1. AI 时代的“数字胶水” (The Necessity in AI Era)
1.1. 生态位的垄断:作为 C++ 的高层指令指针 (IP)
任何对计算机体系结构有认知的开发者都清楚,Python 的原生性能是灾难级的。它本质上是一个基于栈的虚拟机,每一个整数加法 (a + b) 都要经历类型检查、引用计数更新 (Py_INCREF/DECREF) 和巨大的分派开销。如果你试图用纯 Python 去做矩阵乘法,CPU 的分支预测单元 (Branch Predictor) 会被你杂乱无章的指令流搞得一塌糊涂,L1/L2 Cache 也会因为散落在堆上的 PyObject 而频繁失效。
然而,AI 不需要 Python 去做计算,AI 只需要 Python 去“下令”。
在 PyTorch 或 TensorFlow 的架构中,Python 代码扮演的角色实际上是控制平面 (Control Plane),而 C++/CUDA 才是数据平面 (Data Plane)。当你写下 z = torch.matmul(x, y) 时,Python 解释器所做的仅仅是构建计算图、进行参数校验,然后将指令指针(Instruction Pointer)的控制权通过 C ABI (Application Binary Interface) 移交给底层的 C++ 动态库。
一旦进入底层,SIMD 指令集、AVX-512 甚至 GPU 的 Tensor Cores 便接管了一切。此时,Python 的那点解释器开销在耗时数毫秒甚至数秒的矩阵运算面前,完全可以忽略不计(Amdahl's Law 的反向应用)。
Trade-off 分析:
- • 换取: 极致的 C/C++ 互操作性。Python 是唯一一个能让 C++ 开发者感到“像是在写伪代码,但能无缝调用
.so 库”的语言。它是 AI 基础设施(C++)与业务逻辑(Human Logic)之间最薄的“胶水层”。
这种分层架构甚至导致了 AI 基础设施的进一步下沉。为了避免 Python 在数据预处理(如 Tokenizer、Image Decode)阶段成为瓶颈,现在的趋势是将整个数据加载管线(DataLoader)也下沉到 C++ 或 Rust 中(例如 NVIDIA DALI 或 HuggingFace Tokenizers)。Python 逐渐退化为纯粹的配置语言和胶水层。
1.2. 从计算到协同:IO 密集型的胜利
在传统的高性能计算 (HPC) 时代,我们为了减少纳秒级的延迟,不惜手写汇编优化上下文切换 (Context Switch)。但在 LLM 驱动的 Agent 时代,瓶颈发生了质的转移。
一个典型的 RAG (Retrieval-Augmented Generation) 流程或 ChatBI 系统,其 90% 的生命周期处于 Wait 状态:
- 1. 等待向量数据库检索 (Network I/O)。
- 2. 等待 LLM API Token 生成 (Network I/O)。
- 3. 等待数据库 SQL 执行结果 (Network I/O)。
此时,CPU 并不是在计算,而是在挂起。如果使用 C++,你需要处理复杂的 epoll、回调地狱或者协程库(如 boost::asio 或 C++20 coroutines),开发成本极高。
Python 在这里的优势在于其抽象成本极低。虽然 Python 的 GIL (Global Interpreter Lock) 臭名昭著,但在 IO 密集型场景下,OS 的线程调度器或者 Python 的 asyncio 事件循环(Event Loop)能很好地掩盖 CPU 的空闲。我们不再关注 TLB (Translation Lookaside Buffer) 的刷新开销,而是关注如何用最少的代码行数,编排最复杂的 API 调用链路。
1.3. 代码实现
1.3.1. 场景一:流式处理与内存友好 (The Generator)
在 C++ 中,为了避免一次性加载 10GB 的日志文件导致 OOM (Out of Memory),我们需要手写 Buffer 管理和迭代器。在 Python 中,yield 关键字本质上是一个用户态的栈帧挂起 (Stack Frame Suspension)。它允许函数在保持局部变量状态的情况下暂停执行,将控制权交还给调用者,这是一种极其廉价的“上下文切换”。
import time
import os
defraw_log_streamer(file_path: str, block_size: int = 4096):
"""
模拟 C++ 的 Buffered Reader。
不一次性读取整个文件,而是利用 Generator 机制
在用户态挂起栈帧,实现 Lazy Loading。
"""
# 这里的 file_obj 实际上是对底层文件描述符 (fd) 的封装
withopen(file_path, 'rb') as f:
whileTrue:
# 触发 syscall: read()
chunk = f.read(block_size)
ifnot chunk:
break
# 此时函数的 Stack Frame 被冻结,
# 指令指针 IP 指向下一行,局部变量保留在堆内存的 PyFrameObject 中
yield chunk
