Linux PCIe P2PDMA 技术介绍 技术介绍
- 2026-07-01 00:05:49
Linux PCIe P2PDMA 技术介绍
从 PCIe 硬件机制到内核实现,再到 Nvidia GDS 场景实践。
1. 引言:AI 基础设施的“传输墙”挑战
在当今大模型时代,数据传输效率已成为制约系统性能的关键瓶颈。随着 GPT-4、Llama 3 等千亿参数级模型的普及,训练数据集规模动辄达到 TB 甚至 PB 级别,Checkpoint 文件大小从数十 GB 增长到数百 GB。与此同时,NVMe SSD 的性能突飞猛进,PCIe 5.0 规范的 SSD 理论带宽已达到 14 GB/s,远超传统 CPU 内存路径的处理能力。这种“存储快、路径慢”的矛盾,使得数据传输路径成为 AI 基础设施的新瓶颈。
面对这一挑战,业界正在推动“设备直连化”的架构变革,让数据绕过 CPU 和系统内存,在设备之间直接传输。P2PDMA 正是这一变革的核心技术,它不仅消除了传统路径的带宽浪费,还释放了宝贵的 CPU 资源。
2. 核心痛点:传统数据路径的性能瓶颈
在深入理解 P2PDMA 之前,我们需要剖析传统数据路径为何无法满足现代 AI 负载的需求。
2.1 双 DMA 拷贝导致的带宽减半
在传统的存储 I/O 路径中,数据从 NVMe SSD 传输到 GPU Memory 需要经过两个独立的 DMA 操作:
// 传统数据路径示意图// 数据流向:NVMe SSD -> Host DRAM -> GPU Memory// 问题:两次 PCIe 传输,CPU 参与管理NVMe SSD ──DMA 1──► Host DRAM ──DMA 2──► GPU Memory │ ▼ CPU 参与 内存带宽消耗首先,NVMe 控制器发起 DMA 操作,将数据从 SSD 读取到系统内存(Host DRAM)。这一步占用了 PCIe 总线带宽,并消耗了 Root Complex 的处理能力。随后,GPU 驱动通过 cudaMemcpy 等机制,再次发起 DMA 操作,将数据从系统内存搬运到 GPU 显存。
这种双拷贝机制带来了显著的性能损耗。数据在 PCIe 总线上传输了两次,导致有效带宽直接减半。例如,在 PCIe 4.0 x16 链路下,理论带宽为 32 GB/s,但由于数据需要一来一回,实际端到端吞吐量很难超过 16 GB/s。此外,这一过程还占用了大量的系统内存带宽,可能影响 CPU 上运行的其他关键任务。
2.2 NUMA 架构下的跨 Socket 延迟影响
现代服务器通常采用多 Socket 架构来扩展计算能力,每个 Socket 拥有独立的内存控制器和 PCIe Root Complex,形成了 NUMA(Non-Uniform Memory Access)拓扑。
在典型的 AI 服务器配置中,GPU 可能连接到 Socket 0,而 NVMe SSD 连接到 Socket 1。当数据需要从 SSD 传输到 GPU 时,必须跨越 QPI(QuickPath Interconnect)或 UPI(Ultra Path Interconnect)总线。这种跨 Socket 传输不仅受到互联总线带宽的限制,还会引入额外的延迟。通常情况下,跨 Socket 的内存访问延迟比本地访问高出 2-3 倍,这对于延迟敏感的推理任务(如首 Token 生成)是不可忽视的开销。
重要提示:在许多服务器平台上,跨 Socket 的 P2P 传输不仅性能下降,甚至可能被硬件彻底禁用(Peer-to-Peer not supported across Root Complexes)。这是因为不同 Socket 的 Root Complex 之间缺乏必要的 P2P 转发机制。因此,在规划 P2PDMA 部署时,务必确认所有参与设备位于同一 Socket 的 PCIe 域内。
2.3 CPU 缓存污染与延迟叠加
除了带宽和拓扑问题,传统路径还存在隐性的性能杀手——CPU 缓存污染。当大量数据流经 CPU 内存时,可能会将 CPU L3 Cache 中的关键指令和数据挤出,导致计算任务的 Cache Miss 率上升,进而影响整体系统性能。
此外,传统路径涉及多次中断处理、上下文切换和内存拷贝,这些操作的延迟会逐层叠加。对于小块数据的随机访问,这种固有的软件栈开销甚至可能超过数据传输本身的时间,成为限制 IOPS 的主要因素。
3. 技术原理:P2PDMA 如何突破瓶颈
P2PDMA(Peer-to-Peer DMA)是一种允许 PCIe 设备之间直接进行数据传输的技术,它通过绕过主机 CPU 和系统内存,从根本上解决了传统路径的痛点。
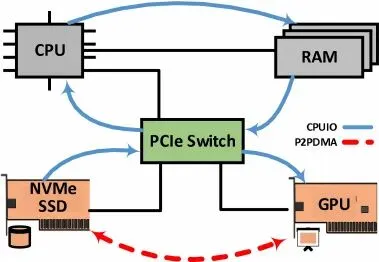
3.1 P2PDMA 工作机制
P2PDMA 的核心思想是“点对点直连”。在 P2P 模式下,源设备(如 NVMe SSD)直接将数据写入目标设备(如 GPU)的地址空间。
