风控规则挖掘:二维交叉表、多维决策树、Python实操...
- 2026-07-04 01:45:58
风控规则挖掘:二维交叉表、多维决策树、Python实操...一、交叉表介绍 1.1. 交叉表的概念 什么是交叉表? 交叉表,顾名思义,就是两个或者两个以上的变量进行交叉判断。 比如下面这个示例,一个变量是“最近6个月新开信贷账户数”,另一个变量是“当前公积金状态”,这就是两个变量的交叉表形式,也叫“二维交叉表”,如果是两个以上的变量就是“多维交叉表”。 交叉表的形成,本质上就是变量的“笛卡尔积”。 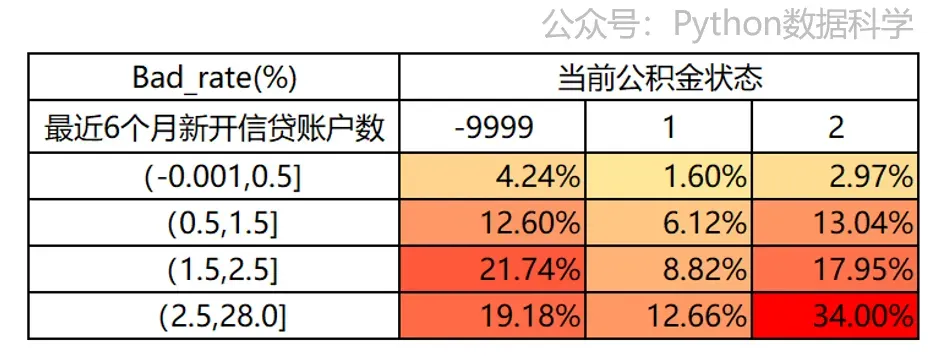
交叉表有什么特点? 按照规则的复杂度和数据维度两个角度来看,交叉表规则处于单变量规则和评分卡模型之间的中间形态。 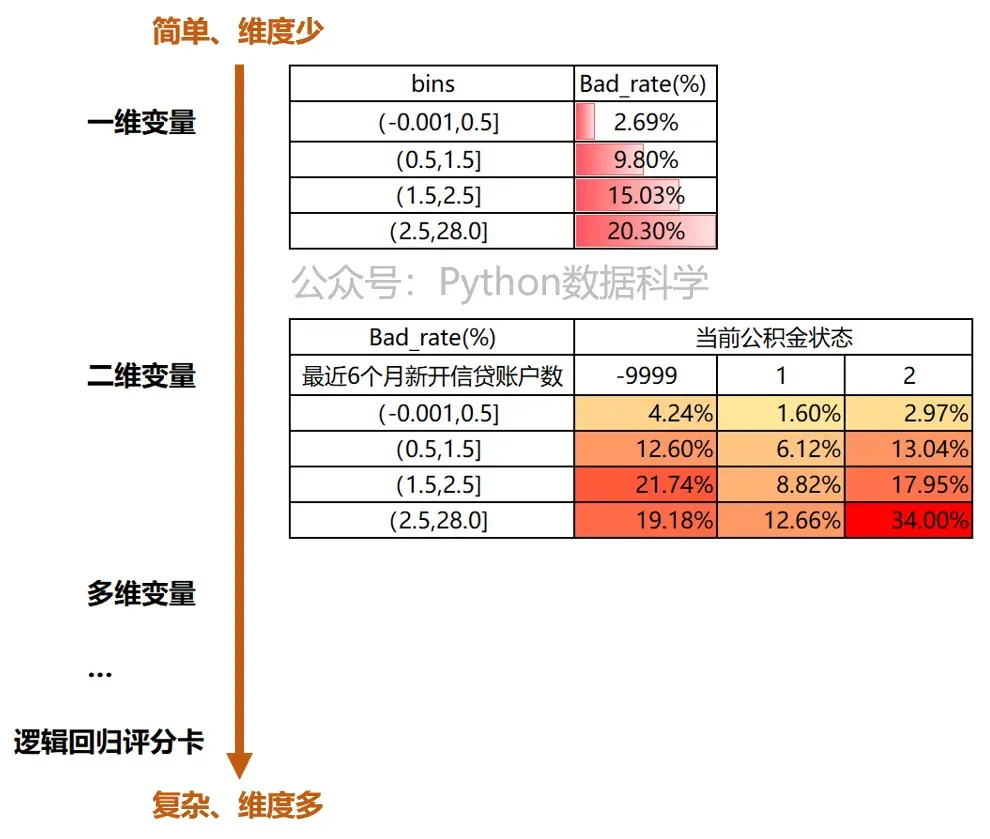
要生成二维交叉表,有3个前提条件: 1)基于IV筛选出预测效果好的变量池,从中选择交叉所需的变量组。 一般的原则是:交叉变量最好是不同维度的,且相互间的相关性不高,这样综合效果才会达到最优。 2)对变量进行分箱操作,连续型变量需要有排序性; 仍以下面的二维交叉表为例,我们看到“最近6个月新开信贷账户数”是连续型变量,“当前公积金状态” 是离散性变量。这里公积金状态有三个离散值,因此不需要分箱;而最近6个月新开账户数由于是连续型变量,是需要做分箱处理的。 3)总样本和坏样本数量足够多。 交叉表通过两两组合,有更多的格子。