2.2 数据干净度处理
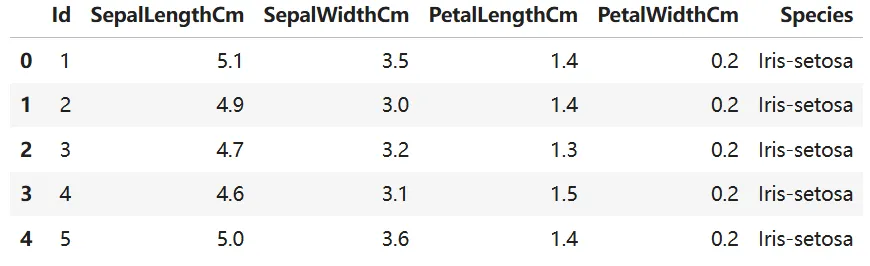
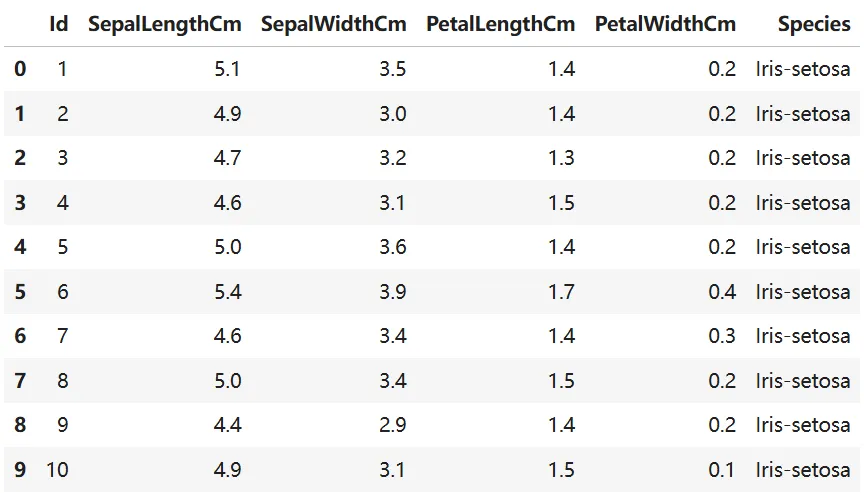
基本信息查看
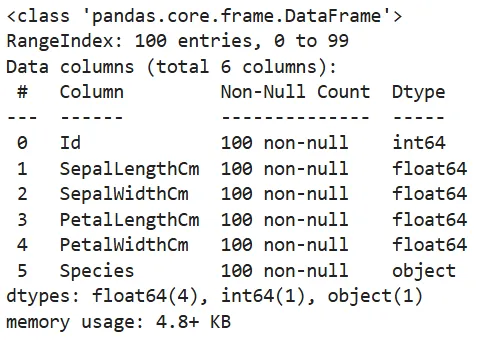
使用 info() 查看数据类型和缺失值情况。
cleaned_data.info()
结果显示共有100条记录,无缺失值。但Id列应为字符串类型,需要转换。
cleaned_data["Id"] = cleaned_data["Id"].astype("str")cleaned_data["Id"]
缺失数据处理
info()已显示无缺失值,无需处理。
重复数据处理
检查Id是否有重复值:
cleaned_data["Id"].duplicated().sum()
输出0,无重复数据。
不一致数据处理
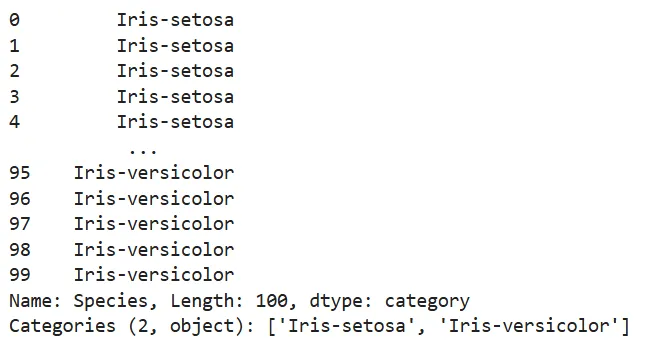
查看Species列的唯一值:
cleaned_data["Species"].value_counts()
结果只有两种类别:Iris-setosa和Iris-versicolor,无不一致数据。我们将该列转换为category类型以节省内存。
cleaned_data["Species"] = cleaned_data["Species"].astype("category")cleaned_data["Species"]
无效或错误数据处理
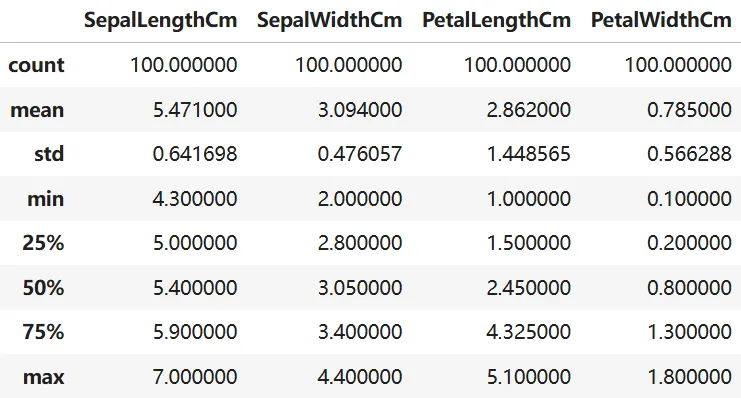
使用 describe() 查看数值列的统计信息,确认无异常值。
cleaned_data.describe()
所有数值均在合理范围内,无需处理。
📊 3. 整理数据
根据分析目标,我们需要将两种鸢尾花的数据分开。
