linux管道
#管道介绍 在 Linux 系统中,管道(Pipe)是一种强大且常用的机制,用于在不同的命令之间传递数据。管道是一种进程间通信(IPC)的方式,它允许将一个命令的标准输出直接作为另一个命令的标准输入。通过管道,可以将多个简单的命令组合起来,形成功能强大、复杂的操作。 #工作原理 管道在内存中创建一个缓冲区,第一个命令(生产者)将输出数据写入这个缓冲区,第二个命令(消费者)从缓冲区中读取数据作为输入。这样,数据就可以在不同的命令之间依次传递和处理,而不需要将中间结果保存到磁盘文件中。
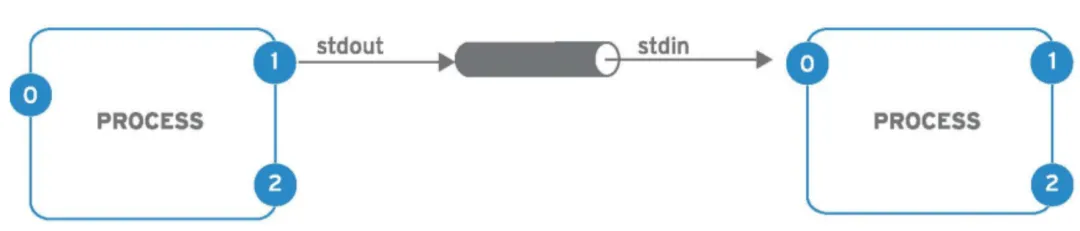
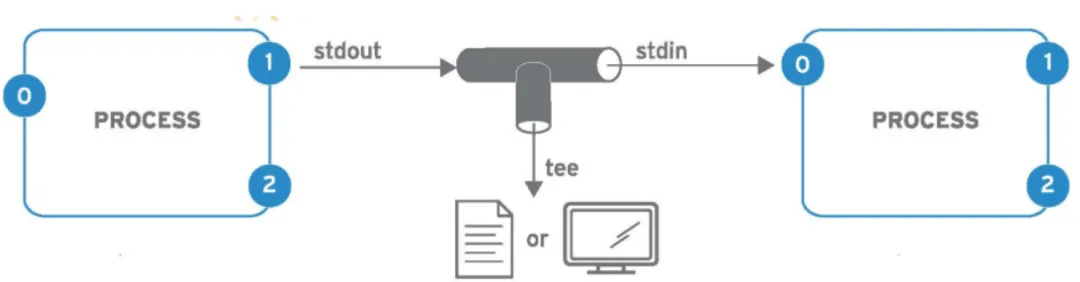
#使用方法 在 Linux 中,管道使用竖线符号 |来表示。基本语法如下: command1|command2|command3 ... #单重管道示例-筛选ip地址的行 使用 ip address 命令查看ip地址,然后通过管道将其输出传递给 grep 命令进行筛选: [root@centos79-68-78 ~]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope hostvalid_lft forever preferred_lft forever 2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:50:56:be:4e:0a brd ff:ff:ff:ff:ff:ff inet 172.16.68.78/23 brd 172.16.69.255 scope global noprefixroute ens192 valid_lft forever preferred_lft forever inet6 fe80::250:56ff:febe:4e0a/64 scope link noprefixroutevalid_lft forever preferred_lft forever [root@centos79-68-78 ~]# ip a|grep inet inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope hostinet 172.16.68.78/23 brd 172.16.69.255 scope global noprefixroute ens192 inet6 fe80::250:56ff:febe:4e0a/64 scope link noprefixroute#多重管道示例-筛选ip地址和网卡名称 [root@centos79-68-78 ~]# ip address |grep"inet "|awk'{print $NF,$2}'|grep lo -v ens192 172.16.68.78/23 #tee命令 tee命令主要功能是从标准输入读取数据,并将这些数据同时输出到标准输出(通常是终端屏幕)和一个或多个文件中。在执行复杂命令或脚本时,使用 tee 可以方便地记录命令的输出结果,同时在屏幕上查看执行情况。 -a(--append):以追加模式打开文件,若文件已存在,新的数据会添加到文件末尾,而非覆盖原有内容。 -i(--ignore-interrupts):忽略中断信号,在执行过程中即使收到中断信号(如 Ctrl + C),tee 也不会停止。 [root@centos79-68-78 ~]# ls -l|tee /tmp/saved-output1 /tmp/saved-output2 total 16 -rw-------. 1 root root 4966 Feb6 17:51 anaconda-ks.cfg -rw-------. 1 root root 4276 Feb6 17:51 original-ks.cfg [root@centos79-68-78 ~]# cat /tmp/saved-output1 total 16 -rw-------. 1 root root 4966 Feb6 17:51 anaconda-ks.cfg -rw-------. 1 root root 4276 Feb6 17:51 original-ks.cfg [root@centos79-68-78 ~]# cat /tmp/saved-output2 total 16 -rw-------. 1 root root 4966 Feb6 17:51 anaconda-ks.cfg -rw-------. 1 root root 4276 Feb6 17:51 original-ks.cfg
#xargs命令 xargs命令主要功能是从标准输入读取数据,然后将这些数据拆分成一个个参数,传递给其他命令进行处理。 在 Linux 里,很多命令无法直接从标准输入接收多个参数,只能以命令行参数的形式接收。xargs 命令就起到了一个桥梁的作用,它会读取标准输入的数据,默认以空格、制表符或换行符作为分隔符,将数据分割成多个参数,再把这些参数传递给指定的命令执行。 