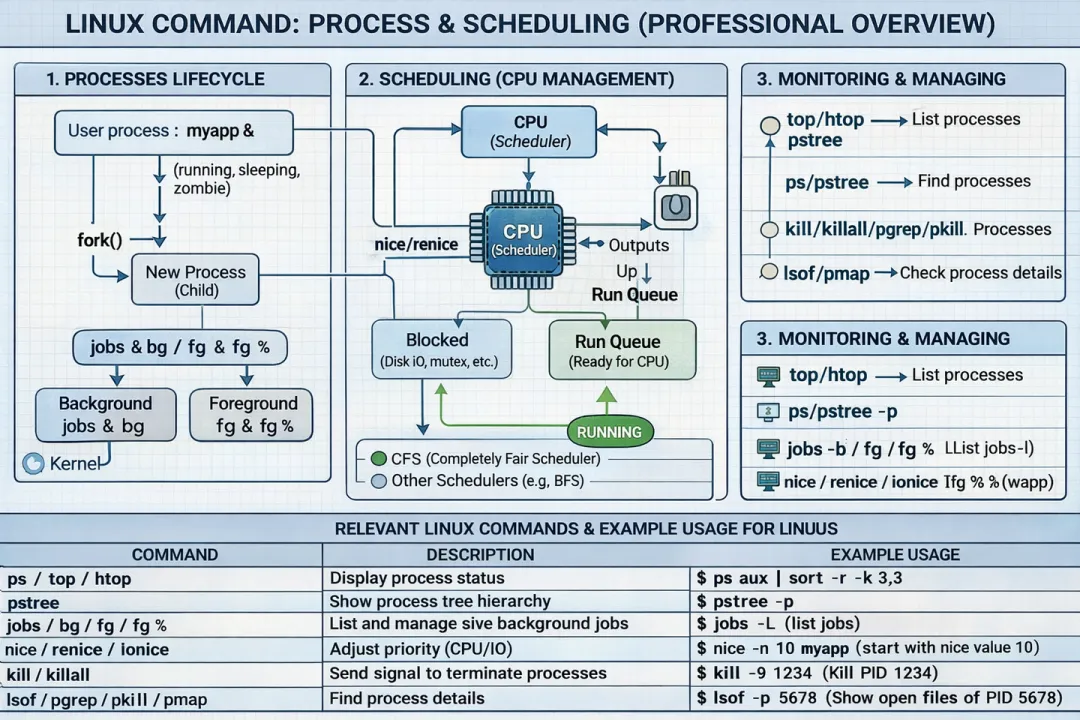
相信学习计算机的同学们,OS调度算法总是每位程序员心中的白月光
本文讲清楚: 为什么 Linux 的进程模型长成今天这样,以及调度器到底在调什么
一、一个经典误解
很多人认为:
进程 = 一个正在运行的程序
CPU 使用率 = 忙碌程度
load average = CPU 占用
这三句话,严格来说都不准确。
Linux 进程世界的真相是:
你看到的只是 task_struct 的“用户态投影”。
二、ps:一个“读文件”的进程查看器
很多人不知道:
1️. /proc 是什么?
/proc 是一个伪文件系统:
每个 PID 是一个目录
里面有:
status: 进程状态信息(易读格式);
stat: 进程状态信息(原始数据格式);
cmdline:进程的启动命令;
maps:进程的内存映射区域;
[stack]:进程的主线程栈。
[heap]:进程的堆区。
[vdso]:虚拟动态共享对象。
也就是说:
ps 只是把这些文本重新排版。
红楼梦续写作者:高鹗
2️. 为什么 ps aux 这么“怪”?