iris_setosa = cleaned_data.query('Species == "Iris-setosa"')iris_setosa.head()len(iris_setosa) # 50iris_versicolor = cleaned_data.query('Species == "Iris-versicolor"')iris_versicolor.head()len(iris_versicolor) # 50
🔍 4. 探索数据
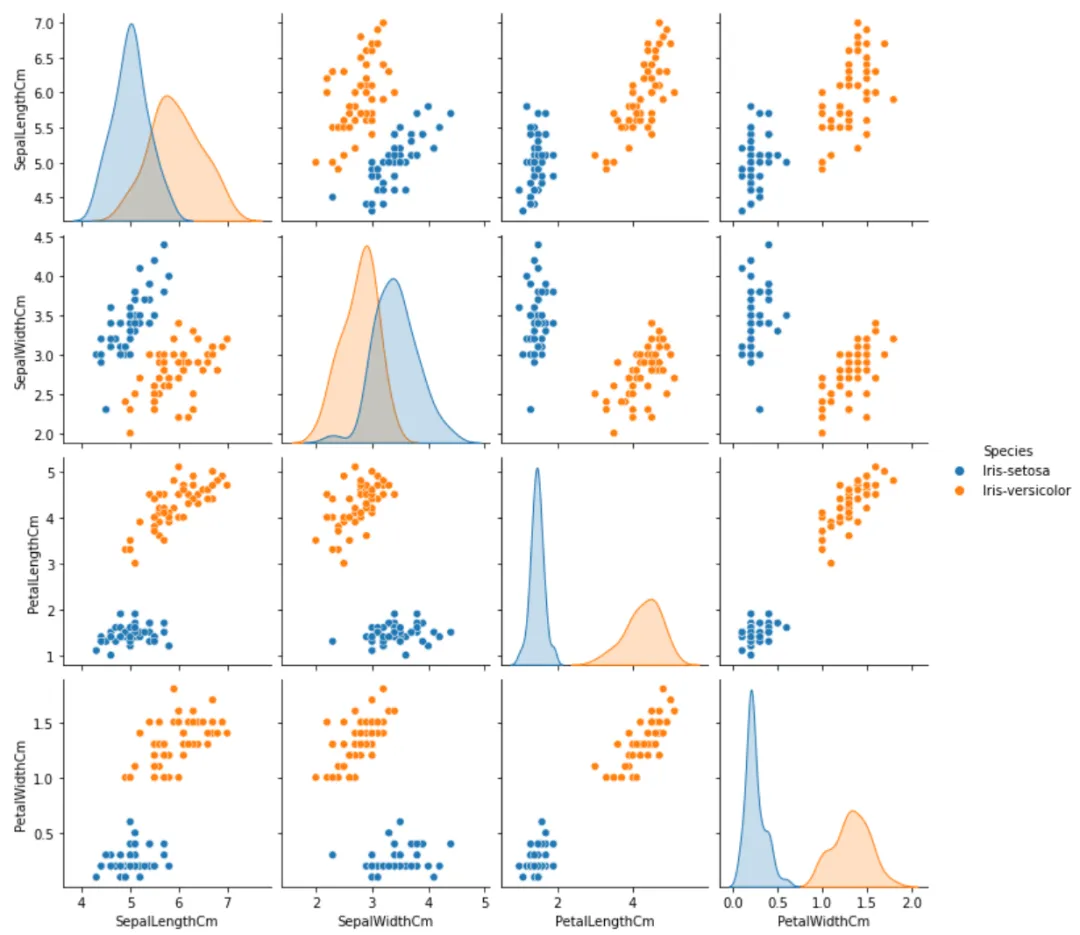
使用pairplot可视化两种鸢尾花各特征的分布关系,颜色区分种类。
sns.pairplot(cleaned_data, hue="Species")plt.show()
从图中可以看出,花瓣长度和宽度在两类之间差异明显,而萼片长度和宽度有一定重叠,需进一步统计检验。
📈 5. 分析数据
我们将对萼片长度、萼片宽度、花瓣长度、花瓣宽度分别进行独立样本t检验,判断均值是否存在显著差异。
引入t检验模块:
from scipy.stats import ttest_ind
5.1 萼片长度分析
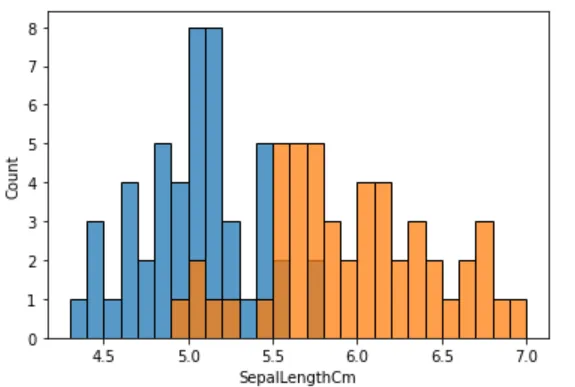
分布可视化
sns.histplot(iris_setosa['SepalLengthCm'], binwidth=0.1)sns.histplot(iris_versicolor['SepalLengthCm'], binwidth=0.1)plt.show()
假设检验
- 备择假设H₁:两种鸢尾花萼片长度平均值存在显著差异。
- 检验类型:双尾检验(我们只关心是否有差异,不关心谁大谁小)。
