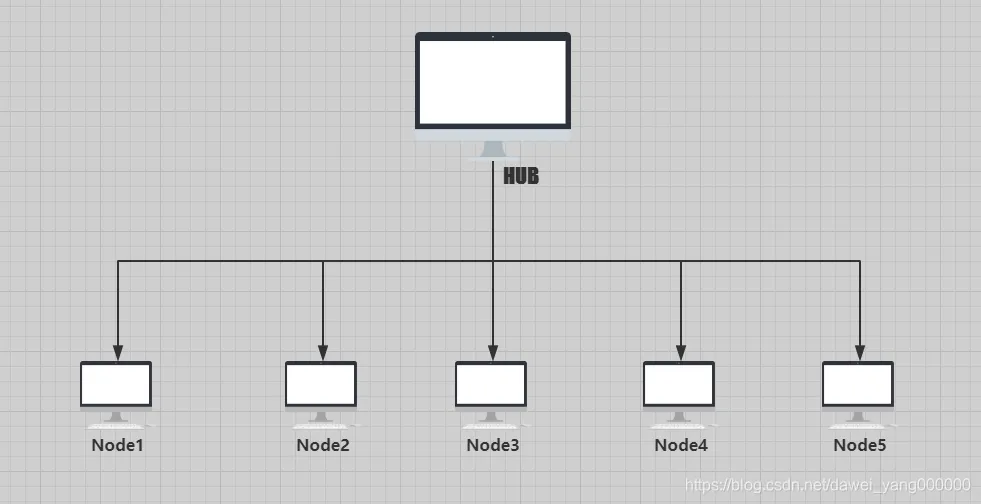
分布式自动化测试是指将自动化测试任务分发到多个不同的计算节点(机器/虚拟机/容器)上并行执行,最后再汇总测试结果的过程传统方式:一个工人(一台机器)一条一条地顺序执行成千上万个测试用例,耗时极长。分布式方式:一个工头(调度中心)将测试任务池拆分成多份,分给一群工人(多个节点)同时干活,大大缩短总耗时。核心目标:缩短测试反馈周期,提高测试效率,实现快速验证和持续交付分布式自动化实际上的应用场景非常多,例如兼容性测试场景/稳定性场景等等,它可以轻松实现一份代码驱动若干终端执行自动化分布式执行测试用例,也就是我们在一台机器上执行代码,通过Selenium Grid的机制它会驱动与之关联的多台机器执行相同的任务或者不同的任务,如图所示,一台机器我们称之为HUB,被驱动的机器我们称之为Node1、Node2和Node3## 环境配置
### 下载安装配置JDK
### selenium-server-standalone下载与运行
- 首先启动命令行并运行命令“pipshowselenium”,查看机器上的Selenium版本
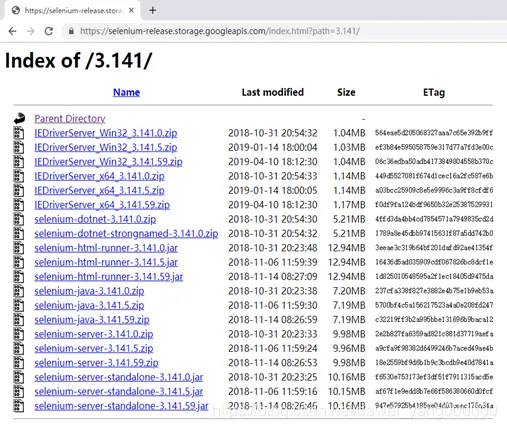
- 然后通过地址https://selenium-release.storage.googleapis.com/index.html下载与Selenium版本相同的selenium-server-standalone
## HUB与Node
整个Selenium Grid的环境中HUB机器作为中枢,是个指令集散地,我们要通过它将执行任务的指令分发到各个Node机器上去完成任务### 启动HUB
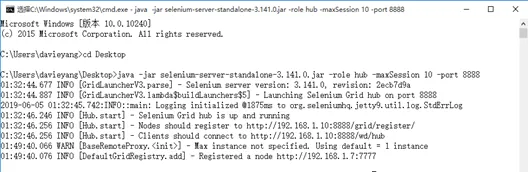
启动命令行,然后将命令行的路径引导到存放selenium-server-standalone路径下并输入如下命令启动HUB```Java –jar selenium-server-standalone-3.141.0.jar –role hub –maxSession 10 –port 8888```- role hub表示我们启动的是hub不是node
- maxSession 10表示最大的会话请求是10个
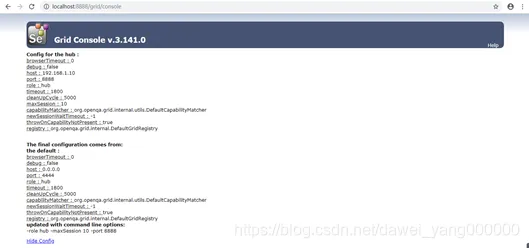
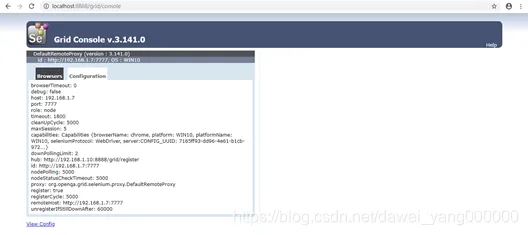
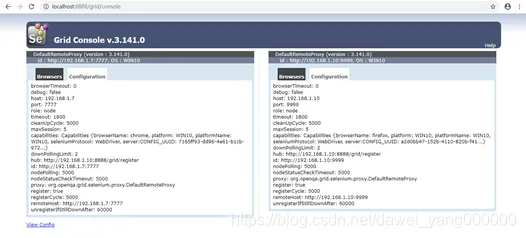
启动成功后,用浏览器打开地址http://localhost:8888/grid/console,能看到页面如图所示,此时因为没有任何Node链接,我们只能看到一个HUB自身的Config信息### HUB端Selenium-Server-Standalone参数
- role hub表示当前启动的是HUB不是Node
- hubConfig jsonFile可以将参数放到json文件中,用该参数将json文件引入到命令行
- newSessionWaitTimeout指定新的测试session等待执行的时间间隔,默认为-1
### 启动Node
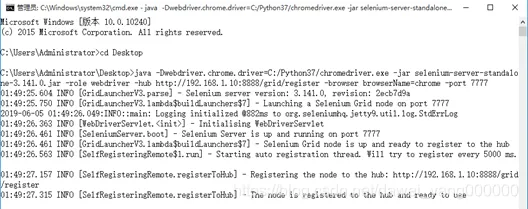
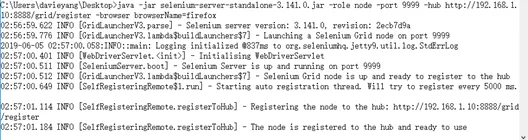
Node既可以是另外一台机器,也可以和HUB是同一个机器,如果Node是另外一个机器,那么它也需要跟HUB机器一样的基础环境,需要安装Pyhton、Selenium、JDK和Selenium-Server-Standalone.xx.jar等等,保持和HUB机器环境一样即可。既然是分布式,自然实际情况中Node大多数情况下会是新的机器,在Node机器中配置好基础环境后,启动命令行,将命令行路径引导到selenium-server-standalone所在路径下,然后执行如下命令配置Chrome浏览器,如图所示,则表示执行成功Java –Dwebdriver.chrome.driver=C:/Python37/chromedriver.exe –jar selenium-server-standalone-3.141.0.jar –role webdriver –hub http://192.168.1.10:8888/grid/register -browser browserName=chrome -port 7777