# 使用场景:处理巨大的数据集而不炸掉 RAM
# 这种写法在处理 AI 数据 Pipeline (如 DataLoader) 时是标准范式
# for data in raw_log_streamer("large_dataset.bin"):
# process(data)
1.3.2. 场景二:内核态切换 vs 用户态调度 (Threading vs Asyncio)
作为系统开发者,你必须明白 threading 和 asyncio 的本质区别:
- • Threading: 映射到 OS 的原生线程 (pthreads)。切换需要内核介入 (Kernel Trap),涉及寄存器保存、TLB 刷新,开销昂贵。且受制于 GIL,Python 多线程无法利用多核。
- • Asyncio: 单线程内的事件循环。切换只是简单的函数指针跳转 (User-space switching), 零内核上下文切换开销 (Zero Kernel Context Switch Overhead)。(注:虽然避免了昂贵的 syscall,但 Python 解释器本身的字节码分派依然有成本,但在高并发 IO 面前,这通常是划算的。)
以下代码直观展示了在 IO 密集型任务中,为什么我们需要从“线程思维”转向“协程思维”。
import threading
import asyncio
import time
# 模拟一个高延迟的 IO 操作 (例如等待 LLM 返回 token)
# 在 C++ 视角:这就是一个导致当前线程被挂起到 Wait Queue 的操作
IO_DELAY = 1.0
TASK_COUNT = 50
defheavy_io_task_sync(idx):
# 阻塞式 IO,线程被 OS 挂起
time.sleep(IO_DELAY)
asyncdefheavy_io_task_async(idx):
# 非阻塞 IO,控制权交还给 Event Loop,
# 仅仅是在 epoll/kqueue 注册了一个事件
await asyncio.sleep(IO_DELAY)
defrun_threading():
start = time.perf_counter()
threads = []
for i inrange(TASK_COUNT):
t = threading.Thread(target=heavy_io_task_sync, args=(i,))
t.start()
threads.append(t)
for t in threads:
t.join()
print(f"[Threading] Completed {TASK_COUNT} tasks in {time.perf_counter() - start:.4f}s")
# 代价:创建了 50 个 OS 线程,上下文切换开销大,内存占用高 (每个线程默认栈大小 ~8MB)
asyncdefrun_asyncio():
start = time.perf_counter()
tasks = [heavy_io_task_async(i) for i inrange(TASK_COUNT)]
# 所有的任务在一个 OS 线程内完成,无内核态切换
await asyncio.gather(*tasks)
print(f"[Asyncio] Completed {TASK_COUNT} tasks in {time.perf_counter() - start:.4f}s")
if __name__ == "__main__":
print(f"--- Benchmarking IO Concurrency (Tasks: {TASK_COUNT}) ---")
run_threading()
asyncio.run(run_asyncio())
"""
预期输出结果 (Trade-off 显而易见):
--- Benchmarking IO Concurrency (Tasks: 50) ---
[Threading] Completed 50 tasks in 1.0xxx s (加上显著的线程创建和调度开销)
[Asyncio] Completed 50 tasks in 1.00xx s (几乎仅受限于最慢的那个 IO)
"""
1.4. 总结
Python 不快,但它让“快”变得容易访问。接下来我们将深入探讨 Python 内存管理的至暗时刻: 引用计数机制 (Reference Counting) 与垃圾回收 (GC) 的代际假说,并分析为何在某些高性能场景下,我们需要手动干预这一机制以避免 "Stop-the-World"。
2. 协议层——显式的控制 (Explicit Resource Management)
如果说 C++ 的哲学是“你没有调用的东西就不需要付出代价”,那么 Python 的哲学则是“为了开发效率,你必须接受运行时开销”。在资源管理和控制流这一层,这种 Trade-off 表现得淋漓尽致。
2.1. RAII 的 Python 映射:从隐式析构到显式上下文
在 C++ 中,RAII (Resource Acquisition Is Initialization) 是资源管理的黄金法则。我们依赖栈对象的确定性生命周期:当 std::lock_guard 离开作用域时,析构函数 ~lock_guard() 会自动释放互斥锁。这一切都发生在编译期确定的汇编指令中,零运行时开销。
