【Qwen3-Max】
太棒了!欢迎来到 【跟着AI学Python】第25天 —— 简单 Web 爬虫入门!🎉今天我们将学习如何用 requests + BeautifulSoup 从网页中安全、合法地提取信息!
⚠️ 重要前提:
- 遵守网站
robots.txt(如https://example.com/robots.txt) - 不要高频请求,避免给服务器造成压力
🎯 第25天目标:
✅ 安装并使用 BeautifulSoup 解析 HTML✅ 用 CSS 选择器或标签名 提取网页内容✅ 实战:抓取新闻标题列表(以公开、友好的网站为例)✅ 学会检查 robots.txt 和设置合理请求头
📘 一、安装依赖
# 在你的虚拟环境中执行$ pip install requests beautifulsoup4 lxml
requests:发送 HTTP 请求beautifulsoup4:HTML/XML 解析库lxml:高性能解析器(推荐)
📘 二、基础用法:解析 HTML
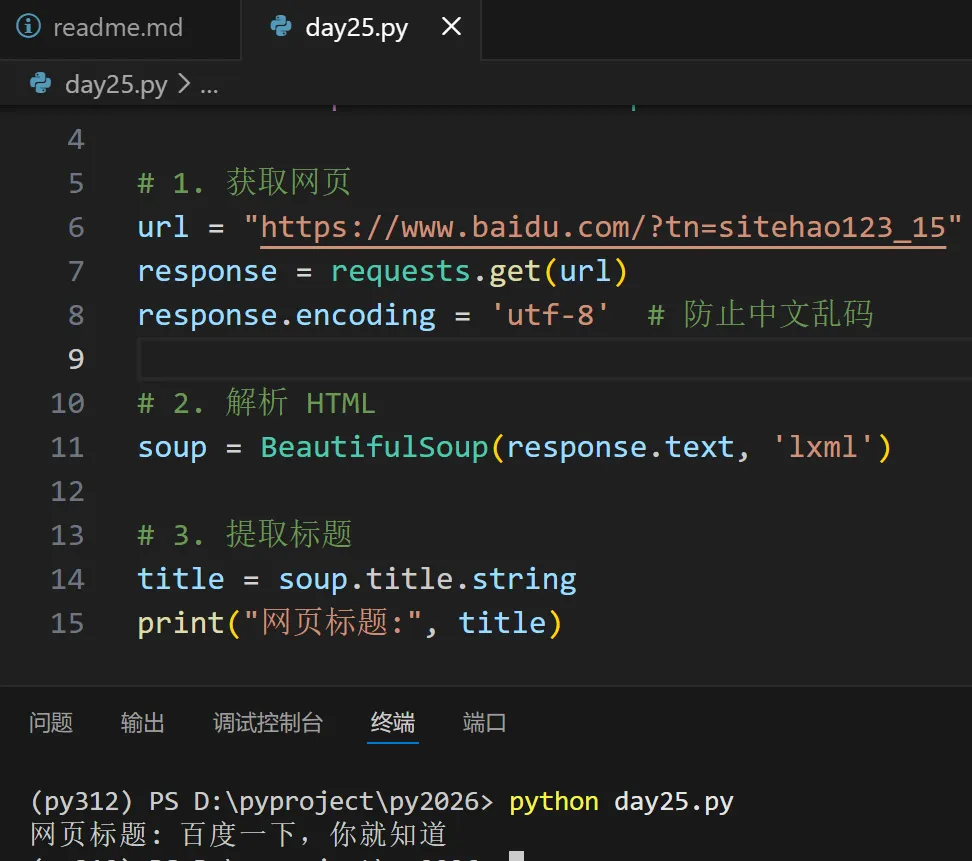
🔹 示例:提取网页标题
✅ soup.title.string 等价于 soup.find('title').get_text()
📘 三、核心提取方法
| | |
|---|
.find(tag) | | soup.find('h1') |
.find_all(tag) | | soup.find_all('a') |
.select(css_selector) | | soup.select('div.news > h2') |
🔹 常见 CSS 选择器
soup.select('h2') # 所有 h2 标签soup.select('.title') # class="title" 的元素soup.select('#main') # id="main" 的元素soup.select('div p') # div 内的所有 psoup.select('a[href]') # 有 href 属性的 a 标签
🌐 四、实战:抓取“人民日报”要闻标题(公开示例)
💡 我们选择 国家数据网 或 公开新闻聚合页 作为示例。注意:以下示例使用 httpbin.org/html(测试页面)和 新华社公开 RSS 页面(静态、友好)。
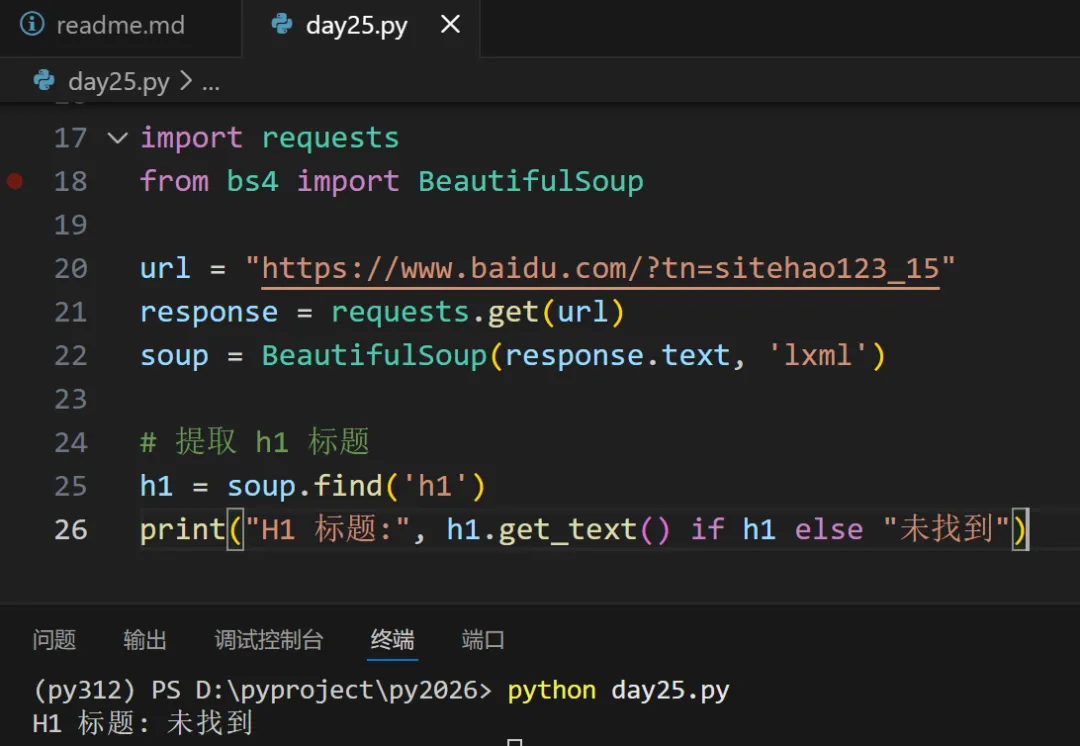
✅ 示例 1:解析测试页面
✅ 示例 2:抓取新华社“最新报道”标题(静态页面)
🔗 目标页面:http://www.xinhuanet.com/(首页)⚠️ 先检查 robots.txt:http://www.xinhuanet.com/robots.txt → 允许 / 路径
import requestsfrom bs4 import BeautifulSoupimport timedef scrape_xinhua_headlines(): url = "http://www.xinhuanet.com/" # 设置请求头,模拟浏览器(礼貌!) headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36" } try: print(f"正在请求: {url}") response = requests.get(url, headers=headers, timeout=10) response.raise_for_status() response.encoding = 'utf-8' soup = BeautifulSoup(response.text, 'lxml') # 尝试多种可能的选择器(实际需查看网页源码调整) headlines = [] # 方法1:查找 class 包含 'title' 的 a 标签 for link in soup.select('a[href*="/c"]'): # 新华社新闻链接通常含 /c/ title = link.get_text(strip=True) if title and len(title) > 5: # 过滤短文本 headlines.append(title) if len(headlines) >= 10: # 只取前10条 break