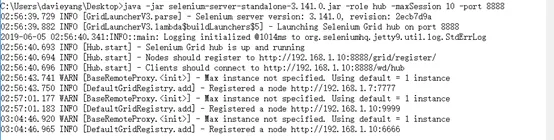
回过头来我们在HUB机器的命令行中,新增了一条Registered a node的信息再看一下http://localhost:8888/grid/console页面,新增了我们的Node机器的信息### Node端启动Selenium-Server-Standalone参数
- portNode端远程连接端口号,也是Node端监听的端口号
- role node表示可支持所有版本的Seleniu
- role wd表示不支持Selenium1,也可以直接写成webdriver
- timeout HUB端在无法收到Node的注册地址时,在该时间后会释放和Node节点的链接。
- hub hub_urlNode节点需要与HUB完成注册,此参数为Node链接HUB的注册地址
- browser Node机器上允许使用的浏览器/browserName:浏览器名称/maxInstances:最多允许启动的浏览器个数
- nodeConfig jsonFileNode端的参数配置可放在json文件中,然后使用该参数引入到命令中
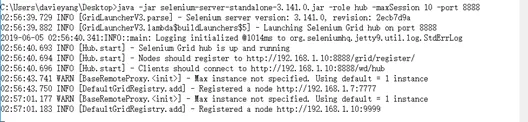
在另一个Node机器上配置Firefox浏览器,启动命令行,将命令行路径引导到selenium-server-standalone所在路径下,然后执行如下命令java -jar selenium-server-standalone-3.141.0.jar -role node -port 7777 -hub http://192.168.1.10:8888/grid/register -maxSession 5 -browser browserName=firefox,seleniumProtocol=WebDriver,maxInstances=5 –port 9999
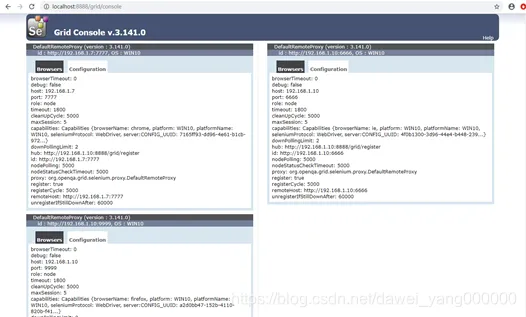
回过头我们再看一下HUB的控制台,又新增了一条Register a node信息再看一下http://localhost:8888/grid/console页面,新增了我们的Node机器的信息使用同样的方法在Node机器上配置IE浏览器,启动命令行,将命令行路径引导到selenium-server-standalone所在路径下,然后执行如下命令Java –Dwebdriver.chrome.driver=C:/Python37/ IEDriverServer.exe –jar selenium-server-standalone-3.141.0.jar –role webdriver –hub http://192.168.1.10:8888/grid/register -browser browserName=ie -port 6666
回过头我们再看一下HUB的控制台,又新增了一条Register a node信息看一下http://localhost:8888/grid/console页面,新增了我们的Node机器的信息实际上无论是在HUB端还是在Node端,如果链接出了问题是会在控制台输出相关信息的## 分布式测试
coding=utf-8from selenium import webdriverchrome_driver = "C:/Python37/chromedriver.exe"chrome_capabilities = {# 浏览器名称"browserName": "chrome", # 操作系统版本"version": "", # 平台,这里可以是windows、linux等等"platform": "ANY", # 是否启用js "javascriptEnabled": True, "webdriver.chrome.driver": chrome_driver}driver=webdriver.Remote("http://192.168.1.7:7777/wd/hub",desired_capabilities=chrome_capabilities)driver.get("http://www.baidu.com")print(driver.title)driver.quit()