// P2PDMA 数据路径示意图// 数据流向:NVMe SSD ══════════════════════► GPU Memory// 特点:单次 PCIe 传输,绕过 CPU 和系统内存NVMe SSD ═══P2P DMA═══► GPU Memory │ ▲ │ │ └─── PCIe Switch ───────┘ (本地转发)图例说明:
• ══►双线箭头:表示 P2P 直连路径,数据不经 CPU/系统内存• ──►单线箭头:表示传统路径,数据经 CPU/系统内存中转
与传统路径对比:
// 传统路径 vs P2P 路径对比【传统路径】NVMe SSD ──DMA 1──► Host DRAM ──DMA 2──► GPU Memory │ ▼ CPU 参与,带宽减半【P2P 路径】NVMe SSD ═══P2P DMA═══► GPU Memory │ ▲ └─── PCIe Switch ───────┘ 零拷贝,带宽翻倍这一机制带来了质的飞跃:
• 零拷贝:数据不再经过系统内存,消除了双次拷贝的开销,PCIe 链路利用率更高。 • CPU 解放:CPU 主要在初始化阶段参与资源配置,数据搬运由设备 DMA 引擎完成,从而降低 CPU 负载。 • 延迟优化:减少路径跳数与软件参与,端到端延迟通常更低。
3.2 PCIe 视角的实现机制:TLP 路由与地址解码
从 PCIe 协议层面看,P2PDMA 依赖于统一的地址空间模型(Address Routing)。
地址路由(Address Routing):
每个 PCIe 设备都通过 BAR(Base Address Register)暴露一段地址空间。当 NVMe 控制器执行 P2P 写操作时,它会构造 Memory Write TLP(Transaction Layer Packet),其目标地址落在 GPU 的 BAR 窗口范围内(典型情况下是可用于映射显存的 BAR 区域)。PCIe Switch 与 Root Port / Host Bridge 会依据地址解码规则转发该 TLP。[1] 关于 TLP 结构与 PCIe 分层协议的更详细介绍,可参考 PCIe 总线技术大全。
TLP 转发路径与 Linux 的 P2P 策略:
在 PCIe 中,TLP 在到达 Root Port 之前的路由规则相对明确;若拓扑中包含 Switch,则基于 ACS(Access Control Services)配置,事务可能完全在 PCIe 层级内部完成而不触达 Root Port。[1]
一旦事务抵达 Host Bridge,硬件可能需要在同一 Root Port “折返”(hairpin)、在 SoC 内部转发到另一 Root Port,或在 SoC 内部被特殊处理。由于 PCIe 规范并不要求跨 PCIe hierarchy domain 的转发,Linux 内核默认会阻止这类不确定路径,仅在“同一 Root Port 之下”或 Host Bridge 处于已知安全的 allow list(pci_p2pdma_whitelist)时放行 P2P。[1]
从工程经验上,P2P 最稳定且性能最好的形态通常是:发起端与目标端位于同一 Switch 或同一 Root Port 的下游;跨 Root Port 的 P2P 往往不可用或会退化为性能较差的路径,这与内核默认策略相一致。[1]
MPS(Maximum Payload Size)与 MRRS(Maximum Read Request Size):
MPS 决定单个 TLP 的最大有效载荷大小,影响大块 DMA 写(Memory Write)时的分片粒度;MRRS 决定单次 Memory Read Request 的最大请求长度,影响 DMA 读(Memory Read)时请求数量与 Completion(CplD)分片方式。Linux 提供 pci=pcie_bus_perf、pci=pcie_bus_safe、pci=pcie_bus_peer2peer 等参数用于统一/调优 MPS,并在 pcie_bus_perf 模式下同时尝试设置更合适的 MRRS(文档中描述为“为获得更好性能,MRRS 取不超过设备或总线可支持 MPS 的最大值”)。[3]
这些参数属于系统级调优开关,可能影响整个 PCIe 拓扑中所有设备。对生产环境而言,建议以“先验证 P2P 可达与稳定,再逐步调优 MPS/MRRS 并用基准测试验证收益”为原则。
4. 业务价值:AI 场景下的性能飞跃
P2PDMA 并非仅是底层的硬件特性,它在实际的 AI 业务场景中能够转化为显著的性能收益。
4.1 加速大模型 Checkpoint 加载
在分布式训练中,Checkpoint 的保存与加载是保障训练可靠性的关键。以 175B 参数的模型为例,单个 Checkpoint 文件可能高达 350GB。使用传统路径加载,受限于双拷贝和系统内存带宽,有效吞吐量往往只有 3-4 GB/s,耗时超过 100 秒。