t_stat, p_value = ttest_ind(iris_setosa["SepalLengthCm"], iris_versicolor["SepalLengthCm"])print(f"t值:{t_stat}")print(f"p值:{p_value}")
输出:
t值:-10.52098626754911p值:8.985235037487079e-18
结论:p值远小于0.05,拒绝原假设,两种鸢尾花萼片长度均值存在显著差异。
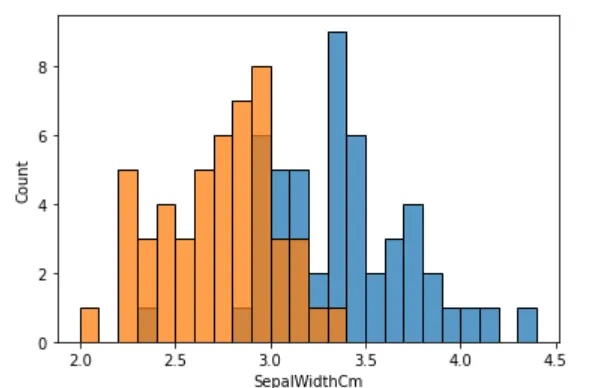
5.2 萼片宽度分析
分布可视化
sns.histplot(iris_setosa['SepalWidthCm'], binwidth=0.1)sns.histplot(iris_versicolor['SepalWidthCm'], binwidth=0.1)plt.show()
假设检验
t_stat, p_value = ttest_ind(iris_setosa["SepalWidthCm"], iris_versicolor["SepalWidthCm"])print(f"t值:{t_stat}")print(f"p值:{p_value}")
输出:
t值:9.282772555558111p值:4.362239016010214e-15
结论:p值 < 0.05,拒绝原假设,萼片宽度均值存在显著差异。
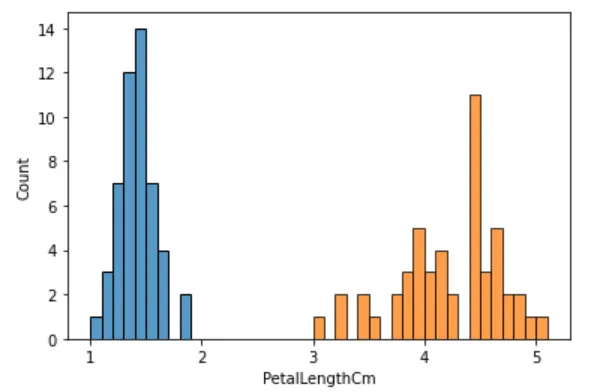
5.3 花瓣长度分析
分布可视化
sns.histplot(iris_setosa['PetalLengthCm'], binwidth=0.1)sns.histplot(iris_versicolor['PetalLengthCm'], binwidth=0.1)plt.show()
假设检验
