方法 | 功能说明 | 字段 = 代码(生产级,含空值保护) | 示例 |
`find()` | 查找子串**第一次**出现的起始索引,找不到返回 `-1`(不报错) | `!字段!.find(u"子串") if !字段! is not None else -1` | 输入 `u"北京公园路"` → 输出 `2` |
`rfind()` | 查找子串**最后一次**出现的起始索引,找不到返回 `-1` | `!字段!.rfind(u"子串") if !字段! is not None else -1` | 输入 `u"C:\\data\\file.shp"` → 输出 `7` |
`index()` | 同 `find()`,但**找不到会报错**(慎用) | `!字段!.index(u"子串") if !字段! is not None else ""` | 输入 `u"北京公园路"` → 输出 `2` |
`rindex()` | 同 `rfind()`,但**找不到会报错**(慎用) | `!字段!.rindex(u"子串") if !字段! is not None else ""` | 输入 `u"C:\\data\\file.shp"` → 输出 `7` |
`isalnum()` | 判断字符串是否**只包含字母或数字** | `!字段!.isalnum() if !字段! is not None else False` | 输入 `u"A123"` → 输出 `True` |
`isalpha()` | 判断字符串是否**只包含字母** | `!字段!.isalpha() if !字段! is not None else False` | 输入 `u"Hello"` → 输出 `True` |
`isdigit()` | 判断字符串是否**只包含数字** | `!字段!.isdigit() if !字段! is not None else False` | 输入 `u"123"` → 输出 `True` |
`islower()` | 判断字符串是否**全为小写字母** | `!字段!.islower() if !字段! is not None else False` | 输入 `u"hello"` → 输出 `True` |
`isspace()` | 判断字符串是否**只包含空白字符**(空格/制表符/换行) | `!字段!.isspace() if !字段! is not None else False` | 输入 `u""` → 输出 `True` |
`istitle()` | 判断字符串是否为**标题格式**(每个单词首字母大写) | `!字段!.istitle() if !字段! is not None else False` | 输入 `u"Hello World"` → 输出 `True` |
`isupper()` | 判断字符串是否**全为大写字母** | `!字段!.isupper() if !字段! is not None else False` | 输入 `u"HELLO"` → 输出 `True` |
`lower()` | 将字符串转换为**全小写** | `!字段!.lower() if !字段! is not None else u""` | 输入 `u"HELLO"` → 输出 `u"hello"` |
`upper()` | 将字符串转换为**全大写** | `!字段!.upper() if !字段! is not None else u""` | 输入 `u"hello"` → 输出 `u"HELLO"` |
`swapcase()` | 将字符串中的**大小写互换** | `!字段!.swapcase() if !字段! is not None else u""` | 输入 `u"Hello"` → 输出 `u"hELLO"` |
`title()` | 将字符串转换为**标题格式**(每个单词首字母大写) | `!字段!.title() if !字段! is not None else u""` | 输入 `u"hello world"` → 输出 `u"Hello World"` |
`strip()` | 去除字符串**左右两侧**的空白字符(或指定字符) | `!字段!.strip() if !字段! is not None else u""` | 输入 `u"公园"` → 输出 `u"公园"` |
`lstrip()` | 去除字符串**左侧**的空白字符(或指定字符) | `!字段!.lstrip() if !字段! is not None else u""` | 输入 `u"公园"` → 输出 `u"公园"` |