比如下面一维变量只有4个格子,而二维交叉表有12个格子,而总数量和总坏客户数是相同的,那么经过稀释后交叉表的每个格子数据量会变少。如果总样本数和坏客户数不够的话,那么分散到每个格子的数量就可能出现过少,或者没有数据的情况,导致无统计意义无法分析。因此如要保证每个格子都有足够的数据,总样本和坏样本数就必须足够多。 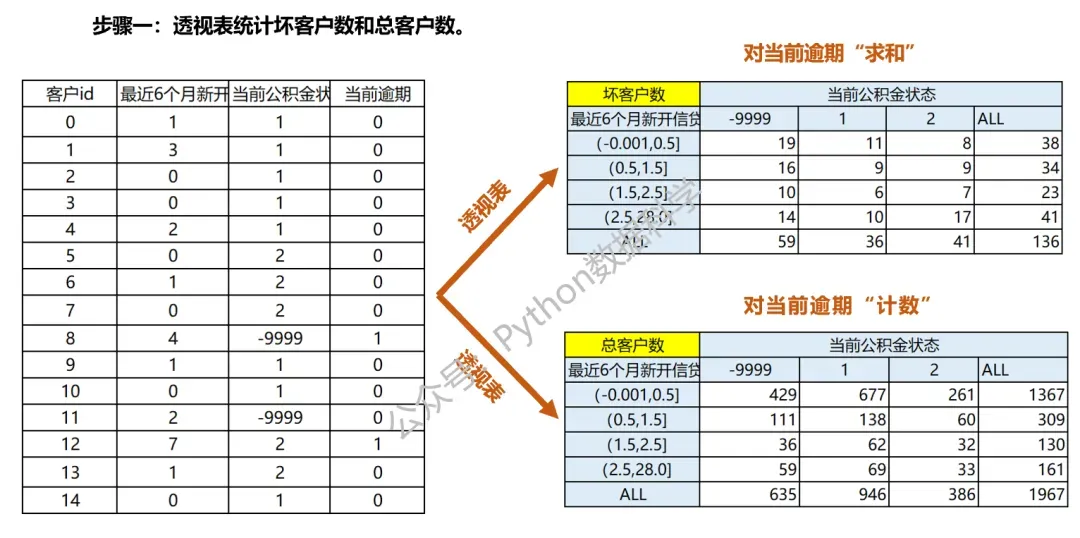
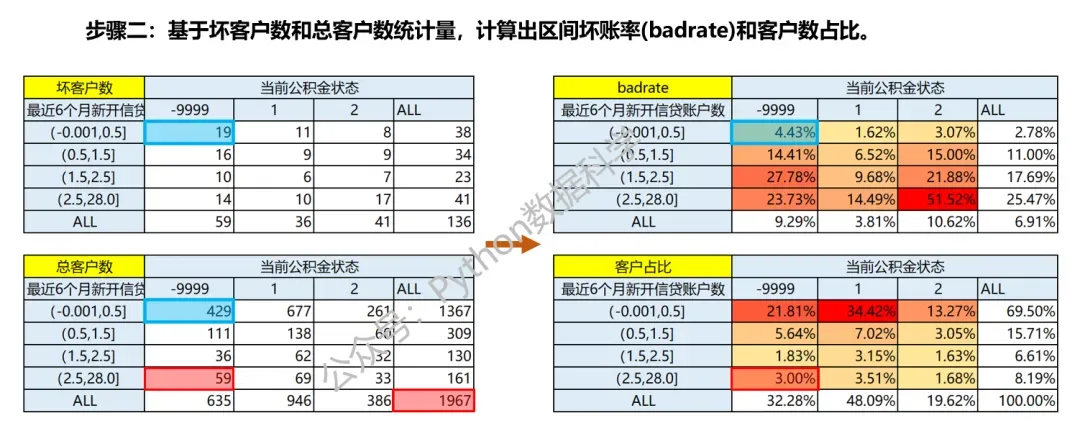
区间坏账率=每个格子的坏客户数/对应格子的总客户数,是上下两个交叉表每个格子对应位置的计算,比如蓝色框示例,4.43%=19/429; 客户占比=每个格子的客户数/总客户数,只需总客户数一个交叉表即可,比如红色框示例,3%=59/1967; 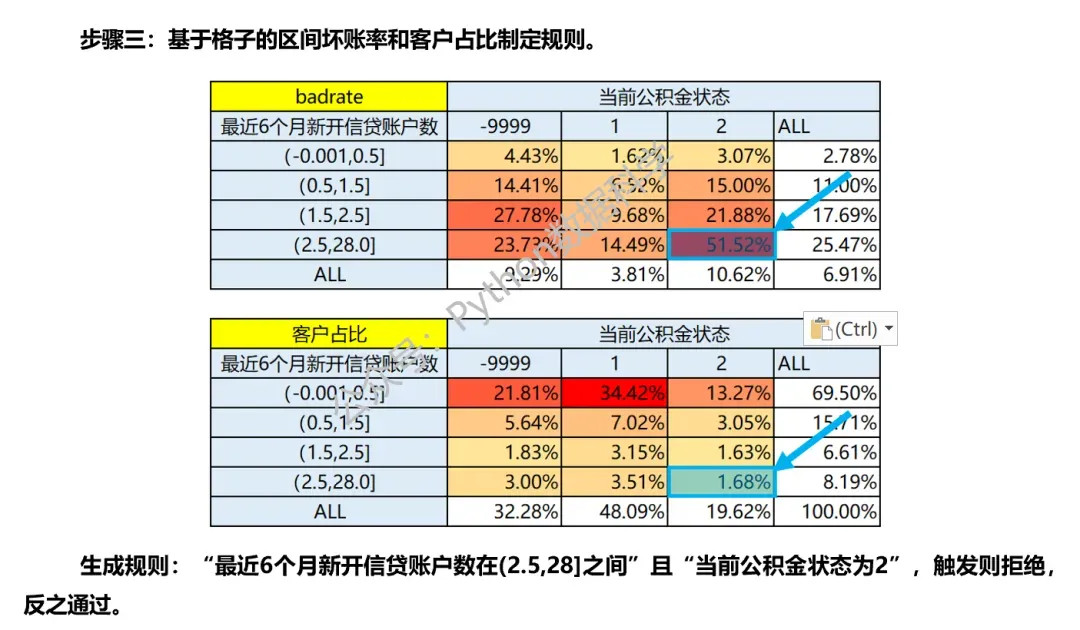
交叉表完整Python代码等实操内容请看👉《100天风控专家》 二、决策树挖掘多维规则 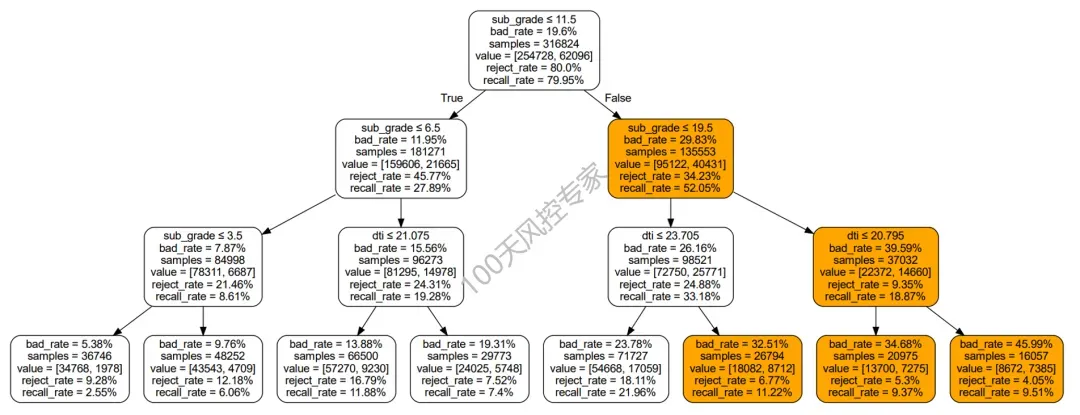
Sklearn中有两个决策树API方法,分别是: 要注意的是, 
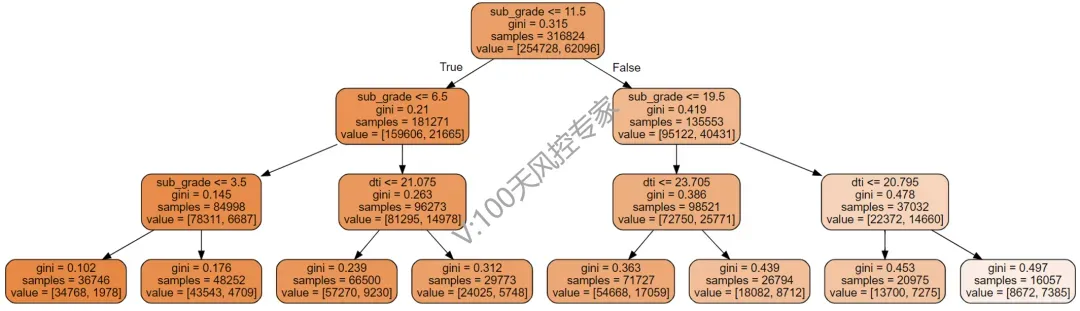
在信贷风控中,使用决策树生成规则后要通过命中、精准率、召回率等指标进行评估和筛选,而sklearn模型输出的树节点可视化图不包含这些信息,下面提供一种优化方法,可以输出我们想要的结果。 该方法仍然使用 以上代码返回的dot_data是一个长字符串,如下示例,该字符串包含了树分裂的所有分裂点和叶子节点信息。 