command|xargs[选项][其他命令][root@centos79-68-78 ~]# ll /usr/local/src/ total 24 -rw-r--r-- 1 root root45 Feb 12 17:46 data.txt -rw-r--r-- 1 root root88 Feb 12 14:18 file -rw-r--r-- 1 root root12 Feb 12 10:21 file1 -rw-r--r-- 1 root root18 Feb 12 10:22 file2 -rw-r--r-- 1 root root48 Feb 12 17:33 students.txt -rw-r--r-- 1 root root 127 Feb 12 15:17 test.txt [root@centos79-68-78 ~]# ls -p /usr/local/src/ |grep-v / |xargs-I {} cp /usr/local/src/{} /test/ [root@centos79-68-78 ~]# ll /test/ total 24 -rw-r--r-- 1 root root45 Feb 14 21:37 data.txt -rw-r--r-- 1 root root88 Feb 14 21:37 file -rw-r--r-- 1 root root12 Feb 14 21:37 file1 -rw-r--r-- 1 root root18 Feb 14 21:37 file2 -rw-r--r-- 1 root root48 Feb 14 21:37 students.txt -rw-r--r-- 1 root root 127 Feb 14 21:37 test.txt #适合管道的一些linux命令 1.wc wc英文全称为"word count",主要用于统计文件中的行数、单词数和字节数。 -l:仅统计行数。 -w:仅统计单词数。 -c:仅统计字节数。 -m:统计字符数,在某些字符编码下,字符数和字节数可能不同。 -L:显示文件中最长行的长度。 2.sort sort 命令可以对文件或标准输入的内容进行排序,并将排序结果输出。 若不指定文件,sort 会从标准输入读取内容进行排序;若指定了一个或多个文件,sort 会对这些文件的内容 进行排序。 默认情况下,sort 按字典序对文本行进行排序。 假设 words.txt 文件内容如下 cat>> words.txt << END banana apple cherry END [root@centos79-68-78 src]# sort words.txt apple banana cherry 使用-r 选项可以实现逆序排序,即从大到小排序 使用-n 选项可以按数字大小进行排序,而不是按字典序 使用-f 选项可以忽略大小写进行排序 使用-u 选项可以在排序的同时去除重复的行 3.uniq uniq 英文全称为 “unique”,它能够帮助用户对文本数据进行清理和整理,使输出结果更加简洁。 uniq[选项] [输入文件 [输出文件]] 若不指定输入文件,uniq 会从标准输入读取内容;若不指定输出文件,处理结果会输出到标准输出。 -c:在每行前加上该行在文件中出现的次数。 -d:只输出重复的行。 -u:只输出不重复的行。 -i:忽略大小写进行比较。 假设存在一个名为 test.txt 的文件,内容如下: cat>> test.txt << END apple apple banana cherry cherry cherry END 使用 uniq 命令去除相邻的重复行: [root@centos79-68-78 src]# uniq test.txt apple banana cherry 统计重复行的数量 [root@centos79-68-78 src]# uniq -c test.txt 2 apple 1 banana 3 cherry 只输出重复的行[root@centos79-68-78 src]# uniq -d test.txt apple cherry 只输出不重复的行 [root@centos79-68-78 src]# uniq -u test.txt banana 假设 test1.txt 文件内容为: cat>> test1.txt << END Apple apple banana Cherry cherry END 使用-i 选项忽略大小写进行比较: [root@centos79-68-78 src]# uniq -i-c test1.txt 2 Apple 1 banana 2 Cherry uniq 命令只能去除相邻的重复行,如果文件中的重复行不相邻,需要先使用 sort 命令对文件进行排序,再 使用 uniq 命令。例如: sort test.txt |uniq 在处理日志文件时,去除重复的日志记录,使日志更加简洁,便于分析。 在处理大量数据时,去除重复的数据行,提高数据的质量和处理效率。 4.tr tr 是 Linux 和类 Unix 系统中一个用于字符转换、删除和压缩的命令,其英文全称为 “translate”。它 可以对标准输入的字符进行替换、删除或压缩等操作,并将结果输出到标准输出。 tr[选项]'字符集1''字符集2'字符集1 是需要被转换或删除的字符集合,字符集2 是用于替换 字符集1 中字符的字符集合。若只指定 字符 集1 而不指定 字符集2,tr 会删除输入中所有属于 字符集1 的字符。 将输入中的小写字母转换为大写字母 [root@centos79-68-78 src]#echo "hello world"|tr'a-z''A-Z'HELLO WORLD 删除输入中的所有数字 [root@centos79-68-78 src]# echo "abc123def"|tr-d'0-9'abcdef 压缩输入中连续重复的空格为单个空格 [root@centos79-68-78 src]# echo "helloworld"|tr-s' 'hello world 将输入中除了数字以外的所有字符替换为 X [root@centos79-68-78 src]# echo "abc123def"|tr-c'0-9''X'XXX123XXXX tr 支持使用字符类来表示一组字符,例如 [:upper:] 表示所有大写字母,[:lower:] 表示所有小写字 母,[:digit:] 表示所有数字等 [root@centos79-68-78 src]# echo "HELLO WORLD"|tr'[:upper:]''[:lower:]'hello world
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