引入 P2PDMA 后,数据可以绕开限速的 CPU 内存中转,直接以接近 NVMe SSD 的限速(如 10 GB/s 以上)写入 GPU 显存。这可以将 Checkpoint 加载时间缩短一半以上,显著减少了故障恢复或模型切换时的等待时间,提升了昂贵的 GPU 集群的利用率。
4.2 优化推理服务 KV Cache 预热
对于支持长上下文的 LLM 推理服务,KV Cache 的预加载速度直接影响首 Token 延迟(TTFT)。以 Llama 3.1-70B 模型为例,处理 128K 上下文可能需要加载数十 GB 的 KV Cache。
通过 P2PDMA,推理服务可以快速从本地 NVMe SSD 将历史 KV Cache 恢复到 GPU 显存。这不仅大幅降低了 TTFT,还使得系统能够支持更频繁的上下文切换,提升了多用户并发场景下的服务质量。
4.3 提升分布式训练通信效率
虽然 P2PDMA 主要用于存储与 GPU 之间,但其背后的 GPUDirect 技术同样适用于网卡与 GPU 之间(GPUDirect RDMA)。在多机多卡训练中,梯度聚合需要跨网络传输大量数据。结合 P2PDMA 和 RDMA,数据可以从 GPU 直接流向网卡,再通过网络到达对端 GPU,实现了全链路的零拷贝通信,极大地提升了分布式训练的扩展效率。有关 GPUDirect RDMA 的更多技术细节,请参阅 GPUDirect RDMA 与 Storage 技术详解。
5. 硬件实现要求与限制
虽然 P2PDMA 优势明显,但其部署对硬件环境有严格要求。
5.1 PCIe 拓扑与 Switch 能力
PCIe Switch 的关键作用:在实现 P2PDMA 的架构中,PCIe Switch(如 PLX/Broadcom 芯片)扮演着至关重要的角色。它不仅能够扩展 PCIe 端口数量,更重要的是提供了本地转发能力——当源设备和目标设备连接在同一 Switch 下时,数据包可以直接在 Switch 内部完成路由,无需上行至 Root Complex。这种设计既缓解了 Root Complex 的带宽压力,又显著降低了 P2P 传输的延迟。因此,在高端 AI 服务器设计中,合理规划 PCIe Switch 拓扑是获得最佳 P2P 性能的前提。
最理想的 P2PDMA 拓扑是将 NVMe SSD 和 GPU 连接在同一个支持 P2P Forwarding 的 PCIe Switch 下。这种配置下,数据直接在 Switch 内部交换,延迟最低。对于 GPU 间的高速互连,除了 PCIe,NVIDIA 还推出了带宽更高、延迟更低的专用互连技术 NVLink,它彻底打破了 PCIe 的带宽瓶颈。
如果设备连接在 Root Complex 上,或者跨越了不同的 Switch,P2P 传输就需要 Root Complex 的参与。虽然 PCIe 规范支持这种路由,但在跨 Socket 的 NUMA 架构下,性能往往会大打折扣。因此,在构建 AI 服务器时,物理拓扑的设计至关重要,通常建议将需要频繁通信的设备放置在同一 PCIe 根端口或 Switch 下。
5.2 关键限制:ACS (Access Control Services)
ACS 是 PCIe 的安全特性,用于控制设备间的访问,防止恶意设备进行未经授权的 DMA。ACS Capability 包含多个控制位,其中对 P2P 影响最大的是:
• P2P Request Redirect (RR): 如果置 1,Switch 必须将所有 P2P 请求上行转发给 Root Complex,而不是直接转发给目标设备。 • Source Validation (V): 验证请求的 Requester ID 是否合法。
如果启用了 ACS 的 P2P Redirect(例如 ReqRedir / CmpltRedir),原本可以直接在 Switch 内部完成的 P2P 流量会被强制上行到 Root Port,这会显著增加延迟并降低带宽;在某些平台上还可能导致 P2P 不可用。[1]
从排障角度,NVIDIA NCCL 文档建议通过 lspci -vvv | grep ACSCtl 检查 PCI bridge 上是否启用了 ACS,并在可行的裸机环境中禁用 ACS 以获得更好的 GPU Direct 通信性能。[4]
5.3 IOMMU 配置与设备隔离
IOMMU(I/O Memory Management Unit)是影响 P2P 的另一个关键因素。它负责将设备发起 DMA 时使用的 IOVA(I/O Virtual Address)翻译为系统可路由的 DMA 地址,并提供隔离与保护。IOMMU 的存在并不改变 PCIe Switch 的转发逻辑,但它会影响“设备能否对某个地址发起合法 DMA 访问”以及 DMA 映射能否建立。对于 GPU Direct / P2P 类场景,错误的 IOMMU/VT-d 配置可能导致点对点流量被重定向或显著降速,甚至引发异常。[4]
5.3.1 IOMMU Group 与设备隔离
