【Python特征工程系列】使用SelectFromModel进行特征选择-基于随机森林模型(源码)
- 2026-07-05 03:16:46
这是我的第451篇原创文章。
『数据杂坛』以Python语言为核心,垂直于数据科学领域,专注于(可戳👉)Python程序设计|数据分析|特征工程|机器学习分类|机器学习回归|深度学习分类|深度学习回归|单变量时序预测|多变量时序预测|语音识别|图像识别|自然语音处理|大语言模型|软件设计开发等技术栈交流学习,涵盖数据挖掘、计算机视觉、自然语言处理等应用领域。(文末有惊喜福利)

一、引言
SelectFromModel 是一个基础分类器,其根据重要性权重选择特征。可与拟合后具有coef_或feature_importances_属性的任何估计器一起使用。如果相应的coef_或feature_importances_值低于提供的threshold参数,则这些特征可以认为不重要或者删除。除了指定数值阈值参数,还可以使用字符串参数查找阈值,参数包括:“mean”, “median” 以及这两个参数的浮点数乘积,例如“0.1*mean”。与threshold标准结合使用时,可以通过max_features参数限制选择的特征数量。
本文与随机森林模型一起,结合一个具体的二分类任务进行案例解读。
二、实现过程
2.1 数据加载
核心代码:
data = pd.read_csv(r'dataset.csv')df = pd.DataFrame(data)print(df)
结果:
2.2 提取目标变量和特征变量
核心代码:
target = 'target'features = df.columns.drop(target)X = df[features]y = df[target]
2.3 数据划分
核心代码:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)2.4 标准化特征
核心代码:
scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)
2.5 训练随机森林模型获取特征重要性
核心代码:
rf_model = RandomForestClassifier(n_estimators=100, random_state=42, max_depth=10)rf_model.fit(X_train, y_train)
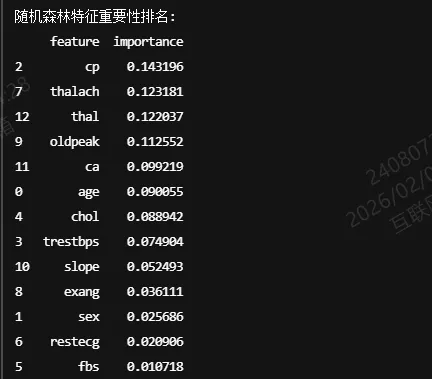
查看特征重要性:
feature_importance = pd.DataFrame({'feature': features,'importance': rf_model.feature_importances_}).sort_values('importance', ascending=False)print("\n随机森林特征重要性排名:")print(feature_importance)
结果:
2.6 使用SelectFromModel进行特征选择
方法1:使用默认阈值(均值)
selector_mean = SelectFromModel(rf_model, threshold='mean', prefit=True)X_train_selected_mean = selector_mean.transform(X_train)X_test_selected_mean = selector_mean.transform(X_test)selected_features_mean = X.columns[selector_mean.get_support()].tolist()print(f"\n使用默认阈值(mean)选择的特征 ({len(selected_features_mean)}个):")print(selected_features_mean)
结果:

方法2:使用中位数阈值
selector_median = SelectFromModel(rf_model, threshold='median', prefit=True)selected_features_median = X.columns[selector_median.get_support()].tolist()print(f"\n使用中位数阈值(median)选择的特征 ({len(selected_features_median)}个):")print(selected_features_median)
结果:

方法3:使用自定义阈值(例如:重要性 > 0.05)
selector_custom = SelectFromModel(rf_model, threshold=0.05, prefit=True)selected_features_custom = X.columns[selector_custom.get_support()].tolist()print(f"\n使用自定义阈值(0.05)选择的特征 ({len(selected_features_custom)}个):")print(selected_features_custom)
结果:

2.7 对比不同特征子集的模型性能
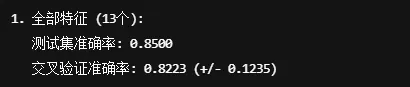
使用全部特征
results_all = evaluate_model(X_train, X_test, y_train, y_test, features)print(f"\n1. 全部特征 ({results_all['n_features']}个):")print(f" 测试集准确率: {results_all['accuracy']:.4f}")print(f" 交叉验证准确率: {results_all['cv_mean']:.4f} (+/- {results_all['cv_std']*2:.4f})")
结果:
使用SelectFromModel选择的特征(均值阈值)
results_selected = evaluate_model(X_train_selected_mean, X_test_selected_mean,y_train, y_test, selected_features_mean)print(f"\n2. SelectFromModel选择特征 ({results_selected['n_features']}个):")print(f" 测试集准确率: {results_selected['accuracy']:.4f}")print(f" 交叉验证准确率: {results_selected['cv_mean']:.4f} (+/- {results_selected['cv_std']*2:.4f})")print(f" 选择的特征: {selected_features_mean}")
结果:

2.8 可视化分析
图1:特征重要性条形图(红色为选中特征)
fig1, ax1 = plt.subplots(figsize=(10, 8))colors = ['#e74c3c' if imp > feature_importance['importance'].mean() else '#3498db'for imp in feature_importance['importance']]bars = ax1.barh(feature_importance['feature'], feature_importance['importance'], color=colors)ax1.axvline(feature_importance['importance'].mean(), color='red', linestyle='--', linewidth=2,label=f'Mean Threshold ({feature_importance["importance"].mean():.3f})')ax1.set_xlabel('Feature Importance', fontsize=12, fontweight='bold')ax1.set_ylabel('Features', fontsize=12, fontweight='bold')ax1.set_title('Random Forest Feature Importance\n(Red = Selected by Mean Threshold)',fontsize=14, fontweight='bold', pad=20)ax1.legend(loc='lower right', fontsize=10)ax1.invert_yaxis()ax1.grid(axis='x', alpha=0.3)for i, (idx, row) in enumerate(feature_importance.iterrows()):ax1.text(row['importance'] + 0.002, i, f'{row["importance"]:.3f}',va='center', fontsize=9)plt.tight_layout()plt.savefig('./fig1_feature_importance.png', dpi=150, bbox_inches='tight')plt.show()print("图1保存完成:特征重要性条形图")