首先,也需要使用
决策树完整Python代码等实操内容请看👉《100天风控专家》 以上。
规则策略是风控策略人员日常打交道的一项工作内容,如何有效挖掘出有价值的规则对于风险拦截至关重要。本次介绍除了单规则以外的,二维、以及多维规则的挖掘方法,内容节选自👉《100天风控专家》。
1.2. 交叉表的特点
与单变量规则相比,交叉表拥有更多的维度,对于客户风险评估更加准确。 与评分卡模型相比,交叉表虽变量维度少,但复杂度更低,迭代开发速度更快。 在所有的工具中,交叉表属于一种中间的形态,同时兼顾了维度和复杂度两点。
1.3. 交叉表的前置条件
2.1. 交叉表规则生成(1):透视表
2.2. 交叉表规则生成(2):计算指标
2.3. 交叉表规则生成(3):制定和评估
1.sklearn决策树
tree.DecisionTreeClassifier:CART分类树 tree.DecisionTreeRegressor:CART回归树
Sklearn没有对ID3和C4.5算法的实现,就只有CART算法,并且是调优过的。下面是官方文档的说明。X = df[df.columns.difference([yflag,'issue_d','address','emp_title','earliest_cr_line','title'])]y = df[yflag]# 划分数据集x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42)# 按照最优的方式分裂model=tree.DecisionTreeClassifier(criterion="gini", splitter='best', random_state=42, max_depth=3, min_samples_leaf=0.05, min_samples_split=0.05)model = model.fit(x_train,y_train)dot_data=tree.export_graphviz(model, feature_names=X.columns, filled=True, rounded=True, out_file=None)graph=graphviz.Source(dot_data)graph
2.可视化更新
export_graphviz可视化方法,但会在此基础上做一些内容的优化调整。dot_data = tree.export_graphviz(tree_model)
3.Python代码实操
首先,也需要使用DecisionTreeClassifier或者DecisionTreeRegressor构建一个决策树模型对象。
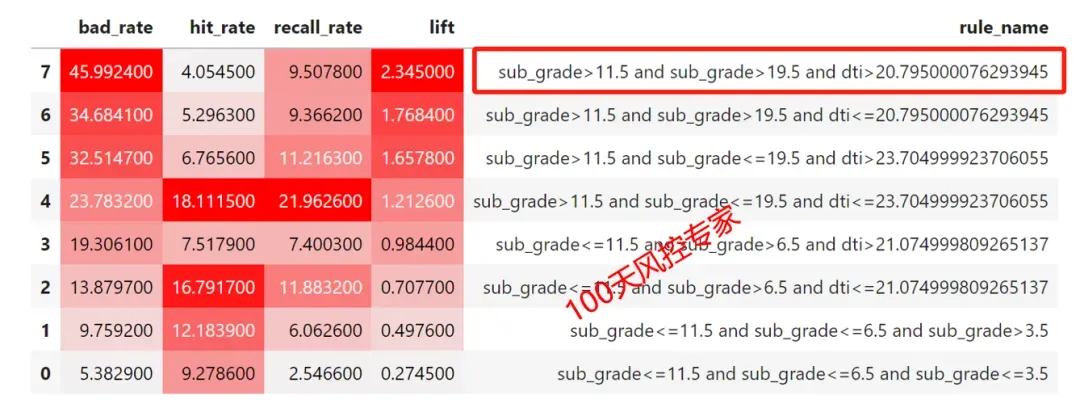
X = df[df.columns.difference([yflag,'issue_d','address','emp_title','earliest_cr_line','title'])]y = df[yflag]# 划分数据集x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42)# 按照最优的方式分裂model=tree.DecisionTreeClassifier(criterion="gini", splitter='best', random_state=42, max_depth=3, min_samples_leaf=0.05, min_samples_split=0.05)model = model.fit(x_train,y_train)...这里要我们设置的决策树深度为3,并且树结构生成完整,因此生成的规则中均包含3个变量,8条决策路径总共生成8条规则,具体如下:
规则是用来高风险客户的,因此先对精准率进行从大到小的排序,然然后再看命中率、召回率等是否符合要求。
--end--
从0到1的信贷风控训练营

本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux基础 | 效率提升神器: alias命令详解
- Python实现7大常用优化算法
- iOS 版 UTM 安装 Alpine Linux 虚拟机:跑 Docker、用 SSH、与 iOS 共享文件夹
- UV包管理工具全攻略,一个工具搞定Python开发全流程
- Python:lambda 表达式详解
- 【Python学习】Pycharm快捷键大全
- 从零开始学Python必看的三本书(附电子版)
- 从零开始学Python必看的三本书(附电子版)
- Monty:微秒启动的 Python 解释器,让 AI 安全执行代码
- Monty:微秒启动的 Python 解释器,让 AI 安全执行代码