在 Linux 中,IOMMU Group 是一组无法被安全隔离的设备集合。如果两个设备处于同一个 IOMMU Group 且开启了 IOMMU,内核可能因为安全隔离策略阻止 P2P 事务,即使没有 ACS 干扰。
可以通过以下命令查看设备的 IOMMU Group 归属:
# 查看 GPU 的 IOMMU Group$ ls -la /sys/bus/pci/devices/0000:01:00.0/iommu_group/# 或使用以下脚本列出所有 IOMMU Group$ for g in /sys/kernel/iommu_groups/*; do echo "IOMMU Group ${g##*/}:"; for d in $g/devices/*; do echo -e "\t$(lspci -nns ${d##*/})"; done; done最佳实践:确保参与 P2P 的设备位于不同的 IOMMU Group,或在确认安全的前提下将相关设备配置为直通模式(Passthrough)。
5.3.2 IOMMU Passthrough 模式
Linux 的 P2PDMA 机制会在内核态评估拓扑,并以“可证明安全”的方式允许 P2P;在涉及 ZONE_DEVICE/MEMORY_DEVICE_PCI_P2PDMA 的情况下,还要求相关子系统保证不会发生非法 CPU 访问(例如禁止对该类页面做普通 memcpy 访问)。[1]
由于 P2P 地址翻译的复杂性,最稳健的做法是将 IOMMU 配置为 Passthrough 模式(iommu=pt)。在这种模式下,设备直接使用物理地址进行通信,绕过了 IOMMU 的翻译开销和潜在的兼容性问题。
5.4 GPU 显存映射:BAR1 与 ReBAR
NVIDIA GPU 使用 BAR1 来暴露显存供 CPU 或其他设备访问。早期的 GPU BAR1 窗口较小(如 256MB),限制了 P2P 传输的效率。现代数据中心 GPU(如 A100/H100)支持 Resizable BAR(ReBAR)技术,可以将整个显存映射到 BAR1。这消除了动态映射窗口的开销,是实现高性能 P2PDMA 的关键硬件前提。
重要说明:若不开启 Resizable BAR,BAR1 窗口通常固定在 256MB(部分平台可能更小)。这意味着:
• P2PDMA 传输大块数据时,需要频繁触发重映射窗口操作 • 每次窗口重映射都会引入额外的软件开销和延迟 • 整体传输性能将大幅下降,无法发挥 NVMe SSD 的高速带宽优势
因此,强烈建议在 BIOS 中开启 Resizable BAR,并将其视为 P2PDMA/GDS 部署的必选项。可通过以下命令验证 ReBAR 是否已启用:
# 检查 GPU 的 BAR 大小$ lspci -s <gpu_bdf> -vvv | grep -A 5 "Region 2:"# 输出示例(ReBAR 已启用,BAR1 映射整个显存):# Region 2: Memory at fa000000 (64-bit, prefetchable) [size=128G]6. Linux 软件栈深度解析
Linux 内核提供了 pci_p2pdma 子系统,用于在可证明安全的前提下支持 PCIe 设备间的 P2P DMA,并对拓扑可达性、生命周期与页面语义做出约束。[1]
6.1 pci_p2pdma 子系统架构
在 P2P 传输中,涉及三种角色:
1. Provider (提供者):提供内存资源的设备(如 GPU 显存,或 NVMe CMB)。 2. Client (使用者):发起 DMA 操作的设备(如 NVMe SSD)。 3. Orchestrator (编排者):负责协调 P2P 传输的驱动(如 NVMe Target 驱动)。
这一“Provider / Client / Orchestrator”划分来自 Linux 内核对 P2P DMA 的建模,并用于约束生命周期、映射与拓扑可达性判定。[1]
pci_p2pdma 子系统提供了关键 API:
• pci_p2pdma_add_resource(): 注册 P2P 内存资源。• pci_p2pdma_distance_many(): 计算设备间的 PCIe 拓扑距离,判断是否支持 P2P。
距离判断机制:内核通过 pci_p2pdma_distance_many() 返回的距离值来判定 P2P 可行性。距离值的语义如下:
• 负值:P2P 不支持,设备间无法建立直接的 P2P DMA 路径。 • 正值:P2P 可行,值越小表示拓扑距离越近(如同一 Switch 下距离为 0)。
在内核实现中,enum pci_p2pdma_map_type 定义了更细粒度的映射类型:
