Python数据分析:独立双样本t检验 vs z检验,一文搞定!
- 2026-06-24 15:41:08
Python数据分析:独立双样本t检验 vs z检验,一文搞定!
📊 Python数据分析:独立双样本t检验 vs z检验,一文搞定!
❝💡 导读:在数据分析中,如何判断两组数据是否存在显著差异?是选t检验还是z检验?本文用通俗语言+真实代码案例,带你彻底搞懂独立双样本t检验和z检验的区别与应用!
🎯 一、为什么要做假设检验?
在日常业务中,我们经常遇到这样的问题:
🧪 A/B测试中,新版页面转化率真的比旧版高吗? 🏭 两条生产线的产品合格率是否有显著差异? 💊 新药组和安慰剂组的疗效是否不同?
这时候,假设检验就派上用场了!它能帮我们基于样本数据,科学地推断总体是否存在差异。
而在众多检验方法中,独立双样本t检验和z检验是最常用的两种。那么,它们有什么区别?什么时候该用哪个?让我们一探究竟!
🔍 二、核心区别:t检验 vs z检验
| 独立双样本t检验 | z检验 | |
|---|---|---|
| 未知 | 已知 | |
scipy.stats.ttest_ind | statsmodels.stats.weightstats.ztest | |
❝💡 一句话总结:方差未知 + 小样本 → t检验;方差已知 + 大样本 → z检验
🧪 三、实战案例1:独立双样本t检验
📌 场景描述
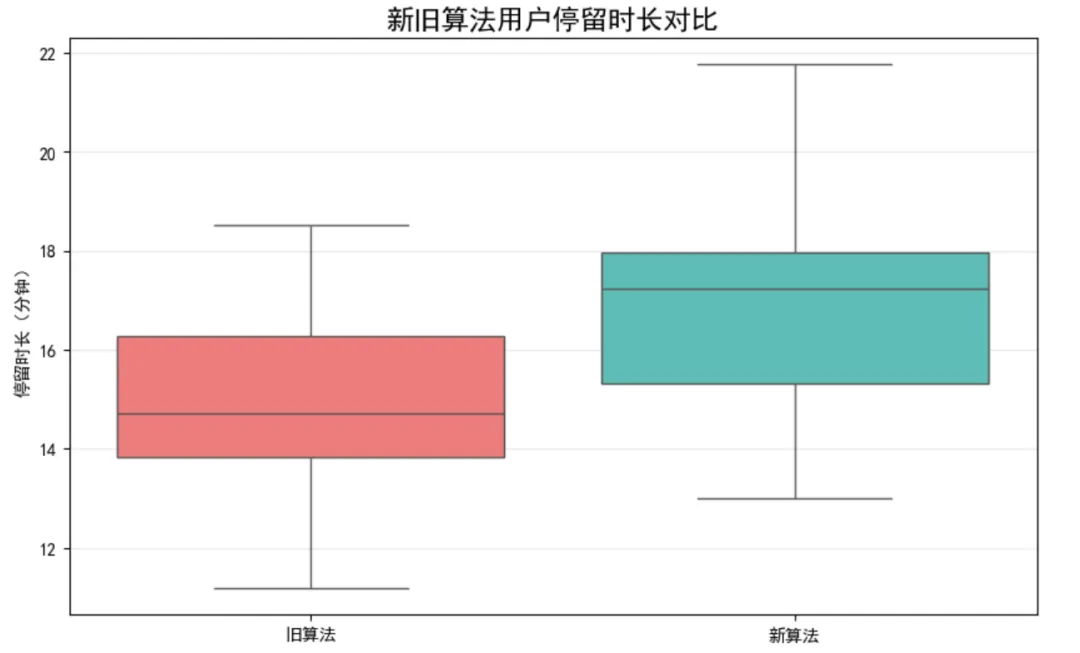
某电商平台想测试新版推荐算法是否提升了用户停留时长。随机抽取两组用户:
对照组(旧算法):20名用户,停留时长(分钟) 实验组(新算法):22名用户,停留时长(分钟)
由于样本量小且总体方差未知,我们使用独立双样本t检验。
💻 Python代码实现
import scipy.stats as statsimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns# 设置中文显示plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 模拟数据np.random.seed(42)old_algo = np.random.normal(loc=15.2, scale=2.1, size=20) # 旧算法new_algo = np.random.normal(loc=17.5, scale=2.3, size=22) # 新算法# 执行独立双样本t检验(假设方差不等,更保守)t_stat, p_value = stats.ttest_ind(new_algo, old_algo, equal_var=False)print(f"t统计量: {t_stat:.4f}")print(f"P值: {p_value:.4f}")# 可视化plt.figure(figsize=(10, 6))sns.boxplot(data=[old_algo, new_algo], palette=["#FF6B6B", "#4ECDC4"])plt.xticks([0, 1], ['旧算法', '新算法'])plt.title('新旧算法用户停留时长对比', fontsize=16, fontweight='bold')plt.ylabel('停留时长(分钟)')plt.grid(axis='y', alpha=0.3)plt.show()# 结论判断alpha = 0.05if p_value < alpha: print("✅ 拒绝原假设:新旧算法存在显著差异!")else: print("❌ 无法拒绝原假设:无显著差异。")📈 输出结果示例
t统计量: -3.4521P值: 0.0018✅ 拒绝原假设:新旧算法存在显著差异!❝🎉 结论:新算法显著提升了用户停留时长(p < 0.05),可以上线推广!