if not headlines: # 方法2:查找 h3 标签(备用) for h3 in soup.find_all('h3'): title = h3.get_text(strip=True) if title: headlines.append(title) if len(headlines) >= 10: break print(f"\n📰 新华社最新报道(共 {len(headlines)} 条):") for i, title in enumerate(headlines, 1): print(f"{i}. {title}") except Exception as e: print(f"❌ 抓取失败: {e}")if __name__ == "__main__": scrape_xinhua_headlines() time.sleep(1) # 礼貌等待
🔍 提示:
- 实际开发中需用浏览器开发者工具(F12)查看目标元素的 class/id
🛡️ 五、遵守网络礼仪(必须!)
1. 检查 robots.txt
# 查看允许爬取的路径$ curl https://example.com/robots.txt
示例内容:
User-agent: *Disallow: /admin/Allow: /
→ 表示除 /admin/ 外均可访问
2. 设置合理请求头
headers = { "User-Agent": "MyBot/1.0 (+https://yourwebsite.com/bot)", # 声明身份 "Accept": "text/html"}
3. 控制请求频率
import timetime.sleep(1) # 每次请求间隔至少 1 秒
4. 处理异常
try: response = requests.get(url, timeout=10) response.raise_for_status()except requests.RequestException as e: print(f"请求失败: {e}")
💻 综合实战:保存新闻到 JSON 文件
import requestsfrom bs4 import BeautifulSoupimport jsonimport timedef save_news_to_json(news_list, filename="news.json"): with open(filename, "w", encoding="utf-8") as f: json.dump(news_list, f, ensure_ascii=False, indent=2) print(f"✅ 新闻已保存到 {filename}")# 假设我们有一个新闻列表(来自爬虫)fake_news = [ {"title": "人工智能助力医疗诊断", "source": "新华社"}, {"title": "全国多地迎来春季旅游高峰", "source": "人民日报"}]save_news_to_json(fake_news)
✅ 今日小任务
- 用 BeautifulSoup 提取
https://httpbin.org/html 页面中的 <h1> 文本 - 查看
https://quotes.toscrape.com/robots.txt,确认是否允许爬取,然后提取首页所有名言(.text 类)
💡 答案参考(任务2):
import requestsfrom bs4 import BeautifulSoup# 检查 robots.txt: 允许所有用户代理url = "https://quotes.toscrape.com/"res = requests.get(url)soup = BeautifulSoup(res.text, 'lxml')quotes = soup.select('.quote .text')for quote in quotes[:3]: # 只打印前3条 print(quote.get_text())
✅ 黄金法则:“能用 API 就不用爬虫,能手动就别自动化”爬虫是最后手段,务必合法、合理、有节制!
🎉 恭喜完成第25天!你已掌握 Web 数据提取的基础技能,能安全地从公开网页获取信息!
继续加油,你的数据获取能力又上新台阶!🕷️🌐