enum pci_p2pdma_map_type { PCI_P2PDMA_MAP_UNKNOWN = 0, // 未知,需要进一步检测 PCI_P2PDMA_MAP_NOT_SUPPORTED, // 不支持 P2P PCI_P2PDMA_MAP_BUS_ADDR, // 可直接使用总线地址 PCI_P2PDMA_MAP_THRU_HOST_BRIDGE, // 需经 Host Bridge 转发};其中 PCI_P2PDMA_MAP_THRU_HOST_BRIDGE 表示 P2P 事务需要经过 Host Bridge,这通常意味着性能会有所下降,但在某些平台上仍是可用的。
6.2 ZONE_DEVICE 与 struct page
Linux 内核通常要求所有内存都有对应的 struct page 结构,以便进行统一管理(如引用计数、页表映射)。然而,设备内存(Device Memory)并不在系统 RAM 范围内。
Linux 通过 ZONE_DEVICE 的 pgmap 机制把一部分设备 MMIO 区域包装成 MEMORY_DEVICE_PCI_P2PDMA,为其创建 struct page,从而使其在某些路径上可被 DMA/I/O 子系统接受。[1]
技术细节:在内核实现中,P2PDMA 页面通过 pgmap->type 字段被标记为 MEMORY_DEVICE_PCI_P2PDMA。这是内核区分“常规内存页”与“设备映射页”的关键标志。相关代码路径会检查此类型,以决定是否允许特定的操作。例如,is_pci_p2pdma_page() 函数用于判断一个页面是否为 P2PDMA 页面:
// 简化的内核逻辑示意static inline bool is_pci_p2pdma_page(const struct page *page){ return page->pgmap && page->pgmap->type == MEMORY_DEVICE_PCI_P2PDMA;}这种设计使得 P2PDMA 页面能够在 DMA 映射等流程中被正确处理,同时禁止不当的 CPU 直接访问。
需要强调的是,这类页面的 CPU 直接访问是被禁止的(与普通 MMIO 一致),即便在部分架构上“看似可用”,也可能导致内核崩溃或数据损坏;同时,FOLL_LONGTERM 会被禁止,只有显式支持 FOLL_PCI_P2PDMA 的子系统才能安全地把这类页面纳入 pin_user_pages() 等流程。[1]
因此,谈“能否用于 O_DIRECT/VFS”时应以“相关内核子系统是否显式支持 MEMORY_DEVICE_PCI_P2PDMA”为前提,而不是默认全部可用。
7. 最佳实践:NVIDIA GPUDirect Storage (GDS)
GPUDirect Storage (GDS) 是 NVIDIA 基于 P2PDMA 技术构建的完整解决方案,它将底层复杂的硬件细节封装成了易用的 API。
7.1 GDS 架构解析:控制流与数据流分离
GDS 的设计核心是控制流与数据流分离。[2] 它与仅用于 GPU 间内存访问的 GPUDirect P2P 类似,但将范畴扩展到了存储领域。
1. 控制流 (Control Path):应用程序在 CPU 侧调用 cuFileRead(libcufile.so),通过 IOCTL 与内核侧组件交互,并沿 VFS 与存储驱动完成文件元数据与 I/O 请求编排(例如把文件偏移拆解为底层块设备请求与 scatter-gather 片段)。[2]2. 数据流 (Data Path):在满足对齐与直通传输条件(例如典型的 O_DIRECT使用场景)且平台/驱动支持时,GDS 让靠近存储侧的 DMA 引擎可以直接对 GPU 内存做 DMA(避免 CPU 系统内存 bounce buffer);若条件不满足或路径不可达,cuFile 会退化到兼容路径或使用中间 staging 以保证功能正确性。[2]
更准确地说,GDS 的目标是在满足文件系统/内核 I/O 栈控制面的前提下,让“靠近存储的一侧”(NVMe 或 NIC 附近的 DMA 引擎)能够直接把数据推送/拉取到 GPU 内存,避免在 CPU 系统内存中经过 bounce buffer,从而降低 CPU 负载、缓解带宽瓶颈并降低延迟。[2]
在实现层面,NVIDIA 文档描述了 nvidia-fs.ko 作为内核侧组件,通过回调把 GPU 虚拟地址转换为最终用于编程 DMA 引擎的 scatter-gather 列表项,并由底层存储驱动据此发起传输。[2]
分布式文件系统支持:nvidia-fs 不仅支持本地 NVMe 存储,还针对分布式文件系统(如 Lustre、WekaIO、IBM Spectrum Scale 等)提供了特殊支持。这些文件系统通常运行在集群环境中,数据分布在多个存储节点上。GDS 通过与这些文件系统的客户端驱动集成,能够实现从远程存储到 GPU 显存的直接数据传输,避免了中间拷贝。在使用分布式文件系统时,需要确保:
1. 文件系统客户端支持 GDS(查阅厂商兼容性列表) 2. 网络传输路径支持 GPUDirect RDMA(如使用支持该特性的网卡) 3. 正确配置 nvidia-fs与文件系统客户端的集成参数
版本兼容性说明:GDS 的功能和支持程度随 CUDA 版本演进:
nvidia-fs.ko 内核模块 | |