但在 Python 中,你面对的是一个带 GC 的运行时。对象的生命周期与作用域是解耦的。
当你写下 f = open("file.txt") 后,即使函数返回,f 指向的 PyObject 也可能因为引用计数未归零(例如被闭包捕获)或是处于循环引用中等待 GC 扫描,而迟迟不调用 __del__。
底层的真相: 依赖 __del__ 管理文件句柄或数据库连接是系统编程中的自杀行为。你无法预测 GC 何时发生(Stop-the-World),这意味着你的文件描述符 (fd) 可能会被耗尽。
为了解决这个问题,Python 引入了 上下文管理器协议 (Context Manager Protocol)——即 with 语句。
2.1.1. 协议解构:__enter__ 与 __exit__
with 语句本质上是编译器注入的 try...finally 块的语法糖,但它将资源管理的逻辑封装到了对象内部。
- •
__enter__(self): 对应 C++ 的构造逻辑。分配资源,返回句柄。 - •
__exit__(self, exc_type, exc_val, exc_tb): 对应 C++ 的析构逻辑。无论代码块是正常结束还是抛出异常,VM 都会强制跳转到这里。
代码实现:手写一个原子级锁卫士
让我们用 Python 实现一个类似 C++ std::lock_guard 的机制。注意看 __exit__ 如何处理异常传播——这是 C++ 析构函数通常极力避免的(析构抛出异常会导致 std::terminate),而在 Python 中却是控制流的一部分。
import threading
from types import TracebackType
from typing importOptional, Type
classScopedLock:
"""
模拟 C++ std::lock_guard 的 RAII 行为。
底层对应 opcode: SETUP_WITH -> ... -> WITH_EXCEPT_START / CALL_FUNCTION (__exit__)
"""
__slots__ = ('_lock',) # 内存优化:禁止 __dict__,仅分配指针大小的内存
def__init__(self, lock: threading.Lock):
self._lock = lock
def__enter__(self):
# 对应 lock.acquire(),阻塞直到获得锁
# 返回值绑定到 with ... as target 的 target
self._lock.acquire()
returnself
def__exit__(self,
exc_type: Optional[Type[BaseException]],
exc_val: Optional[BaseException],
exc_tb: Optional[TracebackType]):
# 对应 lock.release()
# 这是一个确定性的清理点,不依赖 GC
self._lock.release()
# Trade-off:
# 如果返回 True,异常被吞噬(类似 catch {...})。
# 如果返回 False 或 None,异常继续向上传播(Rethrow)。
if exc_type:
print(f"[System Logic] Detecting Unwind: {exc_type.__name__}")
# 这里可以选择处理异常,或者让它继续导致栈展开
returnFalse
# Usage
lock = threading.Lock()
with ScopedLock(lock):
# Critical Section
print("In Critical Section")
# 即使这里发生 1/0 异常,_lock.release() 依然会被精准执行
从字节码角度看,with 语句生成了 SETUP_WITH 指令,它将 __exit__ 方法压入运行时栈 (Evaluation Stack)。这比 C++ 的编译器静态插入析构调用要重得多,但它赋予了运行时动态处理异常的灵活性。
2.2. 状态机的魔法:生成器 (Generators) 与栈帧持久化
在 Java 中,如果你想实现一个惰性迭代器(Iterator),你通常需要定义一个类,维护 currentIndex 状态,并实现 hasNext() 和 next()。这是一种显式的状态机维护。
Python 的 Generator 则引入了一种更高阶的抽象:隐式状态机,或者更准确地说,用户态的栈帧挂起。
2.2.1. 核心差异:C 栈 vs. Python 栈
理解 Generator 的关键在于理解 Python 的函数调用模型:
- 1. C Stack (系统栈): Python 解释器(C程序)自身的函数调用栈。
- 2. Python Stack (虚拟栈): Python 代码执行时的栈帧 (
PyFrameObject) 链表。
关键点来了:PyFrameObject 是分配在堆(Heap)上的对象。
当你调用一个普通函数时,Python 创建一个 Frame,执行完后销毁。
但当你调用一个 Generator 函数时:
- 2. 遇到
yield 关键字时,解释器暂停该 Frame 的执行。 - 3. 保存指令指针 (f_lasti):记录当前执行到了哪条字节码。