`rstrip()` | 去除字符串**右侧**的空白字符(或指定字符) | `!字段!.rstrip() if !字段! is not None else u""` | 输入 `u"公园"` → 输出 `u"公园"` |
`ljust()` | 将字符串**左对齐**,右侧用指定字符填充至目标长度 | `!字段!.ljust(5, "0") if !字段! is not None else u""` | 输入 `u"A1"` → 输出 `u"A1000"` |
`rjust()` | 将字符串**右对齐**,左侧用指定字符填充至目标长度 | `!字段!.rjust(5, "0") if !字段! is not None else u""` | 输入 `u"A1"` → 输出 `u"000A1"` |
`zfill()` | 将字符串**左侧补0**至指定长度(专门用于数字字符串) | `!字段!.zfill(5) if !字段! is not None else u""` | 输入 `u"123"` → 输出 `u"00123"` |
`split()` | 按指定分隔符**从左往右**分割字符串,取指定部分 | `!字段!.split(u"分隔符")[0] if !字段! is not None else u""` | 输入 `u"吉林省四平市"` → 输出 `u"吉林省"` |
`rsplit()` | 按指定分隔符**从右往左**分割字符串,取指定部分 | `!字段!.rsplit(u".", 1)[1] if !字段! is not None else u""` | 输入 `u"map.shp"` → 输出 `u"shp"` |
`splitlines()` | 按**换行符**分割字符串,取指定行 | `!字段!.splitlines()[0] if !字段! is not None else u""` | 输入 `u"第一行\n第二行"` → 输出 `u"第一行"` |
`partition()` | 按指定分隔符将字符串分成**3部分**(分隔符前、分隔符、分隔符后),取分隔符后内容 | `!字段!.partition(u":")[2] if !字段! is not None else u""` | 输入 `u"名称:公园"` → 输出 `u"公园"` |
`rpartition()` | 从右往左按指定分隔符将字符串分成**3部分**,取分隔符后内容 | `!字段!.rpartition("\\\\")[2] if !字段! is not None else u""` | 输入 `u"C:\\data\\file.shp"` → 输出 `u"file.shp"` |
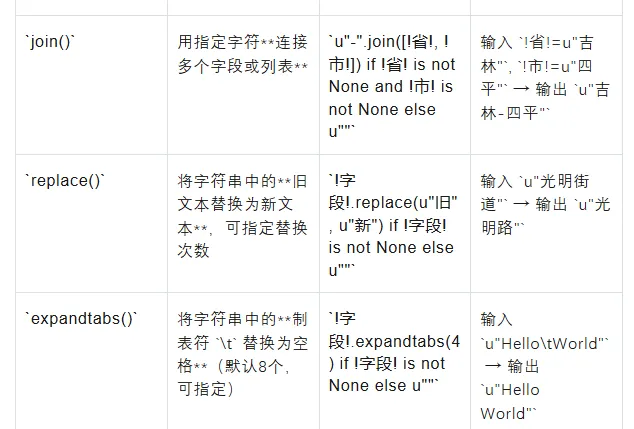
`join()` | 用指定字符**连接多个字段或列表** | `u"-".join([!省!, !市!]) if !省! is not None and !市! is not None else u""` | 输入 `!省!=u"吉林"`, `!市!=u"四平"` → 输出 `u"吉林-四平"` |
`replace()` | 将字符串中的**旧文本替换为新文本**,可指定替换次数 | `!字段!.replace(u"旧", u"新") if !字段! is not None else u""` | 输入 `u"光明街道"` → 输出 `u"光明路"` |
`expandtabs()` | 将字符串中的**制表符 `\t` 替换为空格**(默认8个,可指定) | `!字段!.expandtabs(4) if !字段! is not None else u""` | 输入 `u"Hello\tWorld"` → 输出 `u"HelloWorld"` |
`format()` | 格式化**拼接多个字段**(推荐用 `{}` 占位符) | `u"{}-{}".format(!省!, !市!) if !省! is not None and !市! is not None else u""` | 输入 `!省!=u"吉林"`, `!市!=u"四平"` → 输出 `u"吉林-四平"` |
`len()` | 返回字符串的**长度**(字符个数) | `len(!字段!) if !字段! is not None else 0` | 输入 `u"吉林省四平市"` → 输出 `6` |
`str()` | 将对象(如数字)**转换为字符串**(常用于拼接) | `u"ID_" + str(!OBJECTID!) if !OBJECTID! is not None else u""` | 输入 `!OBJECTID!=1` → 输出 `u"ID_1"` |