结果:
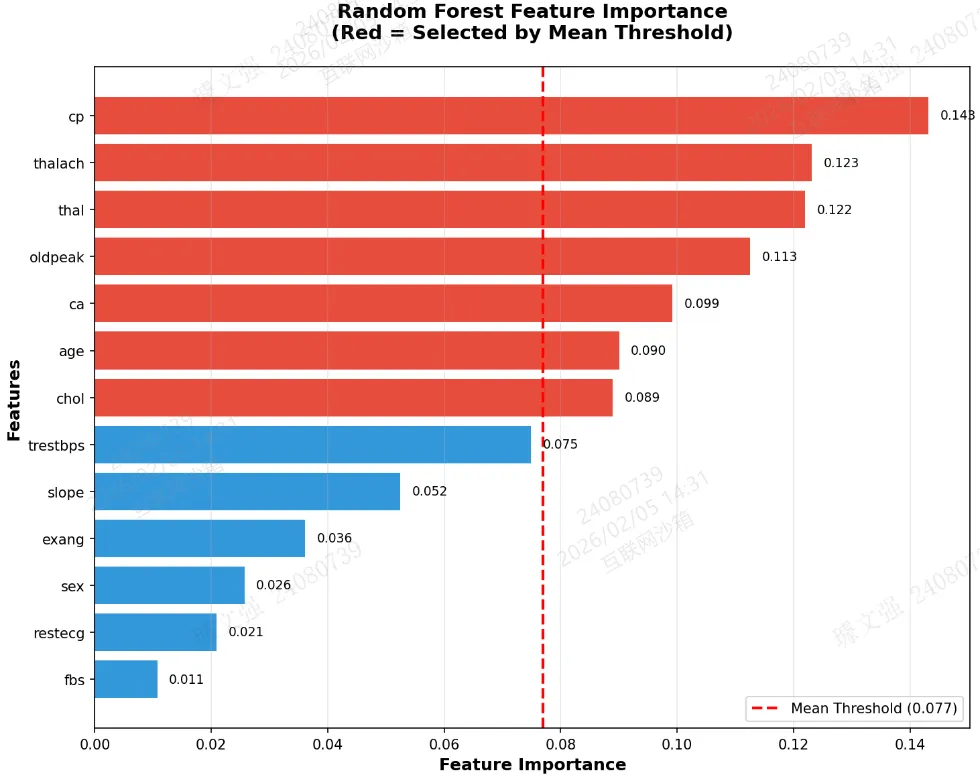
图2:不同选择方法的特征数量对比
fig2, ax2 = plt.subplots(figsize=(10, 6))methods = ['None\n(All)', 'Mean', 'Median', 'Custom\n0.05']n_features = [len(features), len(selected_features_mean), len(selected_features_median), len(selected_features_custom)]colors_bar = ['#95a5a6', '#e74c3c', '#e67e22', '#f39c12']bars = ax2.bar(methods, n_features, color=colors_bar, edgecolor='black', linewidth=1.5, width=0.6)ax2.set_ylabel('Number of Features', fontsize=12, fontweight='bold')ax2.set_xlabel('Selection Method', fontsize=12, fontweight='bold')ax2.set_title('Feature Count by Selection Method', fontsize=14, fontweight='bold', pad=20)ax2.set_ylim(0, 15)ax2.grid(axis='y', alpha=0.3)for bar, n in zip(bars, n_features):ax2.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.3,str(n), ha='center', va='bottom', fontsize=12, fontweight='bold')reductions = ['0%',"{:.2%}".format((len(features)-len(selected_features_mean))/len(features)),"{:.2%}".format((len(features)-len(selected_features_median))/len(features)),"{:.2%}".format((len(features)-len(selected_features_custom))/len(features))]for i, (bar, red) in enumerate(zip(bars, reductions)):if i > 0: # 跳过第一个ax2.text(bar.get_x() + bar.get_width()/2, bar.get_height()/2,f'↓{red}', ha='center', va='center', fontsize=10,color='white', fontweight='bold')plt.tight_layout()plt.savefig('./fig2_feature_count.png', dpi=150, bbox_inches='tight')plt.show()print("图2保存完成:特征数量对比图")
结果:
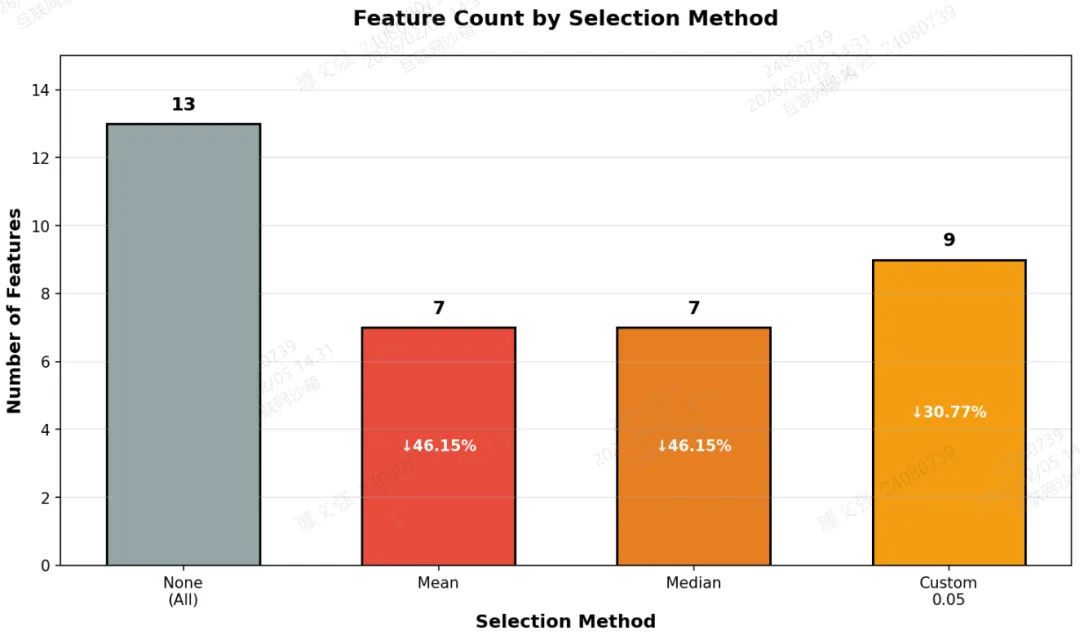
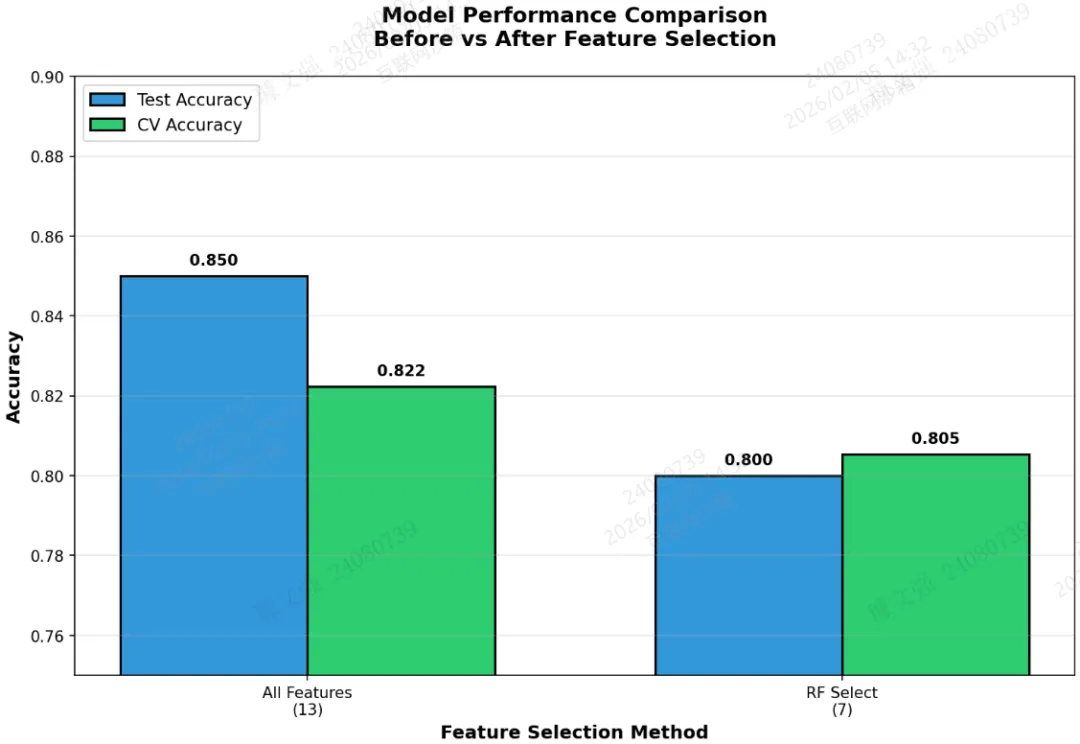
图3:模型性能对比(测试集 vs 交叉验证)