- 5. 将控制权返回给调用者,但不销毁该 Frame。
这意味着,Generator 本质上是一个逃逸了生命周期的栈帧。
2.2.2. 代码实现:窥探挂起的内核
我们可以通过 inspect 模块直接观察这个“僵尸”栈帧的内部状态。这在 C++ 中需要 GDB 才能做到,而在 Python 中,这是语言特性的一部分。
import inspect
defstateful_execution():
"""
一个简单的生成器,演示栈帧的挂起与恢复。
"""
x = 10# 局部变量,存储在 f_locals
yield x # 第一次挂起:保存 IP,返回 10
x += 5
y = "System"
yield x + 10# 第二次挂起:返回 25
return"EOF"# 抛出 StopIteration
# 1. 创建生成器对象,此时函数体内的代码一行都还没执行
gen = stateful_execution()
# 2. 第一次激活
val1 = next(gen)
print(f"Yielded: {val1}")
# --- Hardcore Inspection ---
# 获取生成器关联的栈帧对象 (PyFrameObject)
frame = gen.gi_frame
print(f"\n[Frame Inspection]")
print(f"Instruction Pointer (f_lasti): {frame.f_lasti}") # 当前字节码偏移量
print(f"Local Variables (f_locals): {frame.f_locals}") # {'x': 10}
# 3. 恢复执行
# 解释器读取 frame.f_lasti,恢复 CPU 寄存器状态,继续执行
val2 = next(gen)
print(f"\nYielded: {val2}")
print(f"Local Variables Updated: {gen.gi_frame.f_locals}") # {'x': 15, 'y': 'System'}
2.2.3. 进化意义:从迭代器到协程
这种机制的深远意义在于,它让异步编程成为可能。
如果 yield 不仅能产出值,还能接收值(通过 gen.send()),那么这个函数就变成了一个可以通过消息传递进行协作的协程 (Coroutine)。
- • Java Iterator: 仅仅是数据的生产者。
- • Python Generator: 是一个拥有独立栈空间、可以暂停、可以恢复、可以交互的微线程。
在 Python 3.5 之前,@asyncio.coroutine 正是利用 yield from 实现的。而在 Python 3.5 之后,async/await 只是将这种基于生成器的各种黑魔法包装成了原生语法,底层的 PyFrameObject 调度逻辑依然是一脉相承的。
Trade-off 分析:
- • 性能损耗: 每次
yield 和恢复确实比简单的 C 指针递增要慢(涉及 Python 对象存取)。 - • 架构收益: 你用同步的代码逻辑(线性的
for, while),写出了极其复杂的异步流式处理逻辑。在处理数以亿计的 AI Token 流时,这种内存友好且逻辑清晰的抽象,是无价的。
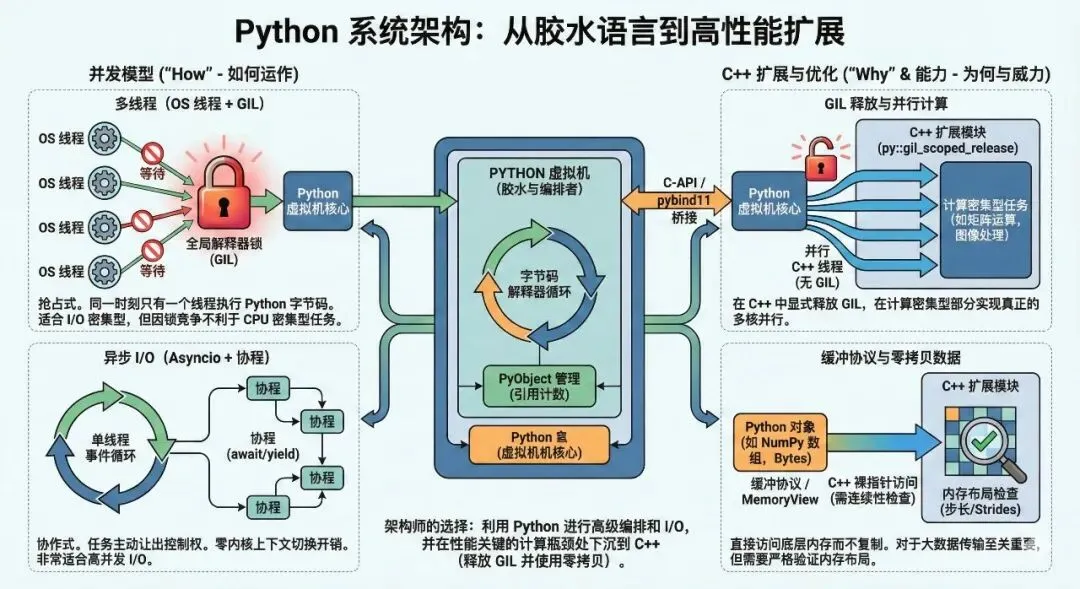
3. 枷锁层——被动的调度 (The Reality of GIL)
3.1. 内存安全的权衡:C++ 视角下的 ob_refcnt
在 C++ 中,我们使用 std::shared_ptr 来管理引用计数。为了保证线程安全,std::shared_ptr 的引用计数操作(incref/decref)内部必须使用原子操作(Atomic Operations),通常对应汇编指令 LOCK XADD。
Trade-off 的核心:
原子操作不是免费的。在多核 CPU 上,原子操作会导致缓存一致性流量(Cache Coherence Traffic)激增,这比普通的内存读写要慢一个数量级。
Python 的设计者面临一个选择:
- 1. 细粒度锁(Fine-grained Locking): 让每个
PyObject 自带一个 std::mutex,或者使用原子操作更新引用计数。
- • 后果: 单线程性能下降 30%~50%(历史实测数据)。因为即使在单线程下,你也必须支付原子操作的昂贵开销。
- 2. 巨锁(Coarse-grained Locking): 引入一把全局的大锁(GIL),保护整个解释器状态。
- • 后果: 多核并发成为泡影,多线程沦为并发(Concurrency)而非并行(Parallelism)。
- • 收益: 单线程极其高效(无锁开销),C 扩展编写极其简单(默认不需要考虑线程安全)。
Python 选择了后者。GIL 本质上是一个 互斥量 (Mutex),它保护的不是你的变量,而是 PyObject 结构体中的 ob_refcnt 字段以及解释器的全局状态。
C++ 程序员的顿悟:
GIL 的存在,是为了让 CPython 的 malloc 和 free(即 Py_INCREF/Py_DECREF)在不使用原子指令的情况下,依然能保持内存的一致性。
3.2. 竞态条件的真相:原子性的幻觉
很多初学者误以为:“既然有 GIL,同一时刻只有一个线程在跑,那我就不需要锁了。”