历史原因:
BSD [1]风格:ps aux
System V [2]风格:ps -ef
两个传统并存,GNU 选择全都支持。
这也是 Linux 命令常见的特征:
向历史低头,而不是清理历史。
当需要快速排查系统资源瓶颈时:使用 ps aux。例如,要找出CPU占用最高的几个进程,可以结合排序命令:
ps aux --sort=-%cpu |head
当需要分析进程的父子关系或查看完整路径时:使用 ps -ef。例如,想了解某个进程是由谁启动的,或者要确认一个服务的绝对路径。
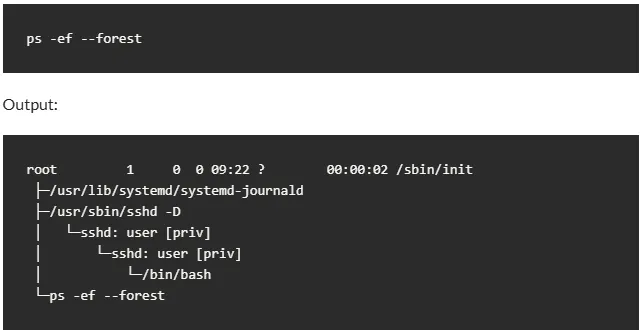
或者树形结构查看,这个命令,我喜欢用,有图有真相:ps -ef --forest树形结构输出
3️. ps 显示的状态从哪里来
$ ps aux | head -10USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 0.0 0.0 51120 2796 ? Ss Dec22 0:09 /usr/lib/systemd/systemd --system --deserialize 22root 2 0.0 0.0 0 0 ? S Dec22 0:00 [kthreadd]root 3 0.0 0.0 0 0 ? S Dec22 0:04 [ksoftirqd/0]root 5 0.0 0.0 0 0 ? S< Dec22 0:00 [kworker/0:0H]root 7 0.0 0.0 0 0 ? S Dec22 0:15 [migration/0]root 8 0.0 0.0 0 0 ? S Dec22 0:00 [rcu_bh]root 9 0.0 0.0 0 0 ? S Dec22 2:47 [rcu_sched]...saml 3015 0.0 0.0 117756 596 pts/2 Ss Dec22 0:00 bashsaml 3093 0.9 4.1 1539436 330796 ? Sl Dec22 70:16 /usr/lib64/thunderbird/thunderbirdsaml 3873 0.0 0.1 1482432 8628 ? Sl Dec22 0:02 gvim -froot 5675 0.0 0.0 124096 412 ? Ss Dec22 0:02 /usr/sbin/crond -nroot 5777 0.0 0.0 51132 1068 ? Ss Dec22 0:08 /usr/sbin/wpa_supplicant -u -f /var/log/wpa_supplicasaml 5987 0.7 1.5 1237740 119876 ? Sl Dec26 14:05 /opt/google/chrome/chrome --type=renderer --lang=en-root 6115 0.0 0.0 0 0 ? S Dec27 0:06 [kworker/0:2]
STAT 列里的:
主状态字母 (你提供的输出中出现的):
| |
|---|
| 可中断睡眠。进程正在等待某个事件(如I/O完成、信号)。这是用户进程最常见状态。 |
| 运行或可运行。进程正在CPU上执行或位于运行队列中等待调度。 |
| 不可中断睡眠。进程通常在等待磁盘I/O,不能被信号(包括kill -9)中断。 |
| |
| 高优先级。进程运行在小于0的 nice值,拥有较高的调度优先级。 |
这些都来自:
但要注意:
大部分时间,进程其实都在 S(睡眠) s会话首进程。它是一个进程组的领导者,通常是一个shell。systemd (Ss)和 bash (Ss)都是会话领导者。l多线程进程。进程使用了多线程(例如,使用了 pthreads)。t<高优先级。
这说明:
Linux 机器大部分时间都在等 IO,而不是跑计算。
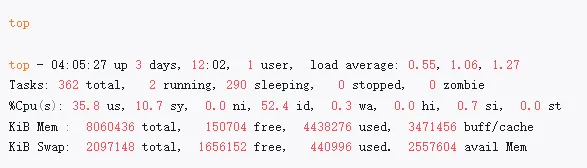
三、top:它不是“看 CPU”,它是看调度
很多人误解 top 的 CPU 百分比
1️. CPU 利用率怎么来的?
top 读的是:
/proc/stat
统计的是:
user(us+ni):CPU 执行用户空间进程的时间百分比;通常是主要部分,过高可能表示有用户进程在密集计算。
system(sy):CPU 执行内核空间代码的时间百分比;过高可能表示系统调用频繁或内核存在瓶颈。
idle(id):CPU 空闲且系统没有等待I/O的时间百分比
iowait(wa):CPU 空闲但有未完成的I/O请求在等待的时间百分比 。过高通常表示I/O设备(如磁盘)成为性能瓶颈。
irq(hi+si):CPU 处理软硬件中断的时间百分比 。
然后:
通过两次采样的差值算百分比。
这意味着:
top 看到的是“时间片分配结果”
而不是“实时 CPU 使用”
四、load average:Linux 世界最被误解的指标
输出:
load average: 3.122.982.76/*past 1 minute CPU load average: 3.12*//*past 5 minute CPU load average: 2.98*//*past 15 minute CPU load average: 2.76*/
1️. load 不是 CPU 使用率
load 表示:
处于 runnable + uninterruptible 状态的任务数量平均值。
包括:
正在运行的
等 CPU 的
等 IO 且不可中断的(D 状态)
所以:
IO 堵塞也会拉高 load
2️. 为什么是 1 / 5 / 15 分钟?
因为:
公式近似为:
load = load * e^(-t/τ) + n * (1 - e^(-t/τ))
这是一个非常“数学化”的调度指标,抛开数学。可以直观地从以下三个维度来分析:
趋势比绝对值更重要:观察三个值的关系(如 1分钟值 > 5分钟值 > 15分钟值)可以判断负载是在上升还是下降 。
需与CPU核心数结合:负载平均值需要与系统的逻辑CPU核心数进行比较。例如,一个4核CPU的系统,负载为4.0意味着CPU资源被充分利用 。
高负载的成因:负载高不仅可能是因为CPU繁忙(R状态进程多),也可能是因为大量进程在等待I/O(D状态进程多)。因此,当看到负载升高而CPU使用率不高时,排查重点应放在磁盘、网络等I/O设备上
五、nice / renice:优先级不是你想的那种优先级
1️. nice 值范围为什么是 -20 ~ 19?