fig3, ax3 = plt.subplots(figsize=(10, 7))methods = ['All Features\n(13)', 'RF Select\n(7)']test_acc = [results_all['accuracy'], results_selected['accuracy']]cv_acc = [results_all['cv_mean'], results_selected['cv_mean']]x = np.arange(len(methods))width = 0.35bars1 = ax3.bar(x - width/2, test_acc, width, label='Test Accuracy',color='#3498db', edgecolor='black', linewidth=1.5)bars2 = ax3.bar(x + width/2, cv_acc, width, label='CV Accuracy',color='#2ecc71', edgecolor='black', linewidth=1.5)ax3.set_ylabel('Accuracy', fontsize=12, fontweight='bold')ax3.set_xlabel('Feature Selection Method', fontsize=12, fontweight='bold')ax3.set_title('Model Performance Comparison\nBefore vs After Feature Selection',fontsize=14, fontweight='bold', pad=20)ax3.set_xticks(x)ax3.set_xticklabels(methods)ax3.legend(loc='upper left', fontsize=11)ax3.set_ylim(0.75, 0.90)ax3.grid(axis='y', alpha=0.3)for bars in [bars1, bars2]:for bar in bars:height = bar.get_height()ax3.text(bar.get_x() + bar.get_width()/2., height + 0.002,f'{height:.3f}', ha='center', va='bottom', fontsize=10, fontweight='bold')plt.tight_layout()plt.savefig('./fig3_performance_comparison.png', dpi=150, bbox_inches='tight')plt.show()print("图3保存完成:模型性能对比图")
结果:
建立CNN与Transformer融合模型实现单变量时序预测(案例+源码)
建立Transformer-LSTM-TCN-XGBoost融合模型多变量时序预测(源码)
利用SHAP进行特征重要性分析-决策树模型为例(案例+源码)
梯度提升集成:LightGBM与XGBoost组合预测油耗(案例+源码)
一文教你建立随机森林-贝叶斯优化模型预测房价(案例+源码)
建立随机森林模型预测心脏疾病(完整实现过程)
建立CNN模型实现猫狗图像分类(案例+源码)
使用LSTM模型进行文本情感分析(案例+源码)
基于Flask将深度学习模型部署到web应用上(完整案例)
新版Dify 开发自定义工具插件在工作流中直接调用(完整步骤)
作者简介:
读研期间发表6篇SCI数据算法相关论文,目前在某研究院从事数据算法相关研究工作,结合自身科研实践经历不定期持续分享关于Python、数据分析、特征工程、机器学习、深度学习、人工智能系列基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
1、关注下方公众号,点击“领资料”即可免费领取电子资料书籍。
2、文章底部点击喜欢作者即可联系作者获取相关数据集和源码。
3、数据算法方向论文指导或就业指导,点击“联系我”添加作者微信直接交流。
4、有商务合作相关意向,点击“联系我”添加作者微信直接交流。


随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- JumpServer 访问 Linux(CentOS)的图形界面的配置方法
- 给Linux内核加AI助理,智能调度资源这个建议值得搞
- Linux_aarch64_head.S到main.c的环境建立
- Linux系统出现问题,如何通过诊断日志追踪问题本质
- 【80】LinuxMint LiveOS 2026最新版展示
- 第一章 linux概述
- 运维常用的 34 个 Linux Shell 脚本,一定能帮到你!
- 初学Python练题:while(八),删除为特定值的所有列表元素
- WRF模拟全套技术链实践暨Linux编译排错、FNL/ERA5驱动场处理、长时序模拟配置、下垫面改造与物理参数调整、Python诊断分析及可视化
- Linux命令新手手册:最易懂的基础命令汇总