这是大错特错的。
GIL 保证的是字节码(Bytecode)执行的原子性,而不是业务逻辑的原子性。
操作系统(或者 Python 解释器内部的调度器)可以在任意两个字节码之间进行上下文切换。如果你的业务逻辑由多条字节码组成,那么在中间被切走就是必然发生的。
3.2.1. 代码实现:解剖 n += 1
在 C++ 中,n++ 通常也不是原子的(除非用 std::atomic<int>),它对应 Read-Modify-Write 三个步骤。Python 中亦然,但更加复杂。
让我们用 dis 模块来看看 n += 1 在底层到底发生了什么。
import dis
import threading
n = 0
defrace_condition():
global n
# 这一行看似简单的代码,在 VM 眼里是 4 条指令
n += 1
print(f"--- Bytecode Disassembly for 'n += 1' ---")
dis.dis(race_condition)
输出分析(汇编视角):
7 0 LOAD_GLOBAL 0 (n) <-- Step 1: 读取 n 到栈顶
2 LOAD_CONST 1 (1) <-- Step 2: 压入常数 1
4 INPLACE_ADD <-- Step 3: 执行加法
6 STORE_GLOBAL 0 (n) <-- Step 4: 写回 n
灾难发生的瞬间:
- 1. 线程 A 执行了
LOAD_GLOBAL,拿到了 n=0,放入自己的栈帧。 - 2. GIL 释放! (可能是时间片到了,Python 3.2+ 默认
sys.getswitchinterval() 为 5ms)。 - 3. 线程 B 获得 GIL,执行完整的
n += 1。此时内存中的 n 变成了 1。 - 5. 线程 A 继续执行
INPLACE_ADD。注意,它栈里的 n 依然是 0(因为它是从自己的栈帧中读取操作数,而不是重新去内存读)。 - 7. 线程 A 执行
STORE_GLOBAL,把 1 写入内存,覆盖了线程 B 的结果。
结果: 两个线程各加了一次,结果应该是 2,但实际是 1。这就是典型的 Lost Update 问题。
3.2.2. 多核时代的“护航效应” (The Convoy Effect)
在单核时代,GIL 只是简单的分时复用。但在多核 CPU 上,情况会变得更糟。
当持有 GIL 的线程 A 释放锁(例如因为 I/O 或强制切换)时,OS 可能会同时唤醒线程 B、C 和 D。它们会在不同的 CPU 核心上醒来,疯狂争抢这把唯一的锁。结果只有 B 抢到了,C 和 D 争抢失败,再次被 OS 挂起。
这种 “唤醒-争抢-失败-挂起” 的循环会导致严重的 CPU 抖动 (Thrashing)。这也是为什么在计算密集型任务中,Python 多线程往往比单线程还要慢——我们不仅没有利用多核,反而浪费了大量的 CPU 周期在 OS 的调度开销上。
3.2.3. 为什么必须使用 threading.Lock?
在 Python 中使用 threading.Lock,实际上是在应用层引入了第二把锁。
lock = threading.Lock()
defsafe_increment():
global n
# 申请锁:如果拿不到,线程进入阻塞状态,GIL 自动释放给别人
with lock:
# 临界区 (Critical Section)
# 即使 GIL 在这里释放,其他线程也无法进入这个代码块
# 因为它们拿不到应用层的 lock
n += 1
底层逻辑:
- • GIL 保护的是
ob_refcnt 不乱套(防止解释器崩溃)。 - • threading.Lock 保护的是
n 的值符合预期(防止业务逻辑错误)。
3.3. I/O 释放与 CPU 密集型的死局
我们常说“Python 多线程适合 I/O 密集型”,其底层机理在于:
当 Python 执行系统调用(如 read(), write(), recv(), sleep())时,C 代码会在调用阻塞的 C 函数之前,主动释放 GIL(调用 Py_BEGIN_ALLOW_THREADS 宏)。
/* CPython 源码伪代码 (socket module) */
static PyObject *
sock_recv(PySocketSockObject *s, PyObject *args)
{
// ... 解析参数 ...
// 释放 GIL,允许其他 Python 线程运行
Py_BEGIN_ALLOW_THREADS
// 阻塞的系统调用,此时 CPU 不在 Python 手里
count = recv(s->sock_fd, buffer, len, flags);
// 重新获取 GIL,准备返回 Python 对象
Py_END_ALLOW_THREADS
// ... 包装结果 ...
return result;
}
这意味着,当一个线程在等网络包时,另一个线程可以拿到 GIL 去跑 Python 代码。这就是为什么在爬虫、Web 服务中,Python 的多线程依然有效。
但如果是 CPU 密集型(如图像处理、矩阵计算),线程不会主动释放 GIL,只能等待解释器强制切换(Check Interval)。这不仅无法利用多核,反而因为频繁的锁争抢(Lock Contention)和上下文切换,导致多线程比单线程还要慢!