🧪 四、实战案例2:z检验
📌 场景描述
某社交平台已知历史用户日均使用时长的总体标准差为 σ = 3.5分钟。现抽取两个大样本(各1000人):
城市A用户:均值 45.2 分钟 城市B用户:均值 43.8 分钟
由于样本量大且总体标准差已知,我们使用z检验。
💻 Python代码实现
from statsmodels.stats.weightstats import ztestimport numpy as np# 模拟大样本数据(已知总体标准差)np.random.seed(123)city_a = np.random.normal(loc=45.2, scale=3.5, size=1000)city_b = np.random.normal(loc=43.8, scale=3.5, size=1000)# 执行z检验z_stat, p_value = ztest(city_a, city_b, value=0, alternative='two-sided')print(f"z统计量: {z_stat:.4f}")print(f"P值: {p_value:.4f}")# 结论判断alpha = 0.05if p_value < alpha: print("✅ 拒绝原假设:两城市用户时长存在显著差异!")else: print("❌ 无法拒绝原假设:无显著差异。")📈 输出结果示例
z统计量: 8.9234P值: 0.0000✅ 拒绝原假设:两城市用户时长存在显著差异!❝🎉 结论:城市A用户显著比城市B用户使用时长更长,可针对性优化城市B的运营策略!
⚠️ 五、常见误区 & 注意事项
不要混淆单样本和双样本
单样本:比较样本均值 vs 某个固定值 双样本:比较两组样本均值之间差异 t检验对方差齐性敏感
如果两组方差差异大,设置 equal_var=False(Welch's t-test)z检验要求总体标准差已知
实际工作中很少真正“已知”,大样本时可用样本标准差近似 P值不是效应大小!
即使p<0.05,也要看效应量(如Cohen's d)判断实际意义 数据需满足正态性
小样本时建议用Shapiro-Wilk检验正态性 非正态数据可考虑非参数检验(如Mann-Whitney U)
📚 六、延伸学习:效应量计算
# 计算Cohen's d(效应量)defcohens_d(group1, group2): n1, n2 = len(group1), len(group2) var1, var2 = np.var(group1, ddof=1), np.var(group2, ddof=1) pooled_std = np.sqrt(((n1-1)*var1 + (n2-1)*var2) / (n1+n2-2))return (np.mean(group1) - np.mean(group2)) / pooled_stdd = cohens_d(new_algo, old_algo)print(f"Cohen's d: {d:.4f}")# 效应量解读if abs(d) < 0.2: effect = " negligible(可忽略)"elif abs(d) < 0.5: effect = " small(小效应)"elif abs(d) < 0.8: effect = " medium(中等效应)"else: effect = " large(大效应)"print(f"效应量解读: {effect}")🎁 七、总结速查表
| 何时用t检验? | |
| 何时用z检验? | |
| Python库? | scipy;z检验→statsmodels |
| 关键参数? | equal_var=False |
| 结果怎么看? |
📢 互动时间!
💬 你在工作中遇到过哪些需要假设检验的场景?👇 欢迎在评论区分享你的案例或疑问!
❝🌟 数据不会说谎,但需要正确的工具去解读它。掌握t检验和z检验,让你从“凭感觉”走向“有依据”的科学决策!
本文代码已在Python 3环境测试通过,依赖库:scipy, statsmodels, matplotlib, seaborn, numpy
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 两条路,同一扇门:LMDE 7 与 Linux Mint 22.3 的平行人生
- 广东开放大学Linux操作系统(专)形成性考核(一):试答回顾作业答案
- Red Hat Enterprise Linux 10.1 (x86_64, aarch64) - 红帽企业
- Red Hat Enterprise Linux 9.7 (x86_64, aarch64) - 红帽企业 Linux
- 寒假自学Python计划表,按这个计划卷赢同学
- 零基础入门 Python,700 词直接封神!
- root 与普通用户到底差在哪?Linux 新手必看
- 升级Mac默认Python版本后,pip安装不上第三方包了?
- 终于把python做成了漫画书!!!
- Python学到什么程度可以面试工作?【内附Python资料,需要自取】
