐述的现代内核特性与实现原理。
(3)实践级——聚焦内核开发,从 “看懂” 到 “会写”
《Linux 设备驱动开发》(第3版)由Linux内核文档维护者Jonathan Corbet等权威专家撰写,是专为从事Linux设备驱动开发或希望理解内核硬件交互逻辑的工程师设计的实用指南。本书系统讲解了从基础的字符设备驱动到中断处理、DMA及设备树等核心知识,通过具体示例(如module_init()/module_exit()模块编写、完整的LED驱动代码实现)演示驱动的编译、加载与用户空间测试流程。基于Linux 2.6内核的驱动框架(核心机制仍适用于现代内核),书中还深入探讨了并发处理、调试技巧等实际开发必备的最佳实践。即使不专注于驱动开发,工程师也能通过本书掌握内核与硬件交互的核心原理(如中断机制和I/O端口操作),是衔接内核理论与工程实践的关键读物。
(4)核心书目——覆盖 “入门→进阶→实践” 全链条
《奔跑吧 Linux 内核・入门篇》(第 2 版)由笨叔、陈悦合著,是一本面向零基础入门或希望通过“理论+实验”双路径学习的开发者(尤其适合嵌入式/Android方向新手)的实践型教材。本书以实验驱动为核心特色,全书包含70多个可动手操作的实验,从内核编译调试、模块开发到简单驱动编写,例如手把手指导读者使用module_init()实现字符设备驱动,有效解决了传统入门书籍“光看不动”的痛点。内容全面覆盖进程、内存等核心模块,同时拓展至虚拟化、云计算等前沿主题,还特别提供了“参与开源社区”的实用指南,帮助新手快速融入内核生态。基于Linux 5.4内核和ARM64处理器架构的讲解,使本书对手机、服务器等ARM设备开发者更具针对性。建议可作为《Linux 内核设计与实现》的中文替代入门选择,搭配实验手册同步操作,特别适合偏好“边学边练”学习模式的读者。
《奔跑吧 Linux 内核(第 2 版)卷 1:基础架构》由张天飞执笔,主要面向具备C语言和内核基础的开发者,特别适合嵌入式及服务器方向的进阶学习。本书的核心优势在于其架构深度——专门剖析ARM64架构在Linux内核中的实现细节,从硬件交互到内核适配均有深入讲解,例如详细解析EAS调度器在ARM平台上的优化逻辑,这一内容在传统教材中极为罕见。全书采用问答式设计,每章开篇均设置高频面试题(如“ARM64如何实现内存地址转换”),引导读者带着问题研读源码,有效避免盲目啃代码的低效学习方式。基于Linux 5.0源码的细致分析覆盖了do_fork()进程创建、伙伴系统内存分配等核心流程,并明确标注具体源码路径(如kernel/sched/core.c),相较于《Linux内核源码情景分析》的旧版本内容更贴近现代内核发展。建议将本书作为《Linux内核源码情景分析》的现代补充读物,尤其适合主攻ARM平台的进阶学习者,可与内核源码目录进行一一对照阅读。
《奔跑吧 Linux 内核(第 2 版)卷 2:调试与案例分析》由笨叔执笔,专为具备一定内核开发经验、需解决实际问题的工程师量身打造,聚焦内核调试与性能优化的实战需求。本书以问题导向为核心优势,通过具体案例深入解析 Dirty COW 内存漏洞定位、OOM 杀手触发原因分析等关键技术,相较于《Professional Linux Kernel Architecture》的理论化阐述更贴近工程实践;其受众定位精准,特别适合有 RTOS 基础转向 Linux 的开发者及准备内核面试的求职者——书中案例多源自真实项目场景与高频面试题库。第二版在初版基础上持续优化,不仅补充了内核新特性详解,更修复了逻辑漏洞,使实用价值显著提升。建议搭配《Linux 设备驱动开发》同步学习,前者攻克“如何调试纠错”,后者解决“如何开发实现”,二者结合可构建完整的内核实践能力体系。