4. 进化层——主动的协作 (Cooperative Concurrency)
4.1. 从生成器到协程:无栈的胜利与代价
在 C++20 引入 Coroutines 之前,我们习惯用状态机手写回调。Python 的协程本质上就是编译器自动生成的有限状态机。
4.1.1. 核心对决:Python (Stackless) vs. Go (Stackful)
- • Go (Goroutine):
Go 运行时为每个 Goroutine 分配一个真实的、可增长的栈(初始约 2KB)。当 Goroutine 阻塞时,Go 的调度器保存当前的寄存器状态(SP, PC 等)到该栈中,然后切换到另一个 Goroutine。这几乎等同于用户态线程。 - • 优点: 此时,代码是同步写的,底层是异步跑的。你不需要
await,因为调度器是隐式的。 - • 缺点: 每个 Goroutine 都有内存开销(虽小但有),且需要复杂的运行时调度器。
- • Python (Coroutine):
Python 的协程被称为 无栈协程 (Stackless)。但这并不意味着它没有栈,而是指它 不保留 C 语言层面的系统调用栈。
当你 await 时,Python 仅仅是将当前的虚拟机栈帧 (PyFrameObject,一个分配在堆上的对象) 挂起,并将 C 栈回退(Unwind)到 Event Loop。相比之下,Go 的 Goroutine 是 有栈的 (Stackful),它拥有独立的、可动态扩容的连续内存空间(初始约 2KB),能保存完整的调用链路状态。
4.1.2. 异步的“传染性” (Function Coloring)
这就是为什么 Python 的异步具有传染性:
如果函数 A 调用了异步函数 B (await B()),那么 A 自身必须变成异步函数 (async def A())。
底层逻辑:
因为 Python 没有独立的协程栈,它无法在普通函数的 C 栈帧中间暂停。只有被标记为 async 的函数(即生成器),才具备“暂停-恢复”的字节码指令 (YIELD_FROM / SEND)。
这是一个巨大的 Trade-off:
- • 牺牲: 开发体验的割裂(同步代码无法直接复用异步库)。
- • 换取: 极致的轻量级。创建一个 Python 协程几乎只消耗一个 Python 对象的内存,且切换开销仅为一次函数调用,完全不涉及寄存器保存或复杂的栈拷贝。
4.2. Event Loop 的内核:Reactor 模式的 Python 实现
剥去 asyncio 华丽的封装,其核心只是一个死循环,不断查询操作系统内核:“哪些文件描述符 (fd) 准备好了?”
这正是经典的 Reactor 模式。
在 Linux 上,这对应 epoll_wait;在 macOS/BSD 上,是 kevent;在 Windows 上,是 IOCP。
4.2.1. 代码实现:手写一个 mini-asyncio
为了证明 asyncio 没有任何黑魔法,我们将绕过 asyncio 库,直接使用 selectors 模块(对 epoll/kqueue 的低级封装)来实现一个异步运行时。
C++ 开发者请注意: 下面的代码展示了如何将“回调地狱”通过生成器压平成“同步外观”。
import selectors
import socket
import time
from collections import deque
# 1. 全局事件循环 (The Reactor)
selector = selectors.DefaultSelector()
task_queue = deque() # 就绪任务队列
classFuture:
"""
对应 C++ std::future 或 JavaScript Promise。
它是异步操作结果的占位符。
"""
def__init__(self):
self.result = None
self._callbacks = []
defset_result(self, value):
self.result = value
for cb inself._callbacks:
cb(self)
def__await__(self):
# 魔法所在:yield self 告诉 Task "我还没好,请挂起"
yieldself
returnself.result
defasync_socket_read(sock):
"""
一个模拟的低级异步 socket 读取。
"""
f = Future()
defon_readable():
f.set_result(sock.recv(4096))
# 读取完毕,从 epoll 中注销
selector.unregister(sock)
# 注册到 epoll/kqueue:当 sock 可读时,调用 on_readable
# C++ 对应: epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &event)
selector.register(sock, selectors.EVENT_READ, on_readable)
# 立即返回 Future,不阻塞
return f
classTask:
"""
驱动协程执行的容器。
类似于 asyncio.Task。
"""
def__init__(self, coro):
self.coro = coro
self.step() # 启动协程
defstep(self, future=None):
try:
# 恢复协程执行:send(result)
if future isNone:
next_future = self.coro.send(None)
else:
next_future = self.coro.send(future.result)
# 协程遇到了 await,返回了一个 Future
# 我们给这个 Future 加个回调,一旦它完成了,就继续 step()
next_future._callbacks.append(self.step)
except StopIteration:
# 协程执行完毕
pass
# --- 业务逻辑 (User Code) ---
# 注意:async def 本质上是生成器工厂
asyncdeffetch_url(url):
# 模拟建立 socket
sock = socket.socket()
sock.setblocking(False)
try:
sock.connect(('example.com', 80))
except BlockingIOError:
pass# 正常现象
# 发送 HTTP 请求
req = f"GET / HTTP/1.0\r\nHost: example.com\r\n\r\n".encode()
# 简化版:这里其实也应该 await write
sock.send(req)
print(f"[{url}] Waiting for data...")