nvidia-fs 支持 | |
nvidia-fs.ko 的依赖 |
重要提示:
• 不同 CUDA 版本对操作系统内核版本有特定要求 • 生产环境部署前,务必查阅 NVIDIA 官方文档确认版本兼容性矩阵 • 升级 CUDA 版本时,需同步更新 NVIDIA 驱动和 GDS 组件
此外,NVIDIA 文档也指出:在部分 NVMe 场景(例如 CUDA 12.8 及更高版本的部分平台与发行版组合),GDS 开始利用上游 Linux 的 PCI P2PDMA 基础设施来实现 NVMe 相关的 P2P DMA 能力,从而降低对 nvidia-fs.ko 的依赖范围。[2]
7.2 性能收益验证
NVIDIA 文档将 GDS 的收益表述为:通过避免 CPU 侧 bounce buffer,可缓解系统带宽瓶颈并降低 CPU 的延迟与利用率负担;在某些系统拓扑中,直接路径可达到相比经 CPU 路径“至少两倍”的峰值带宽,同时小传输的延迟改善更明显。[2]
实际收益高度依赖于 I/O 大小分布、对齐、文件系统、存储与 GPU 的拓扑位置、以及是否需要中间 staging(例如经 NVLink 或 GPU 内部缓冲区)。建议使用 gdscheck 校验环境,再用 gdsio 或业务基准测试进行端到端验证。[2]
7.3 GDS 的 O_DIRECT 依赖要求
关键前提:GDS 要求应用程序必须使用 O_DIRECT 标志打开文件。这是实现零拷贝 P2P 传输的必要条件。
如果应用层没有开启直接 I/O,数据流向将变为:
// 未使用 O_DIRECT 的数据路径(P2P 失效)NVMe SSD ──DMA──► Page Cache ──CPU Copy──► GPU Memory │ ▼ CPU 参与,P2P 失效当未使用 O_DIRECT 时,数据会先进入操作系统的 Page Cache,然后再通过 CPU 拷贝到 GPU 显存。这不仅绕过了 P2P 路径,还引入了额外的 CPU 开销和内存带宽消耗。
最佳实践:
1. 确保应用程序使用 open()时指定O_DIRECT标志2. 数据缓冲区需要对齐到页边界(通常 4KB 或更大) 3. I/O 大小建议为页大小的整数倍 4. 使用 gdscheck工具验证 GDS 环境配置是否正确
8. 实战指南:环境检查与故障排查
在部署 P2PDMA 之前,建议按照以下步骤进行深度检查。
8.1 检查 PCIe 拓扑与 P2P 支持
使用 lspci -t 查看设备树,确认 GPU 和 NVMe 是否在同一 Switch 下。
$ lspci -tv-[0000:00]-+-00.0 # Root Complex +-01.0-[01]--+-00.0 # GPU | \-01.0 # NVMe (同一 Switch 下,最佳拓扑)推荐工具:nvidia-smi topo -m:
对于 AI 工程师而言,nvidia-smi topo -m 是查看 GPU 与其他设备拓扑关系及 P2P 亲和性的最常用工具:
nvidia-smi topo -m GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity GPU NUMA IDGPU0 X NODE NODE NODE SYS SYS SYS SYS 0-63,128-191 0 N/AGPU1 NODE X NODE NODE SYS SYS SYS SYS 0-63,128-191 0 N/AGPU2 NODE NODE X NODE SYS SYS SYS SYS 0-63,128-191 0 N/AGPU3 NODE NODE NODE X SYS SYS SYS SYS 0-63,128-191 0 N/AGPU4 SYS SYS SYS SYS X NODE NODE NODE 64-127,192-255 1 N/AGPU5 SYS SYS SYS SYS NODE X NODE NODE 64-127,192-255 1 N/AGPU6 SYS SYS SYS SYS NODE NODE X NODE 64-127,192-255 1 N/AGPU7 SYS SYS SYS SYS NODE NODE NODE X 64-127,192-255 1 N/ALegend: X = Self SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI) NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU) PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge) PIX = Connection traversing at most a single PCIe bridge NV# = Connection traversing a bonded set of # NVLinks拓扑标识解读:
通过此命令,可以快速判断 GPU 与 NVMe SSD、网卡等设备的 P2P 可行性与预期性能。
检查 NVMe CMB 支持:
部分 NVMe SSD 支持 CMB(Controller Memory Buffer),这是一种将 NVMe 控制器的内存映射到主机地址空间的机制,可用于优化 P2P 传输。检查 NVMe 是否支持 CMB:
# 检查 NVMe CMB 支持$ nvme id-ctrl /dev/nvme0 -H | grep -i cmb# 输出示例(支持 CMB):# cmic : 0# cmbloc : 0x8000001# cmbsz : 0x4000000如果输出显示 cmbloc 和 cmbsz 非零值,表示该 NVMe 设备支持 CMB。CMB 可以作为 P2P 传输的中间缓冲区,在某些场景下提升性能。
8.2 验证 ACS 配置(关键步骤)
检查 ACS 是否会阻止 P2P。使用 lspci -vvv 查看 Access Control Services 能力。
$ lspci -s <device_bdf> -vvv | grep -A 10 "Access Control Services"Capabilities: [xxx] Access Control Services ACSCap: SrcValid+ TransBlk+ ReqRedir+ CmpltRedir+ ... ACSCtl: SrcValid- TransBlk- ReqRedir- CmpltRedir- ...解读:
• ACSCap表示硬件支持的能力。• ACSCtl表示当前启用的控制位。• 关键点:关注 ACSCtl中的ReqRedir/CmpltRedir是否为+。若启用重定向,P2P 请求/完成可能被强制上行到 Root Port,导致性能显著降低或 P2P 不可用。[1]• 作为快速排障线索,NVIDIA NCCL 文档给出了“若 grep ACSCtl输出中出现SrcValid+,则 ACS 可能启用”的经验判断;更稳妥的做法仍是查看完整lspci -vvv输出并结合拓扑判断哪些 bridge 的 ACSCtl 位被打开。[4]
禁用 ACS 的方法:
在裸机环境中,可以通过内核启动参数禁用 ACS 重定向功能(需 Linux Kernel 5.1+)。具体步骤如下:
1. 定位需要禁用 ACS 的 Root Port BDF: # 查找所有启用了 ACS 的 PCI Bridge$ lspci -vvv | grep -B 20 "ACSCtl:.*ReqRedir+" | grep "^[0-9a-f]\+:"# 输出示例:# 00:01.0 PCI bridge: Intel Corporation ...# 00:02.0 PCI bridge: Intel Corporation ...2. 通过内核参数禁用 ACS: 在 GRUB 配置(
/etc/default/grub中的GRUB_CMDLINE_LINUX)中添加以下参数(以 BDF00:01.0和00:02.0为例):# /etc/default/grubGRUB_CMDLINE_LINUX="... pci=disable_acs_redir=00:01.0,00:02.0"3. 更新 GRUB 并重启: sudo update-grub # Debian/Ubuntusudo grub2-mkconfig -o /boot/grub2/grub.cfg # RHEL/CentOSsudo reboot4. 验证 ACS 已禁用: 重启后再次检查
ACSCtl输出,确认ReqRedir和CmpltRedir已变为-。
8.3 确认 IOMMU 模式
检查内核启动参数,确保 IOMMU 处于 Passthrough 模式。
$ cat /proc/cmdline... iommu=pt intel_iommu=on ...如果缺少 iommu=pt,P2P 传输可能会失败或性能极低。
SR-IOV 注意事项:当使用 iommu=pt(Passthrough 模式)时,需要注意对 SR-IOV(Single Root I/O Virtualization) 功能的影响:
• SR-IOV 允许单个 PCIe 设备(如网卡)呈现为多个虚拟功能(VF),供不同虚拟机或容器使用 • 在 Passthrough 模式下,IOMMU 的地址翻译功能被绕过,这可能影响 SR-IOV VF 的隔离能力 • 如果环境中同时使用了 SR-IOV 和 P2PDMA,建议: 1. 评估是否可以接受 SR-IOV 隔离能力的降低 2. 或者考虑将 SR-IOV 设备和 P2PDMA 设备部署在不同的 IOMMU 域中 3. 查阅服务器厂商文档,了解特定平台对 SR-IOV 与 IOMMU Passthrough 共存的支持情况
8.4 性能基准测试
使用 gdsio 工具进行压力测试,验证是否达到预期带宽。
