🔗 搞懂 pandas 中的 concat、merge、join:三者到底有什么区别?
你是不是也经常困惑:
df.join() 又是什么?跟 merge 有啥不同?
别急!今天我们就用最直白的语言 + 可运行的代码,一次性讲清楚这三个“拼表”操作的区别和使用场景!
❝✅ 所有示例数据均由代码生成,无需任何外部文件,复制即用!
🧰 准备工作:导入库 + 构造示例数据
import pandas as pd# 表1:用户基本信息users = pd.DataFrame({'user_id': [1, 2, 3, 4],'name': ['Alice', 'Bob', 'Charlie', 'Diana'],'city': ['北京', '上海', '广州', '深圳']})# 表2:用户订单信息orders = pd.DataFrame({'order_id': [101, 102, 103, 104],'user_id': [1, 2, 3, 5], # 注意:user_id=5 在 users 中不存在'amount': [200, 150, 300, 99]})# 表3:用户登录日志(索引为 user_id)logins = pd.DataFrame({'last_login': ['2026-02-10', '2026-02-12', '2026-02-13', '2026-02-14']}, index=[1, 2, 3, 4]) # 索引是 user_id
现在我们有三张表:
orders:订单表(通过 user_id 关联)logins:登录日志(以 user_id 为索引)
接下来,就看它们如何“拼”在一起!
1️⃣ pd.concat():上下 or 左右“堆叠”——结构相同,直接拼接
❝🎯 适用场景:合并多个结构相似的 DataFrame(比如多个月份的销售表、多个实验结果)
示例:纵向拼接(axis=0,默认)
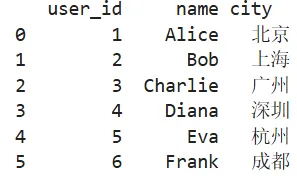
extra_users = pd.DataFrame({'user_id': [5, 6],'name': ['Eva', 'Frank'],'city': ['杭州', '成都']})all_users = pd.concat([users, extra_users], ignore_index=True)print(all_users)
✅ 输出:6 行用户数据,“堆”在一起。
示例:横向拼接(axis=1)
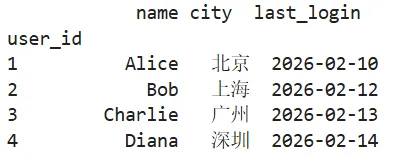
# 把 users 和 logins 按索引横向拼(需对齐索引)result = pd.concat([users.set_index('user_id'), logins], axis=1)print(result)
⚠️ 注意:concat不基于列内容匹配,只按索引或位置对齐!
❝✅ 核心特点:
2️⃣ df.merge():基于列值的“数据库式连接”——最常用!
❝🎯 适用场景:两张表通过某个公共字段(如 ID)关联,类似 SQL 的 JOIN
示例:内连接(inner join)
merged = users.merge(orders, on='user_id', how='inner')print(merged)
✅ 输出:只保留 user_id 在两张表中都存在的记录(user_id=1,2,3)
支持多种连接方式:
how='left':保留左表全部(users 全部,orders 缺失补 NaN)
还支持不同名列的连接:
# 如果 users 用 'id',orders 用 'user_id'users2 = users.rename(columns={'user_id': 'id'})result = users2.merge(orders, left_on='id', right_on='user_id')
❝✅ 核心特点:
3️⃣ df.join():基于索引的快速连接
❝🎯 适用场景:一张表的索引 = 另一张表的索引(或某列)
示例:用 users 的 user_id 作为索引,去 join logins
users_indexed = users.set_index('user_id')joined = users_indexed.join(logins) # 默认 left joinprint(joined)
✅ 输出:users 的每一行,自动匹配 logins 中对应索引的登录时间。
也可以指定右表用哪一列做索引:
# 如果 logins 不是以 user_id 为索引,而是普通列logins2 = pd.DataFrame({'user_id': [1, 2, 3, 4],'last_login': ['2026-02-10', '2026-02-12', '2026-02-13', '2026-02-14']})# 需先设索引joined2 = users_indexed.join(logins2.set_index('user_id'))
❝✅ 核心特点:
- 本质是
merge 的快捷方式(join 底层调用 merge)
🆚 三者对比速查表
| | | | |
|---|
pd.concat() | | | | |
df.merge() | | | | |
df.join() | | | | |
💡 使用建议
- 想把多个月的报表合并成一年? → 用
concat - 你的主表已经用
ID 设为索引,想快速加一列信息? → 用 join
❝🌟 记住一句话:“concat 是堆叠,merge 是匹配,join 是索引对齐。”
📦 结语
掌握 concat、merge、join 的区别,是迈向高效数据处理的关键一步!下次再遇到“怎么把两张表合起来”的问题,先问自己:👉 我是要堆数据?还是按字段匹配?还是按索引补充信息?
❤️ 觉得有用?点赞 + 在看 + 转发,让更多人告别“拼表混乱”!


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