# 关键点:await 挂起当前栈帧,交出控制权
# 此时,Event Loop 可以去处理其他 Task
data = await async_socket_read(sock)
print(f"[{url}] Received {len(data)} bytes")
# --- 驱动层 (Event Loop Driver) ---
defrun_loop():
# 创建两个并发任务
Task(fetch_url("Task-A"))
Task(fetch_url("Task-B"))
print("--- Event Loop Started ---")
whileTrue:
# 1. 阻塞等待 IO 事件 (epoll_wait)
# 如果没有 IO 就绪,CPU 使用率为 0
events = selector.select()
# 2. 处理事件 (Callback Dispatch)
for key, mask in events:
callback = key.data
callback()
# 简单的退出条件
ifnot selector.get_map():
break
print("--- Event Loop Finished ---")
if __name__ == "__main__":
run_loop()
4.2.2. 深度解析:控制流的翻转
- 1. Callback (C 风格): 所有的逻辑被打散在
on_readable, on_writable 等回调函数中,状态维护极其痛苦(必须显式传递 context 指针)。 - 2. Coroutine (Python 风格):
- •
await 关键字将 async_socket_read 的 Future 抛给 Event Loop。 - • Event Loop 将
Task.step 注册为回调。 - • 当
epoll 唤醒时,通过回调触发 Task.step。 - •
Task.step 调用 coro.send(),恢复 之前挂起的 fetch_url 栈帧。
对 C++ 程序员的启示:
Python 的 asyncio 实际上是在单线程内实现了一个非抢占式操作系统。Task 是进程,Future 是系统调用,而 Event Loop 就是内核调度器。
5. 破局层——打破边界 (Extending with C++)
在前几章中,我们所有的优化都在 Python 虚拟机的围墙之内:无论是 asyncio 的用户态调度,还是 multiprocessing 的进程间通信,本质上都是在规避 GIL。
但在这一章,我们要正面击穿这堵墙。我们将编写 C++ 扩展,主动释放 GIL,让 Python 线程退化为单纯的 C++ 线程,从而压榨出 CPU 的每一个时钟周期。
当你的 Profiler(性能分析器)显示瓶颈不再是 IO 等待,而是 CPU 的 ALU(算术逻辑单元)满载时,任何 Python 层面的优化(包括 PyPy)都是隔靴搔痒。此时,唯一的出路是将计算密集型内核下沉到 C++。
5.1. 释放 GIL 的艺术:从持有者到旁观者
我们在第三章提到,Python 解释器是一个巨大的状态机,GIL 保护着这个状态机的一致性。但是,如果你的代码不涉及任何 Python 对象(PyObject)的操作,你就不需要 GIL。
比如:矩阵乘法、图像编解码、复杂的数值积分。这些操作只需要原始的内存指针(double*, uint8_t*)。
5.1.1. 协议:Py_BEGIN_ALLOW_THREADS
在 C-API 层面,Python 提供了两个宏来手动控制 GIL:
- 1.
Py_BEGIN_ALLOW_THREADS:
- • 保存当前线程的上下文(Thread State)。
- • 此时,其他 Python 线程可以抢占 GIL 并执行字节码。
- • 警告: 在此宏之后,严禁访问任何
PyObject,否则会导致立即的 Segfault 或更隐蔽的堆损坏。
- • 继续处理 Python 对象(如将 C++ 结果包装成
PyFloat)。
这就像是当你(C++ 代码)需要去进行一场漫长的闭关修炼(繁重计算)时,你主动交出了令牌(GIL),告诉解释器:“你们先玩,我算完了再回来排队。”
5.2. 实战 Pybind11:RAII 风格的锁释放
直接写 C-API 极其繁琐且容易出错(引用计数地狱)。现代 C++ 开发者应首选 pybind11。它利用 C++ 的 RAII 机制,将 GIL 的释放封装得优雅且安全。
5.2.1. 场景:多线程蒙特卡洛模拟 (CPU Bound)
假设我们需要计算 的近似值,这是一个纯计算任务。
C++ Extension (cpu_bound.cpp):
#include<pybind11/pybind11.h>
#include<random>
#include<thread>
#include<vector>
namespace py = pybind11;
// 纯 C++ 逻辑:不依赖任何 Python 头文件
doublemonte_carlo_pi(size_t samples){
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<> dis(0.0, 1.0);
size_t inside_circle = 0;
for (size_t i = 0; i < samples; ++i) {
double x = dis(gen);
double y = dis(gen);
if (x * x + y * y <= 1.0) {
inside_circle++;
}
}
return4.0 * inside_circle / samples;
}
// 包装层
doubleheavy_computation(size_t samples){
// 1. 进入 C++ 世界,持有 GIL
// 2. 释放 GIL (RAII)
// 构造函数调用 PyEval_SaveThread(),析构函数调用 PyEval_RestoreThread()
// 在这个作用域内,Python 解释器可以并发运行其他 Python 线程!
py::gil_scoped_release release;
// 3. 执行繁重的 CPU 计算
// 此时 OS 可以在多核上并行调度这个线程
double result = monte_carlo_pi(samples);
// 4. 离开作用域,自动重新获取 GIL
return result;
}
PYBIND11_MODULE(fast_calc, m) {
m.def("compute_pi", &heavy_computation, "Calculate Pi without GIL");
}
5.2.2. Python 侧的真正并行
现在,我们回到 Python。有了 py::gil_scoped_release,Python 的 threading 模块将不再是“伪多线程”。
import threading
import time
import fast_calc # 我们编译好的 C++ 扩展
SAMPLES = 10_000_000
THREAD_COUNT = 4
defworker():
# 当进入 fast_calc.compute_pi 内部时,
# GIL 被释放,该线程变成了一个纯粹的 OS 线程 (Native Thread)
# 它可以跑满一个物理 CPU 核心
pi = fast_calc.compute_pi(SAMPLES)
defrun_benchmark():
start = time.perf_counter()
threads = []
# 启动 4 个线程
for _ inrange(THREAD_COUNT):
t = threading.Thread(target=worker)
t.start()
threads.append(t)
for t in threads:
t.join()
end = time.perf_counter()
print(f"Total time: {end - start:.4f}s")
# 结果预测:
# 如果不释放 GIL:耗时约等于 sum(T_i),因为是串行执行。
# 释放 GIL 后: 耗时约等于 max(T_i),实现真正的 4 倍加速 (Amdahl's Law 允许范围内)。
5.3. 数据传输的隐形税:Buffer Protocol 与内存布局
释放 GIL 解决了计算的瓶颈,但如果你的数据还在 Python 堆上(比如一张 4K 图片),如何传给 C++?