# 顺序读测试,块大小 1M,线程数 4$ gdsio -f /mnt/nvme/testfile -d 0 -w 0 -s 10G -i 1M -x 0 -I 1 -t 4在测试运行时,观察 iostat 确认磁盘带宽,观察 mpstat 确认 CPU 利用率(应极低),观察 nvidia-smi 确认 GPU 显存活动。
8.5 常见问题排查
在部署 P2PDMA/GDS 过程中,可能会遇到以下常见问题:
8.5.1 gdscheck 检查失败
问题现象:运行 gdscheck 报告环境配置错误。
常见原因及解决方案:
GPU not supported | ||
NVMe not detected | lsblk 和 lspci 输出 | |
ReBAR not enabled | ||
nvidia-fs not loaded | modprobe nvidia-fs | |
IOMMU not in pass-through | iommu=pt 内核参数 |
8.5.2 P2P 带宽远低于预期
问题现象:gdsio 测试带宽显著低于 NVMe SSD 理论值。
排查步骤:
1. 确认拓扑:使用 nvidia-smi topo -m确认 GPU 和 NVMe 位于同一 Switch 下(PIX 标识)2. 检查 ACS:确认 ACS 重定向已禁用 3. 验证 ReBAR:确认 BAR1 大小映射了整个显存 4. 检查对齐:确认 I/O 大小为页大小的整数倍,缓冲区页对齐 5. 排除退化:检查是否因条件不满足退化到兼容路径
8.5.3 P2P 传输完全失败
问题现象:P2P 相关操作直接报错。
排查步骤:
1. 检查内核日志: dmesg | grep -i p2p2. 检查 IOMMU Group 是否冲突 3. 确认跨 Socket 场景:设备是否位于同一 Socket 的 PCIe 域内 4. 验证驱动版本:确保 NVIDIA 驱动和 CUDA 版本兼容
8.5.4 容器化部署注意事项
问题现象:在容器中运行 GDS 应用失败。
解决方案:
1. 确保容器具有 --privileged或正确的--cap-add权限2. 挂载必要的设备文件: --device /dev/nvidia0 --device /dev/nvidiactl3. 确保 NVIDIA Container Toolkit 正确配置 4. 检查 nvidia-fs设备是否正确挂载到容器中
9. 未来展望:从 PCIe 到 CXL
随着 AI 算力需求的持续爆炸,互联技术也在不断演进。CXL(Compute Express Link) 作为下一代互联标准,将进一步打破内存墙。CXL.mem 协议允许 CPU 和加速器共享统一的内存池,彻底解决了传统 PCIe P2P 中的地址一致性问题。未来,NVMe SSD、GPU 和 CPU 将在 CXL 互联架构下实现更紧密的融合,P2PDMA 将变得更加透明、高效且易于使用。
参考资料
• [1] Linux Kernel Documentation: PCI Peer-to-Peer DMA Support( pci_p2pdma、ACS 路由假设、ZONE_DEVICE/MEMORY_DEVICE_PCI_P2PDMA、FOLL_PCI_P2PDMA等): docs.kernel.org• [2] NVIDIA GPUDirect Storage Overview Guide(GDS 架构、收益表述、 nvidia-fs.ko、gdscheck/gdsio、以及“在部分 NVMe 场景使用上游 PCI P2PDMA”说明): docs.nvidia.com• [3] Red Hat Enterprise Linux 9.2 Release Notes: pcie_bus_perf/pcie_bus_peer2peer等参数描述(含 MRRS/MPS 说明): docs.redhat.com• [4] NVIDIA NCCL Troubleshooting:ACS/VT-d/IOMMU 对 GPU Direct 的影响及排查建议: docs.nvidia.com
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python常见面试高频真题(附高清PDF)
- 【Python】挑战爬100个网站!今天实战目标网易云音乐评论采集!
- 零基础100天自学python,完整路线图
- Python从入门到精通的100个项目(附学习资料)
- 几个必不可少的 Linux 运维脚本!
- 一天一个Python知识点——Day 157:图像特征提取
- python爬虫入门之requests
- Day22:PDF处理神器!用Python合并/拆分/加水印,从此告别Adobe会员
- Python学习【127】:虚拟化平台让python开发者拥有“私有云”
- 从Windows到Linux:拆解Oracle单进程多线程(Windows)与多进程()的架构差异