历史决定:
UNIX 早期设计
负数代表“更不友好”(占用更多资源)
友好”的初衷:如你所说,nice命令的初衷是让用户进程可以主动“友好地”降低自己的优先级,将更多的CPU时间让给其他更重要的进程。因此,初始的nice值是0,表示“不调整,保持默认”。用户只能将优先级调低(设置为正的nice值,最大到19),以示“友好”。只有特权用户(如root)才能将进程调得更“贪婪”,即设置为负的nice值(最低到-20),以获取更多CPU时间。这个设计体现了系统鼓励协作而非竞争的初衷
2️. CFS 时代,nice 代表什么?
现代 Linux 使用:
CFS(完全公平调度器:Completely Fair Scheduler)
核心思想:
每个进程得到“虚拟运行时间”
调度器挑 vruntime 最小的进程
nice 实际影响的是:
不是“时间片长度”,而是:
权重比例
这和很多人理解的“优先级抢占”完全不同。
在 CFS(完全公平调度器)时代,nice值的核心角色发生了根本性的变化。它不再直接表示时间片的长度,而是作为一个权重系数,来调节进程的虚拟运行时间(vruntime) 的增长速度,从而间接但精确地决定了一个进程应获得的 CPU 时间比例。
六、Zombie:杀不掉的进程
1️. Zombie 是什么?
内核仍保留:
因为:
父进程必须有机会读取子进程的返回值
2️. 为什么 kill 不掉?
Zombie 没有运行实体:
它只是:
一个尚未被回收的 task_struct 壳。
真正该 kill 的是:
父进程。
七、一个完整链路:当你敲下一个命令
以:
为例。
实际发生:
1. shell fork()
Shell 的角色:Shell 作为父进程,fork()会创建一个与自己几乎完全相同的子进程。随后,子进程通过 execve()系统调用销毁掉从父进程继承来的代码和数据段,重新加载 /usr/bin/sleep这个可执行文件的代码和数据,从而“变身”为 sleep 进程 子进程 execve() 加入 runqueue
2. 调度器分配时间片
3. sleep 调用 nanosleep()
当 sleep 进程执行 nanosleep()时,它会从用户态陷入内核态。内核会将进程的状态从 TASK_RUNNING(运行/可运行)设置为 TASK_INTERRUPTIBLE(可中断睡眠) 。这个状态改变是核心的一步,它告诉调度器:“这个进程正在等待某个事件(在这里是时间到期),在事件发生前,请不要调度它运行”
4. 进入 TASK_INTERRUPTIBLE
5. 定时器中断唤醒
内核会设置一个高精度定时器来记录需要睡眠的时间。设置完成后,进程便会通过调用 schedule()函数主动触发一次调度,自愿放弃 CPU,这时其他在运行队列里等待的进程就可以得到执行机会了 。 定时器超时后,会触发一个中断。内核的中断处理程序会将睡眠进程的状态重新设置为 TASK_RUNNING,这表示它已经准备好了,并将其重新放回运行队列 。需要注意的是,被唤醒的进程并不会立即抢占CPU,而是要等待调度器根据自己的策略(如优先级、时间片等)选择它运行
6. 重新入队
整个过程:
完全由调度器驱动。
八、调度器到底在调什么?
现代 Linux 默认:
CFS + O(红黑树)
核心数据结构:
运行队列 runqueue:调度中枢:每个CPU核心都有一个,负责管理该CPU上所有可运行进程的调度信息,是CFS调度操作的起点和载体;
红黑树 rb_tree:调度大脑:作为一颗自平衡二叉搜索树,它挂在运行队列的cfs_rq下,以vruntime为键值,对所有可运行进程进行排序; 以后我们专门用文章,来趣谈下红黑树。
虚拟运行时间vruntime:公平的度量衡:每个进程(调度实体)都有一个vruntime。它不是真实的物理时间,而是经过进程权重(由nice值决定)加权后的时间。
目标不是:
而是:
让每个进程感觉自己独占 CPU。
这是一种“主观公平”。
九、三句你真正该记住的话
ps 不是内核接口,只是 /proc 的排版工具。
load average 统计的是“等待”,不是 CPU 使用率。
Linux 调度器追求的不是效率,而是公平。
下一篇文章,我们《趣谈 Linux 调度器:从 O(1) 到 CFS,再到 EEVDF》。
专有名词注解:
[1]BSD(Berkeley Software Distribution):由加州大学伯克利分校开发。其工具(如 ps)的选项习惯不使用短横线(-),例如 ps aux。这种风格更注重显示用户友好的资源状态信息,如CPU和内存的使用百分比。
[2]System V(AT&T System V):是AT&T开发的另一个重要Unix商业版本。其工具选项习惯使用短横线,例如 ps -ef。这种风格更侧重于展示进程的层次关系和完整的命令行信息 。
参考文献:
ps -ef Command with Practical Examples | Atlantic.Net
Linux Commands – top | Baeldung on Linux