如果你简单地定义函数为 void foo(std::vector<double> v),pybind11 会尽职尽责地遍历 Python 列表,解包每个 PyFloatObject,并发生深拷贝将数据复制到 C++ 的堆上。这不仅涉及巨大的 malloc 开销,还破坏了 CPU 缓存局部性。
解决方案:缓冲协议 (Buffer Protocol)
Python 的 memoryview、NumPy 的 ndarray 都实现了 Buffer Protocol。它允许 C++ 直接访问 Python 对象的底层内存块(Raw Buffer),实现 Zero-Copy。
然而,这里隐藏着一个巨大的陷阱:内存连续性 (Contiguity)。
Python 的切片操作(如 img[:, ::2])是零拷贝的,它仅仅是修改了元数据中的 Strides (步长),而不会重新排列内存。如果你直接把这个切片的指针拿来当成连续数组遍历,你会读到错误的数据,甚至引发 Segmentation Fault。
因此,严谨的 C++ 扩展必须检查内存布局。
5.3.1. 代码实现:安全的高性能图像反色
#include<pybind11/pybind11.h>
#include<pybind11/numpy.h>
#include<stdexcept>
namespace py = pybind11;
// C++ 接收 NumPy 数组,零拷贝 (Zero-Copy)
// 注意:py::array_t<uint8_t> 只是一个包装器,并不拥有数据的所有权
voidprocess_image(py::array_t<uint8_t> input_array){
// 1. 请求缓冲区信息 (Buffer Info)
// 这会查询对象的 __buffer__ 接口
py::buffer_info buf = input_array.request();
// 2. 维度检查
if (buf.ndim != 2) {
throw std::runtime_error("Number of dimensions must be 2");
}
// 3. [关键系统级检查] 内存布局验证
// Python 的切片可能产生不连续内存 (Non-contiguous Memory)。
// 只有当 Row Stride == Width * ElementSize 且 Col Stride == ElementSize 时,
// 我们才能将其视为一维线性数组处理。
auto expected_stride_row = buf.shape[1] * sizeof(uint8_t);
auto expected_stride_col = sizeof(uint8_t);
if (buf.strides[0] != expected_stride_row || buf.strides[1] != expected_stride_col) {
// 遇到这种情况,通常有两种选择:
// A. 抛出异常,强迫用户在 Python 端先调用 .copy() 或 np.ascontiguousarray()
// B. 在 C++ 端手动处理 strides(性能略低,但兼容性好)
// 这里为了演示极致性能,我们选择 A,拒绝处理非连续内存
throw std::runtime_error("Input array must be C-style contiguous (no slices allowed)");
}
// 4. 获取裸指针 (Raw Pointer)
// 此时我们可以安全地像操作 C 数组一样操作它
uint8_t* ptr = static_cast<uint8_t*>(buf.ptr);
size_t rows = buf.shape[0];
size_t cols = buf.shape[1];
size_t total_elements = rows * cols;
// 5. 释放 GIL 并全速计算
// 这是一个纯粹的内存读写操作,不涉及任何 Python API
{
py::gil_scoped_release release;
// 编译器现在的自动向量化 (Auto-Vectorization) 可以轻易优化这个循环
// 生成 SIMD 指令 (如 AVX2)
for (size_t i = 0; i < total_elements; ++i) {
ptr[i] = 255 - ptr[i]; // 反色操作
}
}
// 作用域结束,自动重新获取 GIL
}
PYBIND11_MODULE(fast_img, m) {
m.def("process_image", &process_image, "Invert image colors (Zero-Copy, release GIL)");
}
Python 侧调用示例:
import numpy as np
import fast_img
# 创建一个 4K 图像 (3840x2160)
img = np.random.randint(0, 256, (2160, 3840), dtype=np.uint8)
# Case 1: 正常调用 (内存连续)
# 耗时:C++ 也就是毫秒级,Python 循环则需要数秒
fast_img.process_image(img)
# Case 2: 切片调用 (内存不连续)
# slice = img[:, ::2]
# fast_img.process_image(slice)
# -> RuntimeError: Input array must be C-style contiguous
通过这种方式,我们不仅利用了 C++ 的性能,还保证了系统的鲁棒性 (Robustness)。这才是系统架构师在处理跨语言互操作时应有的思维方式。
5.4. 总结:架构师的最终抉择
至此,我们从底层的字节码(Generator)讲到了内存管理(Ref Counting),再到并发模型(Asyncio vs GIL),最后打破了语言的边界(C++ Extension)。
作为一个系统级开发者,使用 Python 的最佳姿势并非把它当作“脚本”,而是把它当作胶水:
- 1. 控制流 (Python): 处理复杂的业务逻辑、配置解析、REST API 编排。利用其动态特性和丰富的生态。
- 2. 数据流 (C++/Rust): 处理繁重的计算、大规模内存操作、低延迟 IO。利用其对硬件的掌控力。
Python is slow, but your Architecture doesn't have to be.
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