t_stat, p_value = ttest_ind(iris_setosa["PetalLengthCm"], iris_versicolor["PetalLengthCm"])print(f"t值:{t_stat}")print(f"p值:{p_value}")
输出:
t值:-39.46866259397272p值:5.717463758170621e-62
结论:p值 < 0.05,花瓣长度均值存在显著差异。
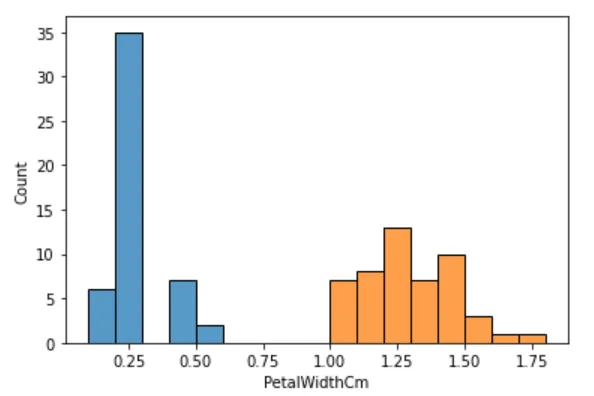
5.4 花瓣宽度分析
分布可视化
sns.histplot(iris_setosa['PetalWidthCm'], binwidth=0.1)sns.histplot(iris_versicolor['PetalWidthCm'], binwidth=0.1)plt.show()
假设检验
t_stat, p_value = ttest_ind(iris_setosa["PetalWidthCm"], iris_versicolor["PetalWidthCm"])print(f"t值:{t_stat}")print(f"p值:{p_value}")
输出:
t值:-34.01237858829048p值:4.589080615710866e-56
结论:p值 < 0.05,花瓣宽度均值存在显著差异。
📝 6. 结论
通过上述分析,我们得出以下结论:
- Setosa鸢尾花和Versicolor鸢尾花在萼片长度、萼片宽度、花瓣长度、花瓣宽度的平均值上均存在统计显著性差异(所有p值均远小于0.05)。
本次项目完整地演示了数据清洗、探索性分析和假设检验的流程,希望对大家的数据分析学习有所帮助!如果你有任何问题或想法,欢迎在评论区留言交流~ 💬
❝💡 完整代码及数据可在公众号后台回复「鸢尾花」获取。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
